
注意
本記事内で紹介されているゲームには暴力的、残酷的シーン、犯罪にあたる行為等、過激な表現が含まれています。気分を害するおそれがありますのでご注意ください。(本記事自体に18歳未満の方は閲覧できないコンテンツは直接的には含まれていません)
ENTER
この記事はtraP夏のブログリレー8月30日の記事、及びtraP Hgame班ブログリレー5日目の記事です。
こんにちは。@d_etteiu8383です。8月も残すところ2日間となりましたが、皆さんは夏休みの宿題はもう終わらせましたか?大学生にとってはもはや懐かしい概念ですが、せっかくの夏休みですし何か面白いことをやりたいと思い、今回のブログのネタとして夏休みの自由研究を行いました。テーマはドーナドーナと画像処理です。一部実績に関するネタバレを含むので注意!
ドーナドーナニ"楽に"イレタイ
3年7組 でっていう
2021年 8月 30日
研究の動機
Hgame班ブログリレーに参加することになったが特に書く内容が見つからず(そしてそもそもあまりHgameをプレイしたことが無く)、困っていたところ、私が所持している数少ないHgameの一つである"ドーナドーナ"の存在を思い出した。既に全ルートクリア済みではあるが、久しぶりにプレイしようと思い起動したところ、まだ実績のコンプリートができていないことに気付いた。本記事では、実績コンプリートを目指す過程で行った自動化処理についてまとめる。その前に、いくつか前提として知っておかなければならない知識があるため、以下で説明する。
ドーナドーナとは
ドーナドーナとは、アリスソフトから発売されているHgameである。
ドーナドーナ いっしょにわるいことをしよう | アリスソフト
瀬戸内海に面した企業城下町『亜総義市』
ここに住む市民らは一企業にすべてを制御される生活を送っているが、不満も疑問も抱く事はなく、与えられる平和を享受していた。
しかしこの高潔な街にも『抗亜』そう呼ばれる不穏分子は存在し、武器を手にヒトやモノを奪う『ヒトカリ』、身体で資金を稼がせる『ハルウリ』など、秩序を否定する行為を繰り返していた。
勢いを増す抗亜、存在抹消を図る企業、
やがて来る『生誕祭』。
全てを喰らいながら、街は大きく動き始める
(公式サイトより)
そのストーリーや登場キャラクターについては実際にゲームをプレイして確認していただきたい。本ゲームは「ヒトカリ」と「ハルウリ」の2パートで構成されている。
- ヒトカリ:女の子を捕まえたりアイテムを見つけたりする戦闘パート
- ハルウリ:捕まえた女の子に身体を使って資金を稼いでもらう運営パート

つまりハルウリで資金を稼いでキャラクターのパワーアップやアイテムの購入を行い、ヒトカリでダンジョン攻略を進めるといったゲームになっている。"捕まえた女の子"はゲーム内で"ジンザイ"と呼ばれ、ハルウリの相手は"コキャク"と呼ばれている。ジンザイには"ルックス"、"テクニック"、"メンタル"の3つのステータスと、「えっち」「優等生」「委員長」「クール」などの属性が設定されている。これらステータスと属性はハルウリ時の稼ぎ等に関係するため、いかにステータスの高いジンザイを獲得できるかが重要になってくる。
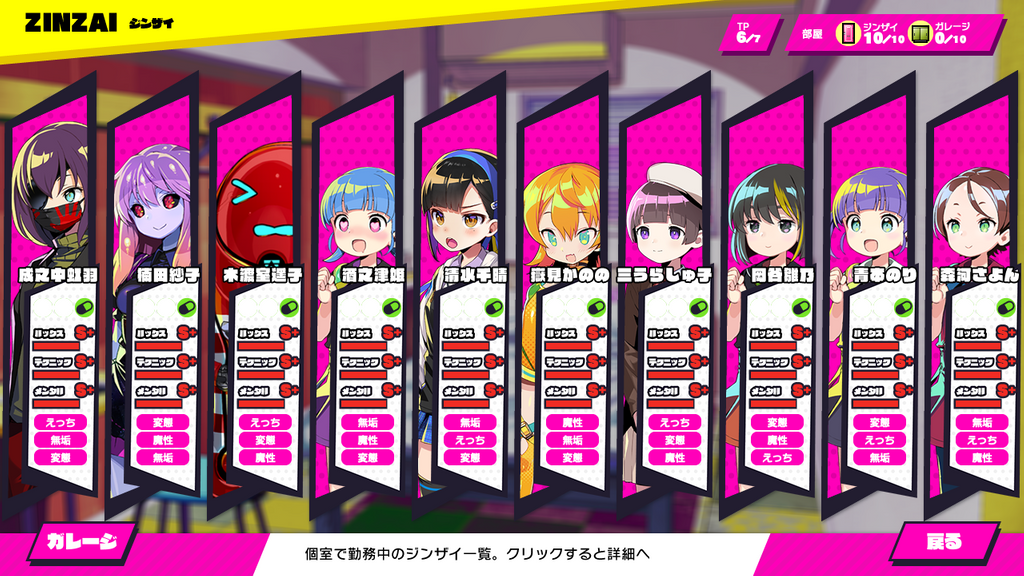
オリジナルジンザイ/コキャク
ドーナドーナにはおまけとしてオリジナルのジンザイとコキャクをゲーム内に登場させる機能が存在する。
参考:ドーナドーナ公式ブログ【おまけ機能】 | アリスソフト 公式サイト
画像ファイルと設定テキスト(ジンザイのステータスや属性、音声等を設定する)を用意するだけで、オリジナルのジンザイを作成することができる。
例えば下図のような画像素材(ドーナドーナに登場するモブジンザイの画像から改変して作成した)と、

以下のような設定ファイルを用意すると...
画像=zinzai_loliko.png
名前=東工子
ルックス=S+
テクニック=D
メンタル=S+
属性=有名人
属性=心の闇
属性=貧乳
処女=1
音声=女子汎用/小/勝ち気
プロフィール=ほんみょうは「あずまのりこ」
プロフィール=でもみんなロリ子ってよんでくるの...
プロフィール=えっちなのはだめなんだからね!
以下のように、ゲーム内にオリジナルのジンザイが登場するようになる。

この機能により、2週目以降のゲームプレイでは自分の好きなキャラクターを登場させる...といった楽しみ方が可能である。
実績
本ゲームには実績が用意されている。アイテムの購入回数やハルウリでの稼ぎ、敵の撃破回数等の達成項目があり、実績の獲得数に応じてお楽しみ要素が解放されたりする。
本研究の目的
上で説明した実績の中に、「レアドロップ・技」「レアドロップ・心」という実績が用意されている。これはそれぞれ、「テクニックS+のジンザイをドナドナする」「メンタルS+のジンザイをドナドナする」ことで獲得することが可能であるが、ステータスが最高の状態で登場するジンザイは極めて珍しいため、この実績の獲得も難しいものになっている。ひたすらヒトカリを繰り返すことでもいつかは達成できるが、今回は「テクニック/メンタルがS+の自作ジンザイを大量に用意する」ことでの達成を試みた。
しかしこれには
- 自作ジンザイに使用する大量の画像を用意する
- 自作ジンザイの設定テキストファイルを大量に用意する
という二つの作業が必要となるため、手作業で行っていては時間がかかってしまう。そこで、これら2つの作業をPythonを利用することで自動化しようと試みた。
方法
本ブログで紹介しているコードは Python 3.8.10 での動作を確認している。
画像の用意
まず、ジンザイに使用する画像を大量に用意する方法を考える。ブランク画像を使ったり、一種類の画像から大量のジンザイを作成することも可能だが、それでは面白くないし、プレイしていて楽しくないので、種々のキャラクターイラストを集める方法を考える。今回は「Last Origin」というソーシャルゲームの日本版Wikiから、キャラクター画像を拝借することにした。
Last Originのキャラクター画像を選んだ理由は2つある。
まず、ソーシャルゲームのキャラクターイラストはジンザイの画像に向いているからだ。「攻略サイト等でキャラクター画像がまとめられている」「人の全身が描かれている」ことが多いため、収集がしやすく、実際のゲーム内での見栄えも優れている。ただしこれは、他のソーシャルゲームにも言える利点である。
Last Originを選んだ最大の理由はメカイラストがかっこいいからである。




ドーナドーナはそのストーリー上、ロボットやメカが敵として登場することが多いためメカ繋がりでLast Originを選んだだけであって、「カリスタがかわいい」とか「エンプレスの服装がすごい」とか「エタニティのメイド服が良い」とか「ポイの水着スキンがヤバい」とか、そういう邪な理由で選んだわけではない。DMM版の事前登録も始まって楽しみだからとか、そういう理由ではない。
とにかく今回はLast Originのイラストを利用する。
画像の収集
Last OriginのWikiからの画像の収集のため、スクレイピングを行う。
ウェブスクレイピング(英: Web scraping)とは、ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。
(出典:ウェブスクレイピング - Wikipedia)
スクレイピングの技術を利用することで、簡単にweb上のデータを取得することができる。その一方で、法律上の注意事項が有ったり、Webサイトがスクレイピングを禁止している場合も少なくないので、よく調べてから実践するように注意する必要がある。今回利用させていただいたWikiはSeesaaのレンタルwikiを利用して作成されたものであり、Seesaa Wikiガイドラインには禁止事項として
弊社の設置するサーバなどに過負荷を与えるプログラムなどの設置および行為
が挙げられており、スクレイピングをする場合は数秒の間隔をあけてアクセスをするようにしなければならない(禁止されてなくても数秒は間隔をあけるべき)。
今回はバイオロイド一覧 - Last Origin (ラストオリジン) 日本版攻略wikiから各バイオロイドの詳細ページURLを取得し、各詳細ページ中の画像をダウンロードする。
コードの全文は以下の通りである。
import requests
import re
import io
import os
import time
from bs4 import BeautifulSoup
from PIL import Image
def img_save(url, file_name):
"""Save an image from a URL
Args:
URL (str): Image URL.
file_name (str): Destination path.
"""
image = Image.open(io.BytesIO(requests.get(url).content))
fmt = image.format
if fmt == "PNG":
file_name += ".png"
elif fmt == "JPEG":
file_name += ".jpg"
else:
file_name += ".png"
print(f"The format wasn't PNG or JPEG.({url})")
image.save(file_name)
print("saved " + file_name)
def safe_filename(name):
return re.sub(r'[\\/:?."<>\|\s]', '_', name)
def main():
# ダウンロード画像の保存先フォルダを作成
save_dir = "download"
try:
os.mkdir(save_dir)
except FileExistsError:
pass
# キャラ一覧ページの取得
base_url = "https://seesaawiki.jp/lastorigin/d/%a5%d0%a5%a4%a5%aa%a5%ed%a5%a4%a5%c9%b0%ec%cd%f7"
base_html = requests.get(base_url)
base_soup = BeautifulSoup(base_html.content, "html.parser")
# キャラ名一覧のtableを取得
chara_table = base_soup.find("table", class_="sort")
chara_list = [tr.find_all("td")[2].a for tr in chara_table.tbody]
for chara_index, chara_anchor in enumerate(chara_list):
# キャラ名の取得
chara_name = safe_filename(chara_anchor.text)
print(chara_name)
# 各キャラページからスキン画像のURLを取得する
chara_html = requests.get(chara_anchor["href"])
chara_soup = BeautifulSoup(chara_html.content, "html.parser")
skin_image_urls = [img["src"]
for img in chara_soup.find_all("img", width="400")]
for skin_index, skin_image_url in enumerate(skin_image_urls):
print(" ", end="")
try:
img_save(skin_image_url,
f"{save_dir}/{chara_index:03}_{skin_index:02}")
except:
print(f"Failed to save the image. <{skin_image_url}>")
# ちょっと待つ
time.sleep(20.0)
if __name__ == '__main__':
main()
まずキャラクター一覧ページのHTMLをrequests.get()を利用して取得し、その中身をBeautiful Soupを利用して解析している。BeautifulSoup(base_html.content, "html.parser")のようにHTMLを渡すと、その内容をパースし、扱いやすいデータ構造に変換してくれる。
.find()により条件に合った要素を抽出、.find_all()により条件に合ったすべての要素を配列として抽出することができるため、これを用いて各キャラクターの詳細ページのリンクを配列に格納している。Beautiful Soupのより詳しい使い方については、ドキュメントを参照して欲しい。
各キャラクターの詳細ページも同様にrequests.get()を用いてHTMLを取得し、Beautiful Soupで目的の画像のURLを取得している。得られたURLからまたrequests.get()を用いて画像データを取得し、画像として保存している。
これにより、キャラクターの画像288枚を収集することができた。
画像サイズの調整
次に、ダウンロードした画像のサイズ調整を行う。今回ダウロードした各画像はサイズが揃っていなかったが、ドーナドーナの自作ジンザイに使用する画像は1024px*1024pxの大きさにする必要があるため、リサイズ処理を行う。以下に、画像を指定サイズにリサイズする関数を示す。
import math
import cv2
import numpy as np
def resize_square(img, size):
"""Resize the image to a square shape.
Args:
img (ndarray): input image.
size (int): size of output(px).
Returns:
ndarray: resized image.
"""
height, width = img.shape[:2]
scale = size / max(width, height)
target_width = math.floor(width * scale)
target_height = math.floor(height * scale)
if scale > 1:
interpolation = cv2.INTER_LINEAR
else:
interpolation = cv2.INTER_AREA
resized_image = cv2.resize(
img, (target_width, target_height), interpolation=interpolation)
zeros = np.zeros((size, size), dtype='uint8')
channel = len(img.shape)
if channel == 2:
# 入力画像がグレースケールの時
dst = cv2.merge([zeros])
else:
is_alpha = img.shape[2] == 4
if is_alpha:
# 入力画像がアルファチャンネルを持つカラー画像の時
dst = cv2.merge([zeros, zeros, zeros, zeros])
else:
# 入力画像がアルファチャンネルを持たないカラー画像の時
dst = cv2.merge([zeros, zeros, zeros])
x_offset = size // 2 - target_width//2
y_offset = size // 2 - target_height//2
dst[y_offset:y_offset+target_height,
x_offset:x_offset+target_width] = resized_image
return dst
入力画像の最長の辺が指定サイズに収まるように拡縮し、正方形の中心に来るように位置を調整している。(参考:画像の幾何学変換 — opencv 2.2 documentation)
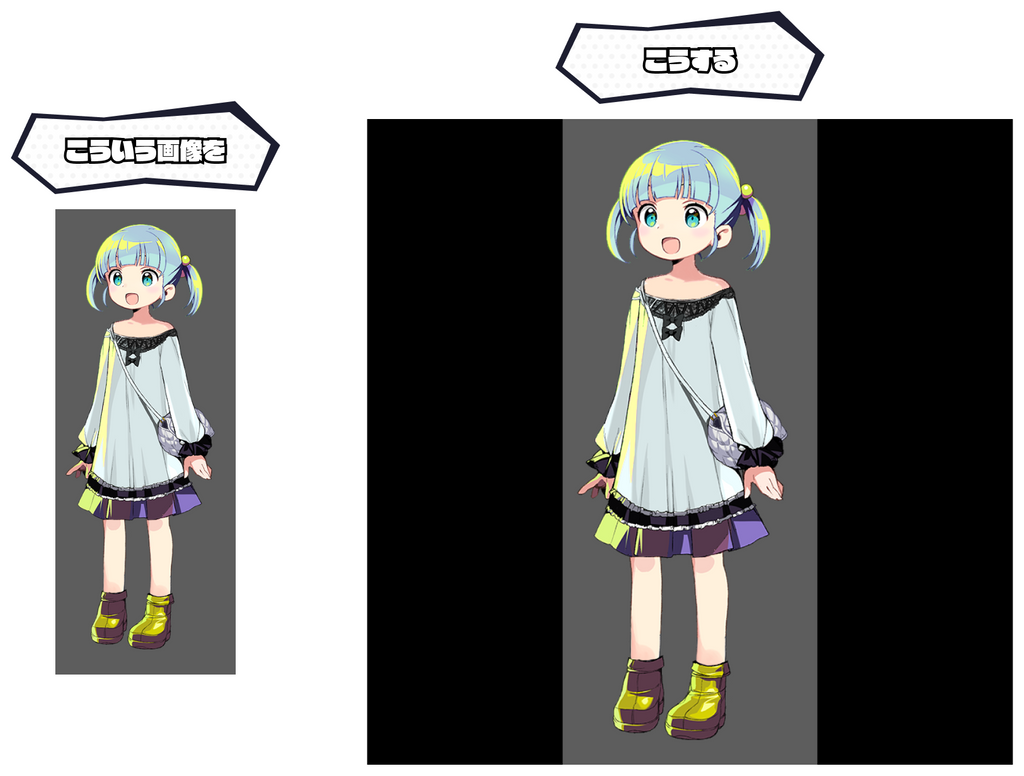
これを用いることで、さまざまなアスペクト比を持つ画像を全て1024px*1024pxにリサイズすることができた。
画像位置の調整
ダウンロードした画像の大きさを揃えることはできたが、このままジンザイとして利用すると不都合が生じる。例えば下に示した画像は、ダウンロード後に上記のリサイズ処理を行ったものであるが、このままドーナドーナのジンザイに利用するとかっこいいメカが見切れてしまう。メカが。


ジンザイに利用する画像は1024px*1024pxの大きさを指定されているが、実際にゲーム中で普段見えるのは下図の枠内のみである。そのため、上記のようにキャラクターによっては顔が枠内に入らず、見栄えが綺麗ではない。この枠内に顔が映るように位置の調整を行う。
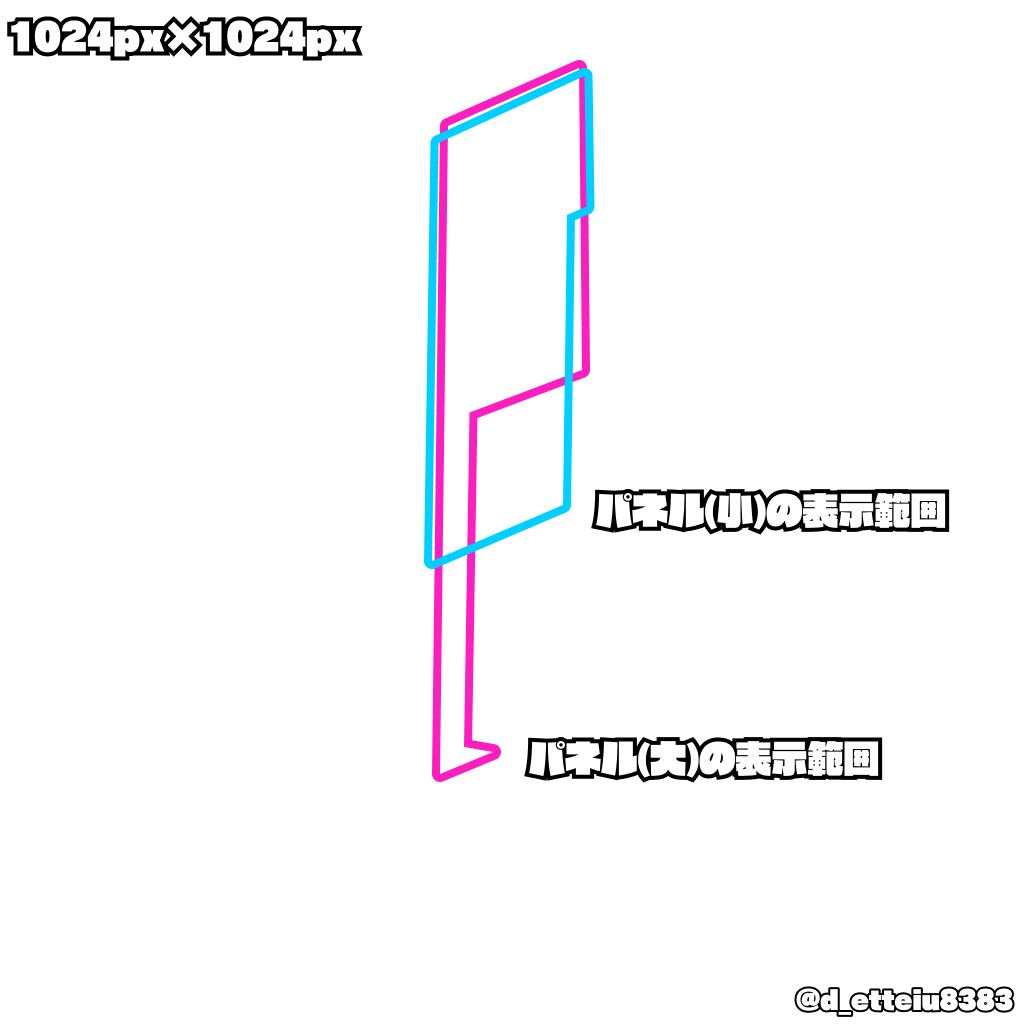
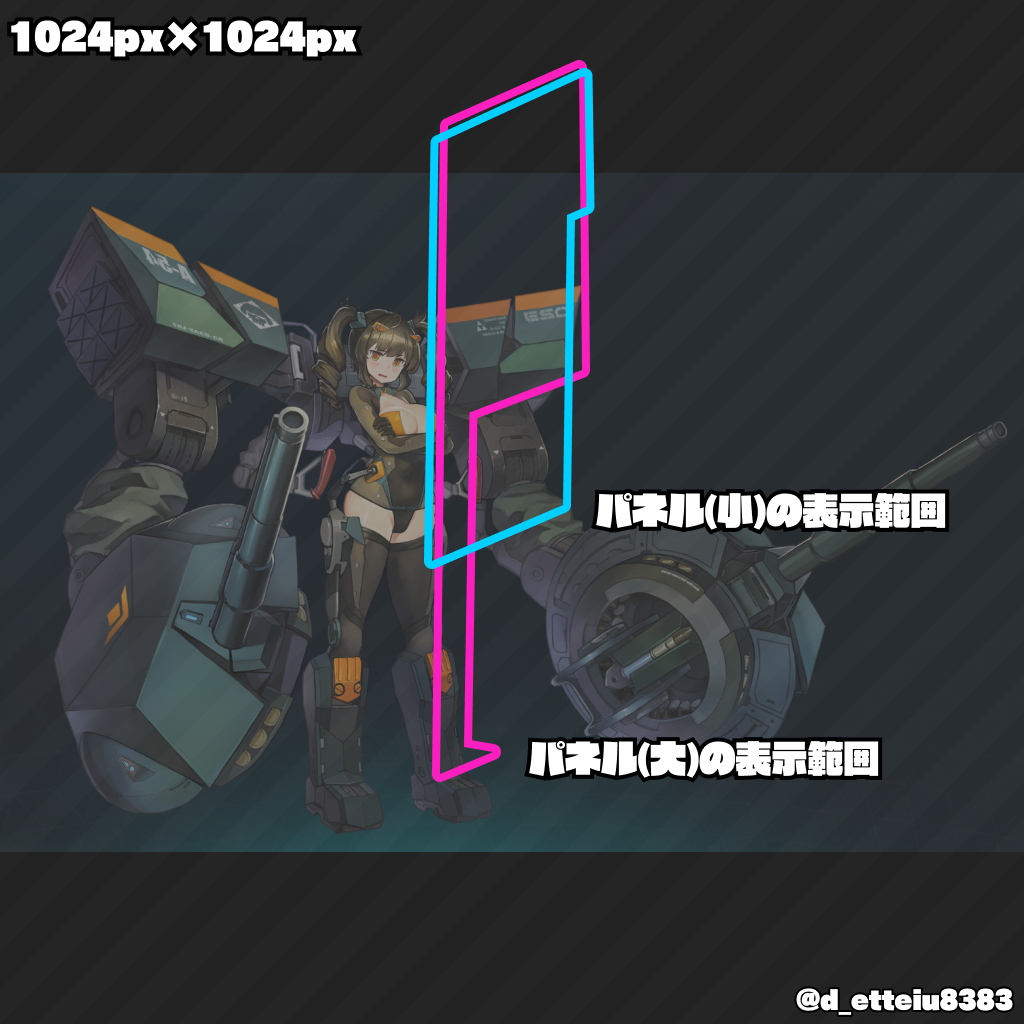
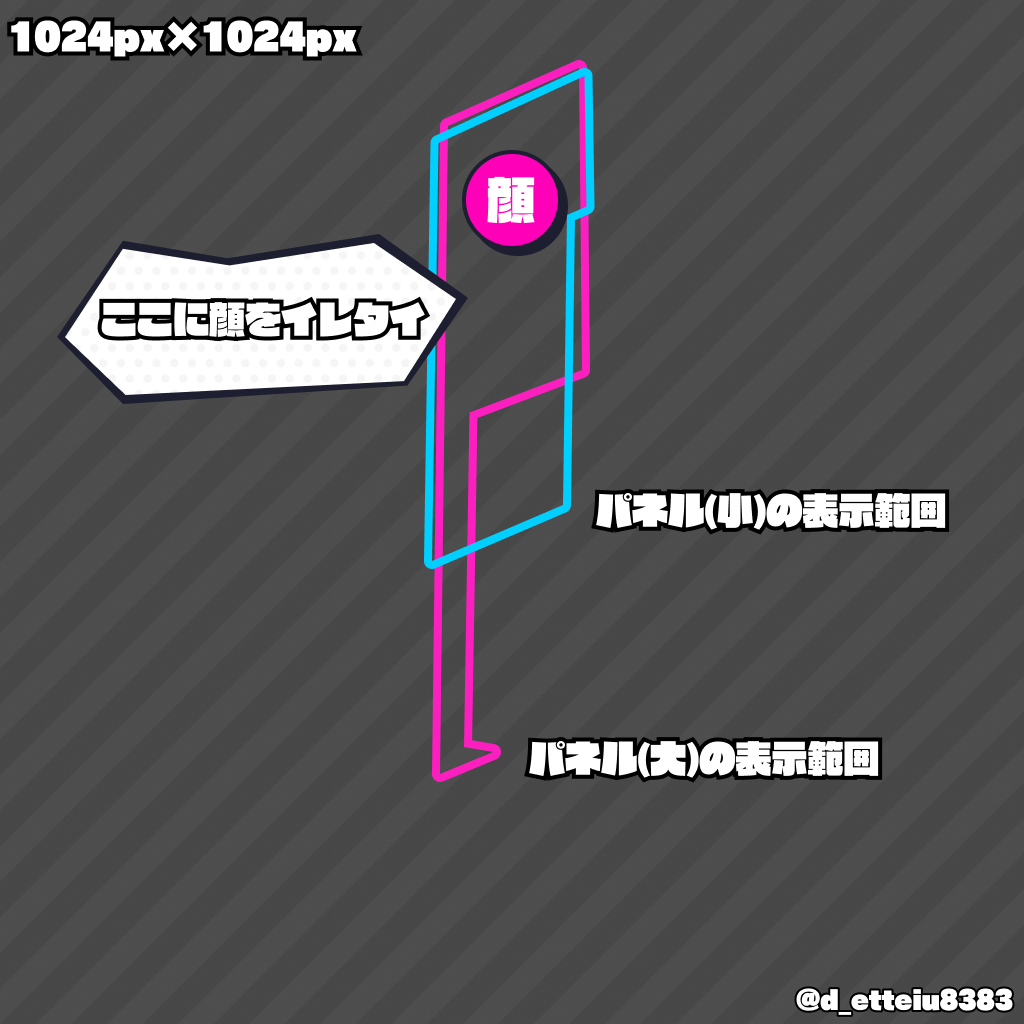
画像からキャラクターの顔位置を検出し、適切な位置に顔が来るよう拡縮と平行移動させることを考える。
今回はOpenCVのcv2.CascadeClassifierとdetectMultiScaleを利用したカスケード型分類器により顔を認識する(参考:物体検出 — opencv v2.1 documentation)。分類機にはnagadomi/lbpcascade_animefaceを利用した。
これを用いることで、下記のような簡単なコードでキャラクターの顔の位置を検出することができる。
import cv2
def main():
# 画像を読み込み
img_path = "calista_resize.png"
target_image = cv2.imread(img_path, cv2.IMREAD_UNCHANGED)
# 処理の高速化のためグレースケールに変換
gray_image = cv2.cvtColor(target_image, cv2.COLOR_BGR2GRAY)
# 顔の検出
classifier = cv2.CascadeClassifier('lbpcascade_animeface.xml')
faces = classifier.detectMultiScale(gray_image)
print(faces)
for x, y, w, h in faces:
# 顔が検出出来たら矩形を描き込む
cv2.rectangle(target_image, (x, y), (x+w, y+h),
(255, 255, 255, 255), thickness=10)
cv2.rectangle(target_image, (x, y), (x+w, y+h),
(0, 0, 255, 255), thickness=5)
# 画像の保存
cv2.imwrite("face_detect_sample.png", target_image)
if __name__ == '__main__':
main() # > [[354 333 62 62]]

これを応用し、得られた顔の位置と大きさの結果から、先述した枠内に顔が収まるようにアフィン変換を行う。
import glob
import cv2
import numpy as np
import os
import math
import imghdr
def resize_square(img, size):
# 省略
return dst
def main():
# ダウンロード画像の保存先フォルダを作成
adjusted_images_dir = "adjusted"
try:
os.mkdir(adjusted_images_dir)
except FileExistsError:
pass
# 位置調整する画像を保存しているフォルダを指定
image_source_dir = "download"
# 画像ファイルのパスを配列に保存
img_paths = [path for path in glob.glob(
f"{image_source_dir}/**/*.*", recursive=True) if os.path.isfile(path) and imghdr.what(path)]
# 分類器の読み込み
classifier = cv2.CascadeClassifier('lbpcascade_animeface.xml')
for img_path in img_paths:
# 保存パスを作成
file_name = os.path.splitext(os.path.basename(img_path))[0]
save_path = f"{adjusted_images_dir}/{file_name}_adjustment.png"
# 画像を読み込み
target_image = cv2.imread(img_path, flags=cv2.IMREAD_UNCHANGED)
# 1024*1024にリサイズする
resized_image = resize_square(target_image, 1024)
# 処理の高速化のためグレースケールに変換
gray_image = cv2.cvtColor(resized_image, cv2.COLOR_BGR2GRAY)
# 顔の検出
faces = classifier.detectMultiScale(gray_image)
if len(faces):
# 顔が検出出来たらイイ感じの位置に来るよう平行移動する
x, y, w, h = faces[0]
scale = 120 / w
M = np.float32(
[[scale, 0, -math.floor(x * scale) + 512 - math.floor(w * scale) // 2],
[0, scale, -math.floor(y * scale) + 150]
])
dst = cv2.warpAffine(resized_image, M, (1024, 1024))
# 画像の保存
cv2.imwrite(save_path, dst)
print(f"OK adjust the '{save_path}'")
else:
# 顔が検出できなかったらそのまま保存する
cv2.imwrite(save_path, resized_image)
print(f"!! could not detect face. '{save_path}'")
if __name__ == '__main__':
main()
以上、画像のリサイズと顔認識による位置調整の結果、ドーナドーナ取り込み時にも見栄えの良い画像素材を作成することができた。

設定テキストファイルの作成
画像が用意出来たら、次はジンザイの設定をまとめたテキストファイルを作成する必要がある。Pythonでは
with open("hoge.txt", mode='w') as f:
f.write("hage")
のように記述することで、"hage"というテキストを持つテキストファイルを作成することができる。これを用いて、設定ファイルの作成も自動で行った。
実際には以下のようなコードを書いた。
import glob
import os
import random
import shutil
import imghdr
import re
image_source_dir = "adjusted"
output_dir = "User"
# 画像ファイルのパスの配列を作成
img_paths = [path for path in glob.glob(
f"{image_source_dir}/**/*.*", recursive=True) if os.path.isfile(path) and imghdr.what(path)]
try:
os.mkdir(output_dir)
except FileExistsError:
pass
for i, zinzai_img_path in enumerate(img_paths):
# 画像ファイルをコピーする
copy = os.path.basename(zinzai_img_path)
shutil.copyfile(zinzai_img_path, output_dir+"/"+copy)
zinzai_path = os.path.basename(zinzai_img_path)
save_name = f"{output_dir}/{os.path.splitext(os.path.basename(zinzai_path))[0]}_zinzai.txt"
# ジンザイの属性を設定する。お好みで
zinzai_attr = random.sample(["えっち", "変態", "魔性", "無垢"], 3)
# ジンザイの音声を設定する。公式で紹介されている汎用ボイスの他、
# ナユタメンバーやユニークジンザイの音声も使用することができる。
zinzai_voice = [
"女子汎用/大/真面目", "女子汎用/大/陽気", "女子汎用/大/強気",
"女子汎用/高/真面目", "女子汎用/高/活発", "女子汎用/高/陽気", "女子汎用/高/控え目", "女子汎用/高/無邪気",
"女子汎用/中/真面目", "女子汎用/中/活発", "女子汎用/中/控え目",
"女子汎用/小/無邪気", "女子汎用/小/勝ち気", "女子汎用/小/控え目",
"キラキラ", "ポルノ", "メディコ", "アンテナ", "アリス", "菊千代",
# "クマ", "ザッパ", "虎太郎", "ジョーカー",
"リリヱ", "衣縫", "恭花", "凛", "ノエル", "心瑠姫", "環", "千晴", "フミ", "早奈", "菜々実", "しゅ子"
]
# 設定ファイルに描き込む内容。お好みで
zinzai_data = [
f"画像={copy}",
# f"名前=東工子",
f"ルックス=S+",
f"テクニック=S+",
f"メンタル=S+",
f"音声={zinzai_voice[i%len(zinzai_voice)]}",
f"属性={zinzai_attr[0]}",
f"属性={zinzai_attr[1]}",
f"属性={zinzai_attr[2]}",
f"処女=1",
]
# テキストファイルを作成する
with open(save_name, mode='w') as f:
f.write("\n".join(zinzai_data))
以上のコードにより、大量の設定ファイルも一瞬で作成することができた。
結果
上で説明した
- 画像の収集
- 画像の位置調整
を行い、大量の自作ジンザイを追加することができた。当初の目的であった実績も達成することができた。

考察
今回画像の収集に利用したWikiの画像は背景が透過されていなかったが、背景の糖化処理も自動化することで、よりクオリティの高いジンザイ画像を作成できると考えられる。機会があったら試してみたい。
いかがでしたか?
このブログ、結局何が言いたいのかというと
- ドーナドーナはいいぞ
- スッと使えるプログラミング言語を一つ持っておくと便利だぞ
- メディコはいいぞ
- DMM版Last Originの事前登録が始まってるぞ
の四点を覚えておいてくれたら僕は満足です。
明日の夏のブログリレー担当者は@Rasさん、Hgame班ブログリレーの担当は@mihama0833さんです。楽しみ~