この記事は2018年夏のブログリレー9/15の記事です。
はじめに
こんにちは、hukuda222です。今日は私ときんいろモザイクの小路綾ちゃんの誕生日です。実にめでたい日です。ところで、きんモザといえば何でしょうか? そう、英語です。そんなわけで英語の論文を頑張って読んだので、どんな感じだったかを紹介することにしました。色々拙いと思いますが、その辺は生暖かい目でスルーするか優しく指摘してくださると幸いです。
読んだのは、Universal Transformers(https://arxiv.org/abs/1807.03819)です。
概要
RNNやCNNを使わずにAttentionのみを利用したTransformer(https://arxiv.org/abs/1706.03762)によって、翻訳、画像生成、形態素解析などのタスクをこなせるようになったものの、他の多くのタスクにおいてはRNNの方が優れています。
そこで、汎用的に優れた性能を発揮するUniversal Transformersです。これはRNNのように系列の個々の情報を参照するのではなく、毎回系列全ての情報を参照しています。
導入

が最初の入力で、,,...,,と順番に計算していきます。()ここでのは系列のシンボルを表してるので翻訳の場合は、それぞれの単語です。
これの優れている点は、RNNと違ってそれぞれの単語の次のステップへの計算が独立なので並列的に計算できるところと、全ての単語の情報を次のステップの推定に使うことができるという点です。
従来のRNN以外の手法では、訓練中に与えられた長さ以外の入力に対してうまく処理することができなかったのですが、この手法では対応できます。
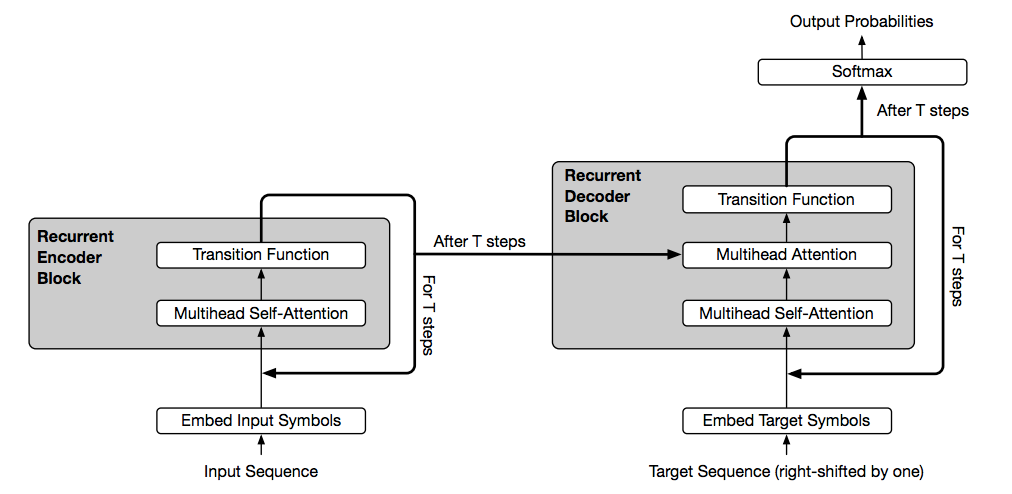
モデル

Encoder
- 入力はです。は系列の長さでは一つのシンボルをベクトルに変換した時の次元です。self-attentionによって入力された系列全てのシンボルを参照して新たなベクトル表現にし、transition functionがそのベクトルを用いてを出力します。そして、を入力としてを出力し……というのを回やって最終的にを出力します。それぞれのブロック間で残差学習やDropout、Layer Normalizationも使ったそうです。

Scaled Dot-Product Attention
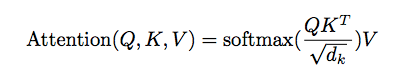
という入力がしれっと出てくるんですが、Query、Key、Valueの頭文字です。です。はそれぞれ入力に行列を掛けて作ります。
MultiHead Attention

で、です。Scaled Dot-Product Attentionを別々に回やってその結果を組み合わせているのでより精度が上がるらしいです。
Encoder全体

LayerNormalizationは、バッチ単位ではなくニューロン単位で出力を正規化する手法です。
Transition関数については、Separable Convolutionと全結合のニューラルネットをタスクに応じて使い分けるのが良いようです。
Separable Convolutionは畳み込みを空間方向とチャネル方向で行いパラメータを削減する手法です。Xception: Deep Learning with Depthwise Separable Convolutions(https://arxiv.org/abs/1610.02357)で提案されています。
は、系列の中での位置と、時間(何回繰り返されたか)、成分の次元に依存するパラメータです。位置エンコーディングと呼ばれ、時系列の情報を組み込むのに必要なようです。

Decoder
- Encoderとだいたい一緒です。ただし、2つ目のMultihead Attentionは、EncoderのMultihead Self Atentionとは異なり、はEncoderの出力であるから算出し、のみDecoderのMultihead Self Atention層の出力から算出します。(後の式自体は同じです)

Decoderはこれを出力します。で、は語彙数です。これが最も大きくなる語彙が予測された語彙となります。出力は1単語ではなく、回目以降の出力を合わせたものが推定された回答となります。
Adaptive Computation Time(https://arxiv.org/abs/1603.08983)
繰り返される数はACT(Adaptive Computation Time)によって決めることができます。ACTはRNNのを算出するところを最適化する手法です。具体的には、を中間状態の入力としてを計算し、それをさらに中間状態の入力として、を計算し、……を計算し、それらの重み付け平均を取ったものを、それらの出力を重み付け平均したものをの時の出力とします。
この記事が僕はわかりやすかったです(日本語なので) https://qiita.com/shotasakamoto/items/80809657c4492721b709
成果
定数回で打ち切るようにしたのを無印のUniversal Transformer、前述のACTによって何回で打ち切るかを決めたものをAdaptive Universal Transformerとしているようです。
bAbI Question-Answering

bAbIタスクは、質問応答の形式で自然言語理解の基礎的な能力をテストすることを目的としたタスク群です。12カテゴリー20種の小タスクで構成され、それぞれの小タスクの訓練データとテストデータは文脈設定の単文と1000文ずつの質問からなります。スコアはエラーの比率なので低いほど高精度です。
LAMBADA Language Modeling

LAMBADAタスクは小説から作られた穴埋め問題のタスクです。bAbIは語彙が少なく高いスコアが取りやすいのですが、こちらは小説が元のため難易度が高いです。LSTMやTransformerよりも良い結果を出してはいるもののRCのタスクは6割弱と難しいことがわかります。
Machine Translation

感想
長文読解を解きたくて適した方法を探していたのですが、この手法が向いてそうな気がしました。どの論文も多くの過去の論文を参照してることが多いので界隈によく出てくるものをちゃんと抑えないと辛そうな気がするというのと、参照している論文は大体全部あるのでarXivはすごいなぁと思いました。あと、論文だけ読んでも実装できるくらい完全に理解したかと言われると怪しいので、論文をスッとコードに落とせる人はすごいです。