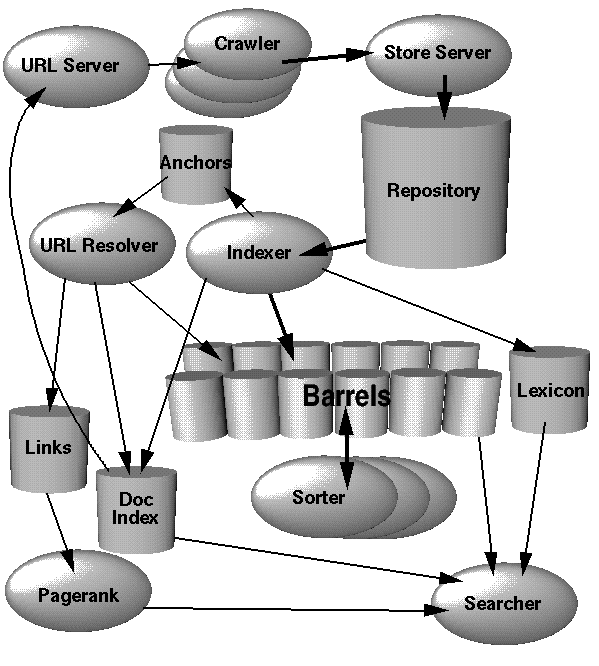
この記事は東京工業大学デジタル創作同好会traP アドベントカレンダー2019の38日目の記事です。
がちのサバをさばく予定だった人です。気が変わったので昨日のAdCをみて楽しみ~な人がいたらお詫び申し上げます。
突然ですが、検索エンジンに興味はありますか?僕は興味があります。検索欄位になんとなく欲しい情報について入力すると、まさにこれ!ってのがシュッとでてくる(?)のってなんかすごいですよね。そこで今回は誰にでもわかる検索エンジンのざっくりとした仕組みを自分のわかった範囲で説明しようかなと思います。間違いなどがあればご容赦ください。(注 ここでの検索はWebページを対象として、検索を実現するシステム全体のことを「検索エンジン」と勝手に言っています。また今回は機械型の検索エンジンについてのみ説明しています。基本的な情報は検索エンジンGoogleの発案に関する論文[1]に書いてあります。)
概要
コンピュータによる検索以前のメジャーな検索に関わるシステムといえば図書館の蔵書システムでしょう。昔は図書館での検索もコンピュータに頼らず行っていました(今も変わらずのところもある)。ざっくりいうと以下のことを行っています。
- 蔵書の本全ての情報を集める
- 図書目録を作る
- 利用者が図書目録を基に検索する(例えば日本十進分類法で整理された番号が返る)
ここで行なっていることを検索エンジンも行なっています。すなわち、
- 情報収集(クロール)
- 情報整理(索引付け)
- 情報検索(URLが返る)
です。
分類ごとに見ていきましょう。読むのがめんどければまとめにとんでもらっても結構です。
クロール
Webページを対象とするとき欲しい情報は、そのページのurlとページの内容でしょう。urlは簡単に言うとページのありかを示すわけですが、それを知らない限り、ページにアクセスできません。そこで行うのが、ページ内のリンクを順々に辿ってページを探していく方法です。そのようにしてクローラはページの内容を取得していきます。ページのありかがわかったらgetして内容を取得し、システム内のdbに格納します。
つまり、検索エンジンに自分のページが引っかかるにはクロールされることが必要です。しかし、コミュニティー内部でしか使わない情報だから、検索では引っかかって欲しくない(認証とか認可の話をしているのではない)こともあると思います。そこでサイトのルートディレクトリにrobots.txtというクローラに対してお願いを書くという仕組みがあります。Wikipediaの場合はhttps://ja.wikipedia.org/robots.txt です。
さて、そんなわけなので例えばWebページに更新があった時も検索システムで反映されるのはクロールされた後となります。しかし、じゃあ頻繁にクロールしようぜ!とは簡単に言えません。というのはwebページのあるサーバに対しページ内容を頂戴とお願いをしているということになるので、サーバが貧弱だったりgetによる頻度や処理が大きいと、サーバに負荷をかけ、人がアクセスできなくなってしまいます。したがってクローラは究極的にはウェブページごとに適切な頻度でクロールすることが求められます。なお、クロールにサーバが耐えられなかった例として岡崎市立中央図書館[2]の蔵書システムなどの事例があります。
索引付け
小さなまとまりに分割
極端なことをいうと索引付は不要です。なぜなら全てのページの全ての内容をゴリゴリゴリゴリチェックすれば良いだけです。でもそんなの時間がかかりすぎますよね。例えば欲しい単語に対し、それがあるwebページのurlがわかるだけでだいぶ楽になります(転置インデックスという)。
さて、ここで単語と言いました。そう、まず単語などの小さなまとまりに分割する必要があります。英語なら空白で分ければ良いですよね。日本語の場合、そのような目印はありません。文法の解析が必要です。よく使われる手法に形態素解析があります。形態素とは単語みたいなもの(厳密には違うらしい)と思っておいてください。例えば「お理工だけじゃダメなんだ。」を形態素分析で有名なMeCabを使って分析した結果が以下のような感じです。MeCabをブラウザで確かめられるところがないかなと思っていたらあったので[3]やってみました。どっちかというとこの仕組みの根幹は人の手によって作られたものなのでまあ今回は触れません。
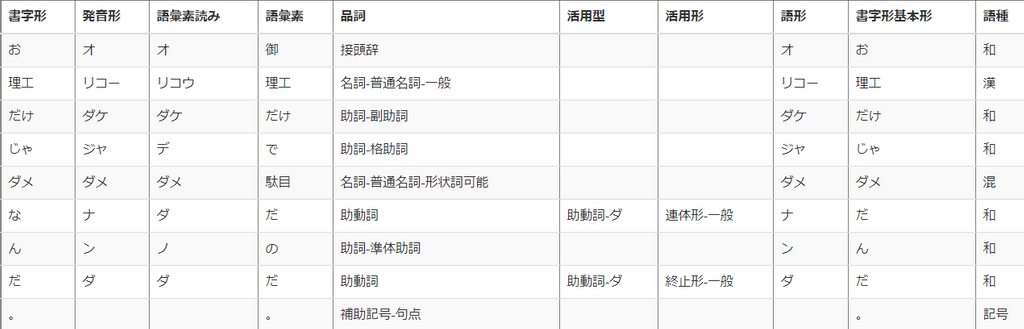
みてみると文法的な意味がわかるので助詞などの要素を抜いていい感じの単語リストが作れそうですね。それに活用がある言葉についても終止形?みたいな感じのものも分かっていい感じです。
インデックスの作成
続いて小さなまとまりから転置インデックスを作ります。ここで、転置インデックスの並べ方を二分探索が使えるようにある規則で並べるなどすればより効率が上がります。
検索
続いて検索を行います。検索ワードを含んでいるものを返すということはできそうですね。でも、Webページが膨大にある中、私たちは検索結果のせいぜい上位10個ぐらいしか見ません。つまり大切なのはどれくらい検索ワードと文書が近いか数値化することが必要です。アイデアの一つとして、例えば一つの単語につき一次元を表すなどして文書、検索ワードをベクトル表記する方法があります。そうすると検索ワードとの一致度合いを検索ワードと文書のベクトルのユークリッド距離や、ベクトルの角度(コサイン類似度)によって判定できそうです。
まとめ
以上のことを例を踏まえてやってみます。この世のwebページが以下の二つのみとします。大雑把なイメージなので細かいところは気にしないでください。
| URL | tex |
|---|---|
http://example1 |
中華人民共和国 http://example2 |
http://example2 |
人民の人民による人民のための政治 |
クローラがhttp://example1を知っているとします。
この時まずクローラによりexample1の情報がdbに突っ込まれ、example2の存在を知り、example2の情報もdbに突っ込まれます。要するに上の表が保存される感じです。次に形態素解析なども用いて転置インデックスを作成します。
| Word | URL 、回数 |
|---|---|
| 共和 | [{example1,1},{example2,0}] |
| 国 | [{example1,1},{example2,0}] |
| 人民 | [{example1,1},{example2,3}] |
| 政治 | [{example1,0},{example2,1}] |
| 中華 | [{example1,1},{example2,0}] |
こうやって見るとすべての文書は5次元ベクトルで表せそうですね。
では検索します。検索ワードを人民としてみます。この時、検索ワードは人民の次元のベクトル成分のみ0以外の値1を持ちます。今回はコサイン近似度で計算してみましょう。example1の文書ベクトルは(1,1,1,0,1)、example2の文書ベクトルは(0,0,3,1,0)、検索ワードの文書ベクトルは(0,0,1,0,0)であるので余弦はそれぞれ0.5,0.94...となり、example2を一番に返します。いい感じに思えますよね。逆に近さを数値化できない(二択でしか判定できない)と、example1もexample2も同様に扱われてしまいます。
ちょっとまった!
冒頭で言いましたよね...
検索欄位になんとなく欲しい情報について入力すると、まさにこれ!ってのがシュッとでてくる(?)のってなんかすごいですよね。
これまでのことでこんなことができるのか?
A. できません。
グーグルでは誤字や概念の勘違いをしていても欲しい情報へ誘導してくれます。検索の上のほうに出てくるのは割かししっかりしたつくりのサイトが多い印象がありますよね(ページの信頼度)。また、単語についても語順なども考慮に入れてくれるようになってきているそうです。だからまだ、賢いなぁ感は出ていませんし、この程度ならばいくらでも検索エンジンを欺くようなものが作れてしまいます。といえど、もう力尽きたのでこの辺は今回は言及しないで終わることにします。
明日12/8のブログリレー担当者はNABEさんです。お楽しみに~。
The Anatomy of a Large-Scale Hypertextual Web Search Engine。ちなみに一番上の画像はこの論文中の
Figure 1. High Level Google Architectureより引用させていただいています。 ↩︎蔵書更新を知るために作ったクローラでサーバがダウンしたため作成者が逮捕された。いろいろ思うことはあるが、詳しくは調べてほしい。 ↩︎
一橋大学国際教育センター 庵 功雄研究室 が公開している。http://www4414uj.sakura.ne.jp/Yasanichi1/unicheck/ ↩︎