この記事は新歓ブログリレー2022 22日目の記事です。
挨拶
こんにちは。21Bのゆゆです。traPでは競プロerとしてがんばっています。大学生になって初めてプログラミングを始めました。 大学生になって最初のあたりは結構サボっていたので現在も弱く、後悔しているのでみなさんはこうならないようにしましょう。
導入
さて、この記事では早稲田大学の理系を受験した方なら一度は目にしたことがある、あの問題を扱います。
そうあれです。
For questions 1 – 15, two definitions are given with one sample sentence each. Think of a word that matches both definitions and also fits in the blanks in both sentences. Convert each letter of the word into a number 1 to 4 according to the table below; number 1 represents letter a - g, 2 represents h – m, 3 represents n – s, and 4 represents t - z. Then choose the matching sequence of numbers from options a – d. For example, if the word you think of is wise, for which the first letter w is given, the remaining letters would be changed into 2 for i, 3 for s, and 1 for e. Hence, the correct answer would be w231.
Number Letters 1 a, b, c, d, e, f, g 2 h, i, j, k, l, m 3 n, o, p, q, r, s 4 t, u, v, w, x, y, z
要約すると、「二つの定義とその例文を与えるので、それに当てはまるのを選べ。選択肢は最初の文字以外、上の変換表によって変換されている。(例 wiseならばw231)」といった感じです。
Twitter見てたら選択肢のように変換される英単語を列挙してる人がいて、面白いなーと思ったので、じゃあ問題を自動生成できるやつを作ってみるかとなりました。
今回は、単語の集合をプログラムに与えたら、その中からランダムに選んで問題を出すと言う感じにします。全ての英単語からの出題だと、解くのが流石に難しすぎるので単語は手動で選別していきます。
例文は自然言語に関するライブラリ nltk のwordnetを使ってなんやかんやします。後で詳細を説明します。
手順の説明
今回手動でやるのは単語の追加のみにします。
問題を自動生成するにあたって、用意した単語群からランダムに選び出してその単語が答えとなるようにします。
nltkのwordnetというのは単語の意味に沿って構成される木で同義語が同じ階層にあり、上位概念(車に対する乗り物)などが上の階層にあります。逆に下位概念(車に対するトラック)が下の階層にあります。
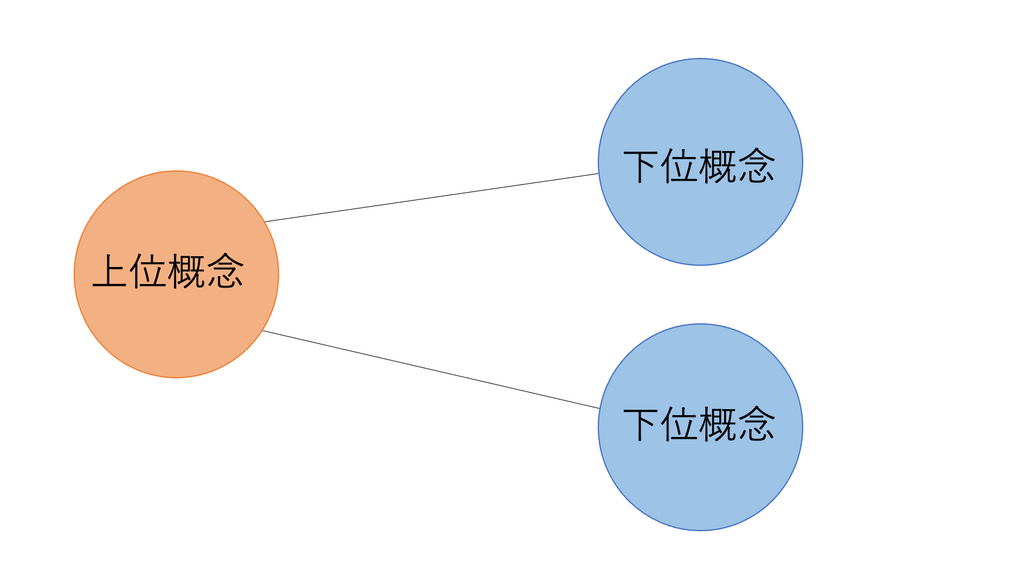
このwordnetを使って英単語の例文と定義を引っ張り出していこうと思います。nltkの詳しい使い方はここに書いてあります。
from nltk.corpus import wordnet as wn
このコードを最初に実行しwordnetを使えるようにします。nltkは外部ライブラリなので使うには端末にダウンロードする必要がありますのでnltkで遊びたい方はご自身の端末にダウンロードしてください。ここではwornetをwnと略します。
さて今回使うのはwordnetの内3つの機能だけです。
まず一つ目はこれです。
wn.synsets('任意の英単語')
任意の英単語のそれ自身を含む同義語のsynsets型のリストを返します。wn.synsets('dog')を実行すると、返り値は[Synsets('dog.n.01'), Synsets('frump.n.01'),...(以下略)]といった感じで返します。dogやfrumpの後ろについているnは名詞を表しています。動詞の場合はvになるというように品詞がつきます。その後ろの数字は同じ品詞でも意味が違うものを区別するためについています。
このsynsets型を使うことで今回は例文や言葉の定義を引き出すことができます。
(任意の英単語のsynsets型).difinition()
このコードによって英単語の定義を引き出してくれます。実際にwn.synsets('dog')[0].definition()を実行すると
'a member of the genus Canis (probably descended from the common wolf) that has been domesticated by man since prehistoric times; occurs in many breed
有史以前から人間に家畜化されてきたイヌ属の一種(おそらく一般的なオオカミの子孫;多くの品種が存在する」
というように定義を出してくれます。wn.synsets('dog')[0]は先ほど見たように Synsets('dog.n.01')なので、それに対応する定義を出してくれたということです。
次に例文を引き出します。
(任意の英単語のsynsets型).examples()
を実行するとその単語の例文(文字列型)をリストで返してくれます。
この例文が複数ある時もあれば、存在しないこともあるらしく完成した後に遊んでたら気づきました(一敗)。そのような単語が選ばれてしまった暁には、運ゲーが始まってしまうのでがんばってください。
用意した単語リストから単語を抽選して、wn.synsets('選ばれた単語')を実行し、その中に混じってる、選ばれた単語以外のsynsets型をふるい落とします。残ったやつで、定義と例文を呼び出してその定義と例文の文中にある選ばれた単語を()に置き換えます。
選択肢は存在する単語から2つランダムに1つ生成して、早稲田方式(上の表を参照)に変換して、問題を出します。
コード
word_use.pyというpythonファイルが以下に示すコードが書かれたpythonのファイルと同じフォルダに入っています。word_use.pyは
word_use = [['apple',...],['bag', ...], ...]
というように単語しか入ってない上に長いのでここでは省略します。
# coding: utf-8
from nltk.corpus import wordnet as wn
#同じ階層にあるword_use.pyをimport
from word_use import word_use
import numpy as np
class Waseda:
def __init__(self):
#word_useは先頭のアルファベットによって振り分けている二重のリスト
#24以下の数字をランダムに選択
#xから始まる英単語で高校以前で学ぶものがなさそうなので省きました
#xから始まる英単語を入れる場合は25を26にして、
#word_useにxからはじまる英単語のリストを入れてください
rand = np.random.randint(25)
rand2 = np.random.randint(len(word_use[rand]))
#答え
self.ans = word_use[rand][rand2]
rand3 = np.random.randint(len(word_use[rand]))
rand4 = np.random.randint(len(word_use[rand]))
#選択肢を存在する単語から2つ生成
self.dummy = word_use[rand][rand3]
self.dummy2 = word_use[rand][rand4]
#選択肢
self.choices = []
#例文を入れる
self.examples= []
synsets = wn.synsets(self.ans)
#選んだ単語の定義と例文を呼び出して追加
for i in range(len(synsets)):
if self.ans in str(synsets[i]):
#teachの例文でtaughtが入ってたりすると問題としてふさわしくないし面倒なのでそういうのは切り捨てる
ok = False
for j in range(len(synsets[i].examples())):
if ok: break
if self.ans in synsets[i].examples()[j]:
exam = synsets[i].definition()
exam += '; '
exam += synsets[i].examples()[j]
self.examples.append(exam)
ok = True
#例文が複数ある場合、毎回固定だとつまらないのでシャッフルしておく
np.random.shuffle(self.examples)
#例文がひとつもなかった時用に定義だけ追加
for i in range(len(synsets)):
if self.ans in str(synsets[i]):
if len(self.examples) == 0:
self.examples.append(synsets[i].definition())
#本家は2個なので2個以上ある場合は2個になるまで削除
while len(self.examples) > 2:
self.examples.pop()
#早稲田方式に単語を変換
def convert_waseda(self, s):
one = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
two = ['h', 'i', 'j', 'k', 'l', 'm']
three = ['n', 'o', 'p','q', 'r', 's']
four = ['t', 'u', 'v', 'w', 'x', 'y', 'z']
conv = ""
conv += s[0]
for i in range(1,len(s)):
if s[i] in one:
conv += '1'
elif s[i] in two:
conv += '2'
elif s[i] in three:
conv += '3'
elif s[i] in four:
conv += '4'
if not conv in self.choices:
self.choices.append(conv)
#もし選択肢に同一のがあればランダムに生成
else:
self.random_choice()
return conv
def random_choice(self):
rand_choice = self.ans[0]
#長さが短すぎると嘘がわかるので最低4文字以上にする
rand_num1 = np.random.randint(3,8)
for i in range(rand_num1):
rand_choice += str(np.random.randint(4)+1)
#重複がなければ追加あればもう一回呼ぶ(確率的には何回も完全一致はしないはずなので)
if not rand_choice in self.choices:
self.choices.append(rand_choice)
else :
self.random_choice()
def solve(self):
print("The correct answer is {}.".format(self.ans))
def problem(self):
#例文の中にある正解の単語を( )で置き換える
for i in range(len(self.examples)):
tmp = '{}. {}.'.format(i+1, self.examples[i].replace(self.ans, '( )'))
print(tmp)
#答えが早稲田方式に変換されたのを持っておく
ans_converted = self.convert_waseda(self.ans)
self.convert_waseda(self.dummy)
self.convert_waseda(self.dummy2)
self.random_choice()
np.random.shuffle(self.choices)
#print()で改行する蛮行をする
print()
print()
for i in range(len(self.choices)):
print('{}. {}'.format(i+1, self.choices[i]))
ok = True
while ok:
print('\nChoose answer: ')
#例外処理
try:
kaitou = int(input())
except KeyboardInterrupt:
return
except:
print('Invalid input. Try again.')
continue
#1,2,3,4以外の数字が選ばれた際もう一回入力させる
if kaitou <= 0 or kaitou > 4:
print('Invalid input. Try again.')
continue
kaitou -= 1
if ans_converted == self.choices[kaitou]:
print('Your answer is collect!!')
self.solve()
ok = False
else:
print('Your answer is wrong')
print('Do you continue ? please answer yes or no.')
cont = str(input())
if cont == "YES" or cont == "Yes" or cont == "yes" or cont == "y" or cont == "Y":
continue
#yes以外では終了
else:
ok = False
#答えを見せる
self.solve()
a = Waseda()
a.problem()
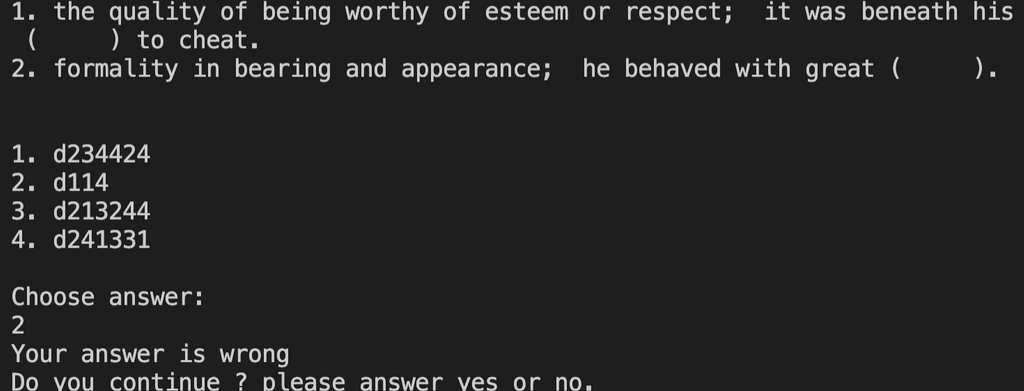
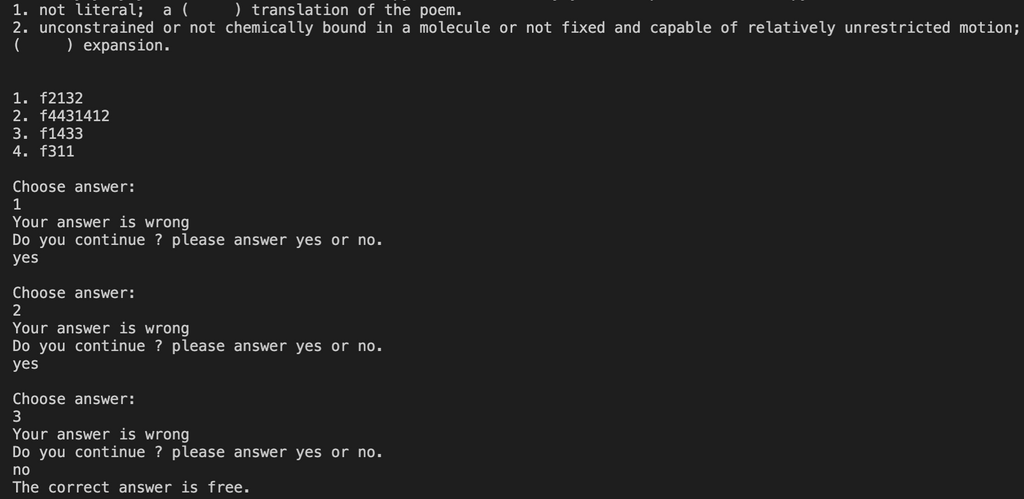
実行するとこのような感じで出題がされます。
単語は鉄壁英単語から適当に選んでいます。
一応Githubにもあげておきます。リンクはこちら
問題点
例文が存在しない単語があると、定義だけで問題が出されてしまいます。どうやら定義すら空の単語も存在する模様です。しかもそういった単語がかなり多そうだことを実装した後に試していて知りました。また、例文が1つしかない場合とかもあるようで、ハードモードになる可能性があります。多分、不規則変化する動詞や名刺の複数形の不規則変化するような単語で挙動がおかしくなりそうな予感がしています。(面倒なので試していません。)
割とwordnetの方の問題で期待通りに動作しなさそうな単語が多くて想定通りに動く単語の方が少なそうです。カスコードを書いてしまったかもしれません。
簡単めの単語ではそういったことは起こりにくいようです。
終わりの一言
こんな感じで私の記事は終わりです。traPのalgorithm班では 定期的に[1]ABC解説会をしています。現在新歓の時期なので限定公開のリンクで解説会の様子をYoutubeLiveで流しています。今日もやる予定です。私も解説の一部を担当しているのでこれを見てる競プロerおよび、競プロに興味がある人は是非見に来てください!!!
明日の記事は @liquid1224 さんです。お楽しみに〜!!
聞きたい人、解説したい人がほぼおらず、開催されない時期があったので、不定期かもしれません。諸説あり。 ↩︎