
こんにちは、19のSysAd班の翠(sappi_red)です。普段はtraQのフロントエンドの保守を行ったりしています。
こんばんは、19のSysAd班のtemmaです。普段は普段どおりのことをしています。この記事の面白い部分はすべて僕が書いています。面白くないところは翠君が書いています。
この記事では、日々パフォーマンスに頭を悩ませる開発者の方のために、ワンタッチで劇遅SQLを200倍高速でキュートなSQLに劇的ビフォーアフターする方法を紹介します。
「おいおいおい、遅くしたくて記事を読み始めたのに話が違うじゃないか💢」と思ってるそこのあなた👈
早くできるということは遅くもできるんですね。
TL;DR
ここにテーブルがあります。
CREATE TABLE messages
(
id CHAR(36) NOT NULL PRIMARY KEY,
text TEXT COLLATE utf8mb4_bin NOT NULL,
created_at TIMESTAMP(6) NULL,
updated_at TIMESTAMP(6) NULL,
deleted_at TIMESTAMP(6) NULL,
) ENGINE = InnoDB;
今ならインデックスもついて、税込み3,800円!
CREATE INDEX `idx_messages_created_at` ON `messages` (`created_at`);
ここでクエリを見てみると?
↓ 遅い。 気難しい。寝不足。変な色してる。
SELECT * FROM `messages` WHERE `created_at` > '2022-05-15 12:34:56.1234567'
↓ 速い。 優しい。毎朝、ちゃんとごはん食べる。花の匂いがする。
SELECT * FROM `messages` WHERE `created_at` > '2022-05-15 12:34:56.123456'
【完】
以下ではtraQでの事例を紹介します。
※traQは部内向けコミュニケーションツールです。詳しい説明は以下の記事をご覧ください。
 spa
spa
traQのレスポンスが遅くなったぞい
traPでは、4/17~4/30の間を入部期間とし新入生の入部を受け付けていました。
ある日(4/22の16:30ごろ)、断続的にtraQのレスポンスがとても遅くなりました。(普段は50ms程度だったのが2200msかかったりしました。)
大変ですね。
この日は16時半過ぎから対面入部が行われており、数十人の新入生がtraQに新しく参加しています(ここ重要)。
軽く調査したところ、traQの置かれているサーバーに関してはCPU使用率などに異常はなく、代わりにDBの置かれているサーバーのCPU使用率が100%に張り付いていることとDBのThreads Runningが上がっていることが確認できました。
補足としてtraP SysAd班ではMariaDB 10.6.4を利用しています。
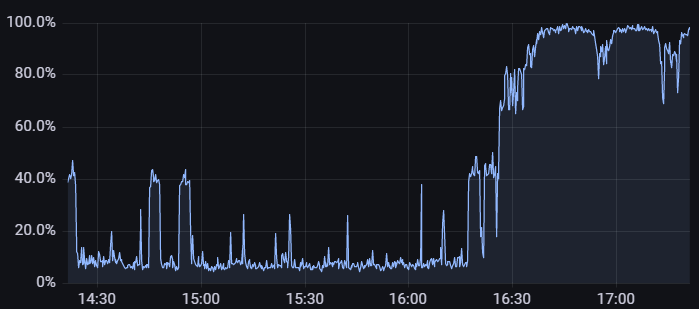
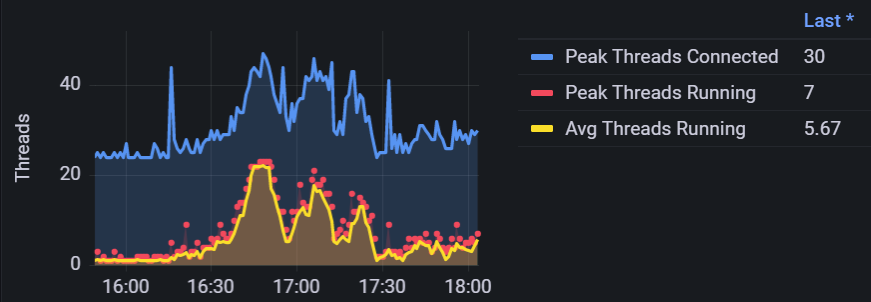
DBサーバーにはその他のサービスも接続していますが、traQの使用者数が増加しているという状況を踏まえ、traQから発行されるSQLクエリに遅いものが混じっていると考えました。
で、実際どーなのよ?
スロークエリログの出力を有効にしてませんでした(てへ)。仕方ないのでスロークエリログの出力設定をしつつ、原因を考えることにします。


💬「なるほどね!」
(ここで言及している問題については実は解決してたんだけど、対象のクエリが原因ってことまではあってたから、へーきへーき)
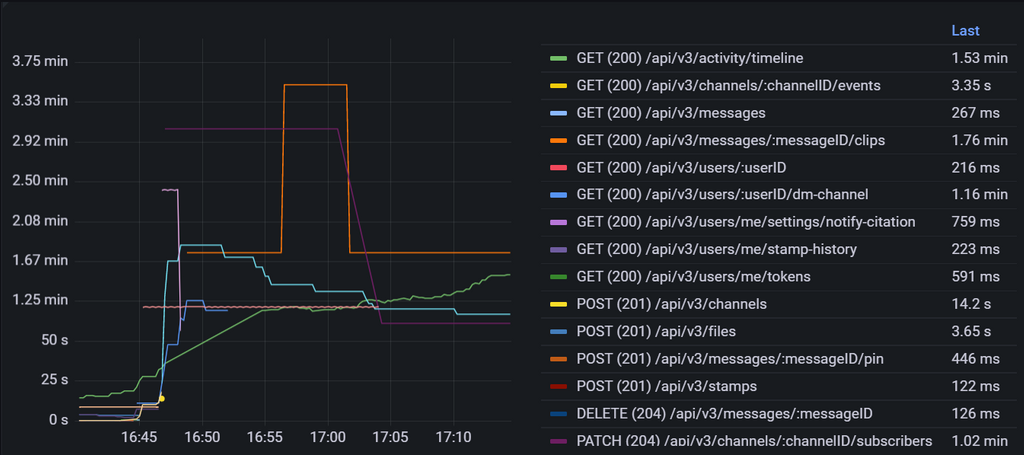
traQはエンドポイントごとのレスポンスタイムを計測しているので確認してみると、実際に/api/v3/activity/timeline(グラフの中央あたりの緑線)が遅くなっていることが分かります。
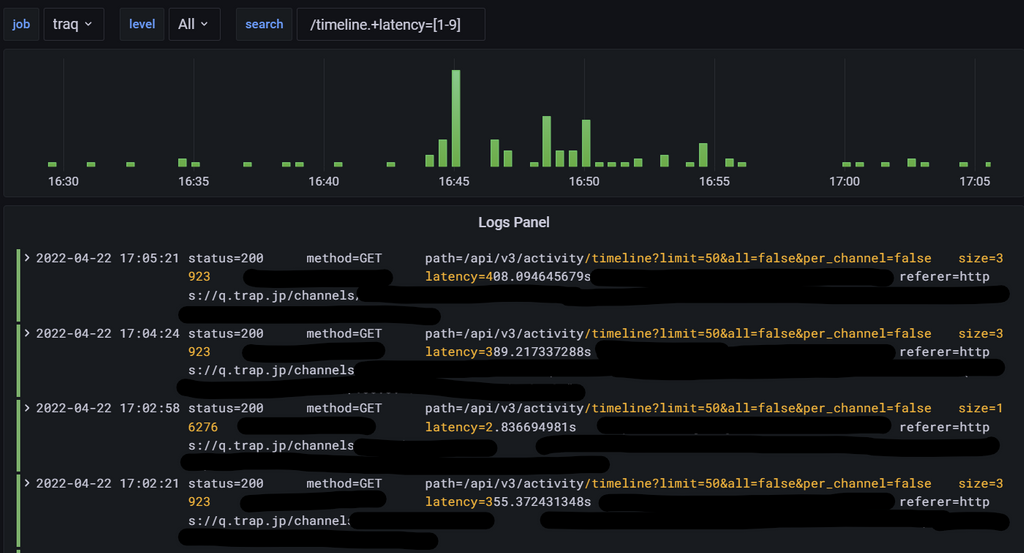
またLokiでログを見ても、レスポンスタイムが400sを超えるものが確認できます。
👮♂️「DBで詰まってるんだったら、どのエンドポイント見ても遅いのでは?」
🦊「結果的になんとかなったからいいじゃん!!」
/api/v3/activity/timelineについて
traQには全チャンネルあるいは購読しているチャンネルのメッセージのうち、最新の50件をチャンネル横断的に見ることができるアクティビティと呼ばれる機能があります。以下の画像の左側の部分です。
深堀る(FU KA BO RU)
🐶 「ここほれ、わんわん!」
原因だと予想していたクエリは「購読しているチャンネルの最新50件のメッセージを取得」するために使われるもので、具体的には以下のとおりです。(ちゃんと読んでね。)
SELECT
`messages`.`id`,
`messages`.`user_id`,
`messages`.`channel_id`,
`messages`.`text`,
`messages`.`created_at`,
`messages`.`updated_at`,
`messages`.`deleted_at`
FROM
`messages` USE INDEX (`idx_messages_deleted_at_created_at`) --- (deleted_at, created_at)のインデックス
INNER JOIN `channels` ON `messages`.`channel_id` = `channels`.`id`
WHERE
(
`channels`.`is_forced` = TRUE --- 強制通知チャンネルと呼ばれる常に購読されるチャンネル
OR `channels`.`id` IN (
SELECT
`s`.`channel_id`
FROM
`users_subscribe_channels` `s`
WHERE
`s`.`user_id` = '_____USER_ID_____'
) --- そのユーザーが購読しているチャンネル一覧
)
AND `messages`.`created_at` > '_____現在時刻の7日前_____' --- 古いメッセージまでスキャンされるとパフォーマンスが悪くなるため絞る
AND `channels`.`is_public` = true --- DMを除く
AND `messages`.`deleted_at` IS NULL
ORDER BY
`messages`.`created_at` DESC
LIMIT
51
(嘘だよ。そんなにちゃんと読まなくてもいいよ。)
いくつか言及しておくと、対象期間を7日間に絞り込むことでこのクエリのパフォーマンスが改善されることは確認済みで、USE INDEXに関しても効果があることを確認してます。
余談ですが、購読しているチャンネルのみではなく全チャンネルでのアクティビティの場合は、USE INDEXなしのクエリが発行されるようになっており、(channel_id, deleted_at, created_at)のインデックスが使われます。
しかし、ログに出力されたユーザーのuser_idを使って上記のクエリを叩いても再現できず、レスポンスはすぐに返ってきます。何人かで試してみても同じでした。
この時、_____現在時刻の7日前_____には2022-04-17や2022-04-17 11:13:20.081を利用していました。
🕺 ここで皆さんお待ちかね、スロークエリログのご登場です!!
🧐 ふむふむ?彼が言うには、このクエリが原因であることは間違いないようです。
再現できないので不思議に思っていたわけですが、スロークエリログに出力されたクエリをコピーして実行したところ再現できました。違いを確認してみましょう。

どうやら_____現在時刻の7日前_____に2022-04-17 11:13:20.388513907のようなナノ秒精度の値を使用すると再現するようです。
ナノ秒精度
、お前だったのか。いつもクエリを遅くしてくれていたのは。
マイクロ秒精度で指定したクエリのANALYZE結果
ANALYZE FORMAT=JSON SELECT * FROM `messages` WHERE `created_at` > '2022-04-17 00:00:00.123456' LIMIT 1;
{
"query_block": {
"select_id": 1,
"r_loops": 1,
"r_total_time_ms": 0.931062234,
"table": {
"table_name": "messages",
"access_type": "range",
"possible_keys": [
"idx_messages_created_at"
],
"key": "idx_messages_created_at", ← 偉い
"key_length": "8",
"used_key_parts": [
"created_at"
],
"r_loops": 1,
"rows": 50408,
"r_rows": 1,
"r_table_time_ms": 0.899001226,
"r_other_time_ms": 0.02017687,
"filtered": 100,
"r_filtered": 100,
"index_condition": "messages.created_at > '2022-04-17 00:00:00.123456'"
}
}
}
ナノ秒精度で指定したクエリのANALYZE結果
ANALYZE FORMAT=JSON SELECT * FROM `messages` WHERE `created_at` > '2022-04-17 00:00:00.123456789' LIMIT 1;
{
"query_block": {
"select_id": 1,
"r_loops": 1,
"r_total_time_ms": 0.145948996, ← 早いのは LIMIT 1 だから
"table": {
"table_name": "messages",
"access_type": "ALL",
"possible_keys": [
"idx_messages_created_at"
],
← key ないなった
"r_loops": 1,
"rows": 1770761,
"r_rows": 40,
"r_table_time_ms": 0.090800227,
"r_other_time_ms": 0.040949911,
"filtered": 100,
"r_filtered": 2.5,
"attached_condition": "messages.created_at > '2022-04-17 00:00:00.123456789'"
}
}
}
ここでは、ナノ秒で行っていますが、実際にはマイクロ秒に一桁追加しただけでも、ナノ秒と同じ結果が得られます。
スッと分かったように見えますが、もともとのクエリにORDER BYが使われてるのをそのまま残して検証したりすると、(WHEREには使われないものの)ORDER BYにインデックスを使われるため、WHEREにインデックスが使われているように見え、かなり分かりにくかったです。
ANALYZE FORMAT=JSON SELECT * FROM `messages` WHERE `created_at` > '2022-04-17 00:00:00.123456789' ORDER BY `created_at` LIMIT 1;
{
"query_block": {
"select_id": 1,
"r_loops": 1,
"r_total_time_ms": 236920.611, ← 遅い(下のより400万倍遅い)
"table": {
"table_name": "messages",
"access_type": "index",
"possible_keys": [
"idx_messages_created_at"
],
"key": "idx_messages_created_at", ← 偉い(ように見えるが遅い)
"key_length": "8",
"used_key_parts": [
"created_at"
],
"r_loops": 1,
"rows": 1769333,
"r_rows": 2182038,
"r_table_time_ms": 234829.0258,
"r_other_time_ms": 2091.581307,
"filtered": 100,
"r_filtered": 0.00004582872,
"attached_condition": "messages.created_at > '2022-04-17 00:00:00.123456789'"
}
}
}
参考までにマイクロ秒精度だと以下のようになります。(改善後の本番と近い)
ANALYZE FORMAT=JSON SELECT * FROM `messages` WHERE `created_at` > '2022-04-17 00:00:00.123456' ORDER BY `created_at` LIMIT 1;
{
"query_block": {
"select_id": 1,
"r_loops": 1,
"r_total_time_ms": 0.059567057, ← 早い
"table": {
"table_name": "messages",
"access_type": "range",
"possible_keys": [
"idx_messages_created_at"
],
"key": "idx_messages_created_at", ← 偉い
"key_length": "8",
"used_key_parts": [
"created_at"
],
"r_loops": 1,
"rows": 151254,
"r_rows": 1,
"r_table_time_ms": 0.038527318,
"r_other_time_ms": 0.008756296,
"filtered": 100,
"r_filtered": 100,
"index_condition": "messages.created_at > '2022-04-17 00:00:00.123456'"
}
}
}
結論としては、マイクロ秒を超える精度の値を渡すと、Truncateが発生しインデックスが使われなくなるようです。
この時、Noteとして以下のような出力が得られています。
Note #1292 - Truncated incorrect date value: '2022-04-17 00:00:00.123456789'
Truncateが必要十分な条件なのか分からなかったのと、もしそうならNoteではなくWarningを出して欲しいと言う思いがあったのでMariaDBのバグトラッカーに質問として投げておきました。(MDEV-28408)
なにか知見のある方がいらっしゃいましたら、教えていただけると幸いです。
traQでの修正
traQ側でマイクロ秒に丸めて送信するようにしました。その後、パフォーマンスの低下は発生していません。
どうしてこれまで起こらなかったのか
以前はgo-sql-driver/mysqlでマイクロ秒に丸められてクエリが発行されていましたが、DB側でも丸め操作が行われることを理由に、2021/04/01にリリースされたv1.6.0で丸めこみをなくす変更が入ったため、顕在化したようです。
どうやら同じ現象にハマった人も居たようです。
まとめ
(少なくともMariaDBでは)TIMESTAMP(6)型のカラムに対してWHEREでマイクロ秒を超える精度の絞り込みをかけるとインデックスが使われなくなります(たぶん)。
「割とコーナーケース && 元のクエリが複雑」で気づくのが難しかったです。ただ、見つけられたときには達成感を得られました。
また、@toki, @sappi_red, @logica, @hijiki51, @temmaで調査していましたが、各々が互いに異なるところに気づいていて、三人寄れば文殊の知恵を感じました。