前回、どうやってEpubが作られているのか、作り方について延々と無駄にお話ししました。でもこれって自動化できるんじゃね??と気が付き、自動化させてみました。
まず言語選び
ファイルのコピーや編集をするので、脳死でPythonを選択しました。
今思うとこの選択は正解でした。
それでは作っていく
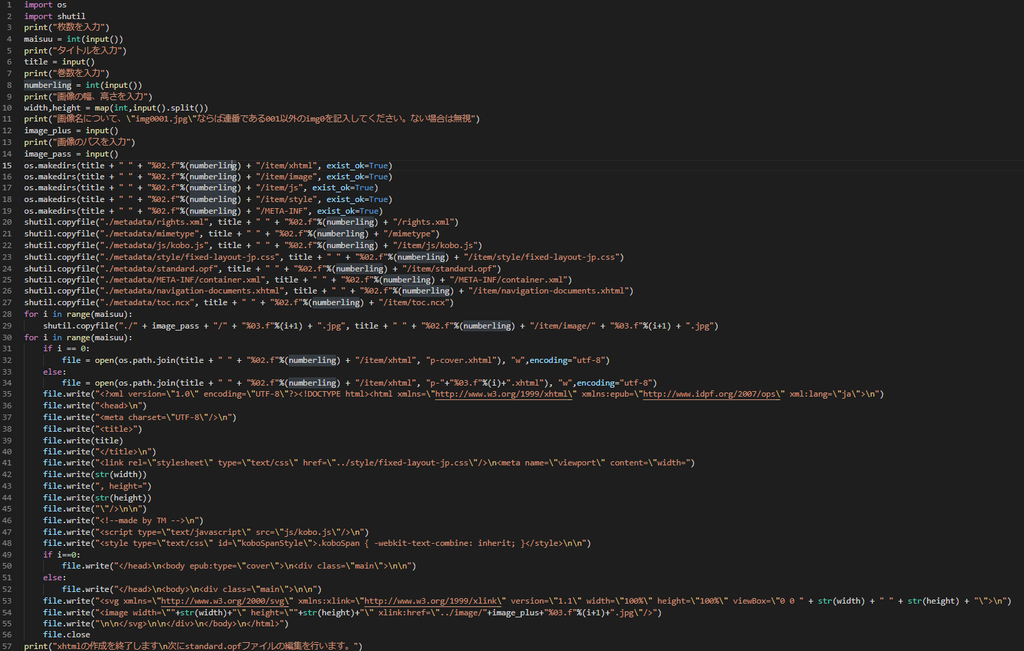
xhtml
そもそも自動化できる部分はそれなりにありますが、人間が入力したほうが早いものもあります。
- 画像枚数
- タイトルと巻数
- 画像の幅、高さ
- 画像名の入力
- 画像パスはどこか
これらはinputされるように書いています。最初はPythonに慣れていなくて、めちゃくちゃなコードになっています。どういうことかというと、中身が.pyファイルに全て格納されています。
for i in range(maisuu):
shutil.copyfile("./" + image_pass + "/" + "%03.f"%(i+1) + ".jpg", title + " " + "%02.f"%(numberling) + "/item/image/" + "%03.f"%(i+1) + ".jpg")
for i in range(maisuu):
if i == 0:
file = open(os.path.join(title + " " + "%02.f"%(numberling) + "/item/xhtml", "p-cover.xhtml"), "w",encoding="utf-8")
else:
file = open(os.path.join(title + " " + "%02.f"%(numberling) + "/item/xhtml", "p-"+"%03.f"%(i)+".xhtml"), "w",encoding="utf-8")
file.write("<?xml version=\"1.0\" encoding=\"UTF-8\"?><!DOCTYPE html><html xmlns=\"http://www.w3.org/1999/xhtml\" xmlns:epub=\"http://www.idpf.org/2007/ops\" xml:lang=\"ja\">\n")
file.write("<head>\n")
file.write("<meta charset=\"UTF-8\"/>\n")
file.write("<title>")
file.write(title)
file.write("</title>\n")
file.write("<link rel=\"stylesheet\" type=\"text/css\" href=\"../style/fixed-layout-jp.css\"/>\n<meta name=\"viewport\" content=\"width=")
file.write(str(width))
file.write(", height=")
file.write(str(height))
file.write("\"/>\n\n")
file.write("<!--made by TM -->\n")
file.write("<script type=\"text/javascript\" src=\"js/kobo.js\"/>\n")
file.write("<style type=\"text/css\" id=\"koboSpanStyle\">.koboSpan { -webkit-text-combine: inherit; }</style>\n\n")
if i==0:
file.write("</head>\n<body epub:type=\"cover\">\n<div class=\"main\">\n\n")
else:
file.write("</head>\n<body>\n<div class=\"main\">\n\n")
file.write("<svg xmlns=\"http://www.w3.org/2000/svg\" xmlns:xlink=\"http://www.w3.org/1999/xlink\" version=\"1.1\" width=\"100%\" height=\"100%\" viewBox=\"0 0 " + str(width) + " " + str(height) + "\">\n")
file.write("<image width=\""+str(width)+"\" height=\""+str(height)+"\" xlink:href=\"../image/"+image_plus+"%03.f"%(i+1)+".jpg\"/>")
file.write("\n\n</svg>\n\n</div>\n</body>\n</html>")
file.close
バカすぎるコード例
まあ出来ているので良しとします。直すのも面倒
standard.opf,目次の作成
新たに入力してもらうデータがあります。
- 作品のカタカナ名(読み)
- 作者名
- 作者のカタカナ名
- 出版社名
- 出版社のカタカナ名
- あらすじ
- 目次
metadataというフォルダがあり、スケルトン状態のstandard.opf,navigation-documents.xhtml,toc.ncxが保存されていて、作成しているepubフォルダにコピーし、それぞれの対応された行にデータを挿入しています。
with open(os.path.join(title + " " + "%02.f"%(numberling) + "/item", "standard.opf"),encoding="utf-8") as f:
l = f.readlines()
l.insert(5,"<dc:title id=\"title\">" + title + "%02.f"%(numberling) + "</dc:title>\n")
l.insert(6,"<meta refines=\"#title\" property=\"file-as\">" + title_yomi + "</meta>\n")
l.insert(22,"<meta name=\"original-resolution\" content=\"" + str(width) + "x" + str(height) + "\"/>")
l.insert(9,"<dc:creator id=\"creator01\">" + creator + "</dc:creator>\n")
l.insert(11,"<meta refines=\"#creator01\" property=\"file-as\">" + creator_yomi + "</meta>\n")
l.insert(15,"<dc:publisher id=\"publisher\">" + publisher + "</dc:publisher>\n")
l.insert(16,"<meta refines=\"#publisher\" property=\"file-as\">" + publisher_yomi + "</meta>\n")
l.insert(20,"<dc:description>" + description + "</dc:description>\n")
l.insert(36,"<meta property=\"fixed-layout-jp:viewport\">width=" + str(width) + ", height=" + str(height) + "</meta>\n")
with open(os.path.join(title + " " + "%02.f"%(numberling) + "/item", "standard.opf"), mode='w',encoding="utf-8") as f:
f.writelines(l)
file = open(os.path.join(title + " " + "%02.f"%(numberling) + "/item", "standard.opf"), "a",encoding="utf-8")
for i in range(maisuu):
if i == 0:
file.write("<item media-type=\"image/jpeg\" id=\"cover\" href=\"image/" + image_plus + "001.jpg\" properties=\"cover-image\"/>\n")
else:
file.write("<item media-type=\"image/jpeg\" id=\"i-" + "%03.f"%(i) + "\" href=\"image/" + image_plus + "%03.f"%(i+1) + ".jpg\"/>\n")
file.write("\n\n<!-- xhtml -->\n")
for i in range(maisuu):
if i == 0:
file.write("<item media-type=\"application/xhtml+xml\" id=\"p-cover\" href=\"xhtml/p-cover.xhtml\" properties=\"svg\" fallback=\"cover\"/>\n")
else:
file.write("<item media-type=\"application/xhtml+xml\" id=\"p-" + "%03.f"%(i) + "\" href=\"xhtml/p-" + "%03.f"%(i) + ".xhtml\" properties=\"svg\" fallback=\"i-" + "%03.f"%(i) + "\"/>\n")
file.write("\n<item id=\"xhtml-js-kobo.js\" href=\"xhtml/js/kobo.js\" media-type=\"application/javascript\"/><item id=\"js-kobo.js\" href=\"js/kobo.js\" media-type=\"application/javascript\"/></manifest>\n<spine page-progression-direction=\"rtl\" toc=\"ncx\">\n")
for i in range(maisuu):
if i == 0:
file.write("<itemref linear=\"yes\" idref=\"p-cover\" properties=\"rendition:page-spread-center\"/>\n")
elif i % 2 == 1:
file.write("<itemref linear=\"yes\" idref=\"p-" + "%03.f"%(i) + "\" properties=\"page-spread-right\"/>\n")
else:
file.write("<itemref linear=\"yes\" idref=\"p-" + "%03.f"%(i) + "\" properties=\"page-spread-left\"/>\n")
file.write("\n</spine>\n\n</package>")
file.close
//ここまででstandard.opfの編集が終わる
with open(os.path.join(title + " " + "%02.f"%(numberling) + "/item", "navigation-documents.xhtml"),encoding="utf-8") as f:
l = f.readlines()
with open(os.path.join(title + " " + "%02.f"%(numberling) + "/item", "toc.ncx"),encoding="utf-8") as f:
k = f.readlines()
for i in range(mokuji_suu):
print("ページ数:")
x = int(input())
x -= 1
if link_tuika == 0 and i == 0:
mokuji_page = x
with open(os.path.join(title + " " + "%02.f"%(numberling) + "/item/xhtml", "p-" + "%03.f"%(mokuji_page) + ".xhtml"),encoding="utf-8") as f:
s = f.readlines()
print("サブタイトル名:")
y = input()
l.insert(15+i,"<li><a href=\"xhtml/p-" + "%03.f"%(x) + ".xhtml\">" + y + "</a></li>\n")
k.insert(15+i*5,"<navPoint id=\"xhtml-p-" + "%03.f"%(x) + "\" playOrder=\"" + str(i+1) + "\">\n")
k.insert(16+i*5,"<navLabel><text>" + y + "</text></navLabel>\n")
k.insert(17+i*5,"<content src=\"xhtml/p-" + "%03.f"%(x) + ".xhtml\"/>\n")
k.insert(18+i*5,"</navPoint>\n\n")
if link_tuika == 0 and i != 0:
s.insert(16+i,"<a xlink:href=\"p-" + "%03.f"%(x) + ".xhtml\" target=\"_top\"><rect fill-opacity=\"0.0\" x=\"" + str(link_x) + "\" y=\"" + str(link_y) + "\" width=\"" + str(link_width) + "\" height=\"" + str(link_height) + "\"/></a>\n")
if(link_direction == 0):
link_y += link_height
elif(link_direction == 1):
link_x -= link_width
実はこれ、目次に対してリンクが付けられるようになっています。
どういうことかというと、目次ページには大抵「第hoge話 hogehoge」って一覧が載ってますよね??(それが目次)
そこをタッチすると、なんとその話まで一気に飛べるようになるんです!!便利~
ただ、linkはhtml方式なので、画像のx,y座標、ボックスの長方形の大きさは自分で調べてあげる必要があります。
まあそれも選択式で、さらには目次の無い4コマ漫画みたいなのも対応できるようにしています。
これでepubの素材の完成です。最後に、packingしましょう。
.batファイルによる実行
結論から言うと、
@cd %~dp0
set /P direction="Epubを最初から編集しますか?Yes:0 No:1 "
if %direction%==0 (
@python test.py
pause
)
@set /P USR_INPUT_STR="先ほど作ったフォルダを入力してください: "
cd %USR_INPUT_STR%
zip -0 -X ../"%USR_INPUT_STR%.epub" mimetype
zip -r ../"%USR_INPUT_STR%.epub" * -x mimetype
pause
exit
これで実行できます。
cd %USR_INPUT_STR%
zip -0 -X ../"%USR_INPUT_STR%.epub" mimetype
zip -r ../"%USR_INPUT_STR%.epub" * -x mimetype
これがepubを作るためのコマンドです。詳しくは知りません。コピりました。
まあこれでめでたく1からepubが作れる実行ファイルが完成しました。
今までそれなりに手作業でやってたのが自動化されて非常に便利になりました。
最後に
これ公開してもいいかなって思ったんですが、基本的なデータ(metadataフォルダ内)は全て楽天koboのepubからパクってきた参考にオマージュしたものなので、そこらへん著作権とかどうなのか怪しいと判断したため、非公開にします。少なくともここに書いたコードは自分作成なので大丈夫でしょう・・・(ところどころにkoboの文字があるのはそのせい)
なにかしら要望があれば公開はするかもしれません。その時は中身大幅に変えて自作を名乗れるようにします