
こんにちは。traP Advent Calendar 2017 12月8日担当の@hatasa-yです。
昨年のAdC、及び今年の新歓ブログリレーでは数学の記事を書いたので今回は技術系の話をしようと思います。
内容はJupyter Notebook及び機械学習の分類問題についてです。
Jupyter Notebookとは
ノートブックと呼ばれる形式でPythonのプログラムとその実行結果、ドキュメントなどを管理することができる統合環境です。プログラムの作成や保存、実行結果を残すことができます。
分類問題とは
分類問題は、データをその性質に従い分類する課題です。分類は人が指定します。例えば、果物をりんご、ばなな、…といった具合に分類するイメージです。

機械は人間とは違ってりんごが何かを知らないのでプログラムによってりんごが何かを与えないといけません。機械学習が発達してなかった頃のプログラミングではルール(りんごに関する特徴)をすべて人が決めて実装していました。一方機械学習ではそのルールをデータから機械に学ばせるという特徴があります。
@to-hutohuさんが昨年度のAdvent Calendarで書いた記事に出てくるこころ判定botはcocoroかNotcocoroで画像を分類しています。
準備
Pythonの最新版をインストール
Windowsを使っている人はPythonの公式サイト https://www.python.org/ からインストールしてください。Macを使っている人はこのサイト http://www.task-notes.com/entry/20141215/1418612400 を参考にしてインストールしてください。
Pythonをインストールできたら、動作確認をしてください。Windowsならばコマンドプロンプトを立ち上げ、MacならTerminalを立ち上げ、pythonと入力すると次の図のようになります。
このようになったらPythonのインストールに成功しています。quit()と入力するかCtrl+Z、Enterを、MacならばCtrl+Dと入力すると終了します。
Jupyter Notebookのインストール
Python 3.4以降のバージョンにはデフォルトでpipがインストールされているので、pipを使ってJupyter Notebookをインストールします。以下のコマンドでJupyter Notebookをインストールすることができます。
$ pip install jupyter
Jupyter Notebookの使い方
Jupyter Notebookの起動
Jupyter Notebookの起動は次のコマンドです。
$ jupyter notebook
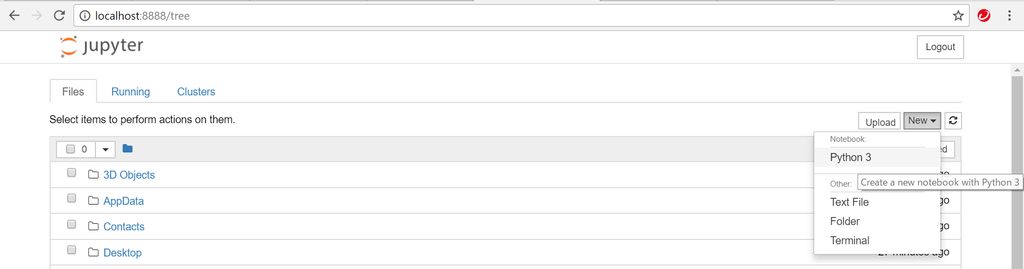
起動したら以下のような画面が自動で開きます。ここで表示されている画面は起動したディレクトリになります。右上のNewボタンからPython3を選択することでNotebookを作ることができます。
Pythonの実行
Notebook が開いたら Python のコードを入力して上の方にあるRunを押して実行してみましょう。shift + enterでも実行することができます。
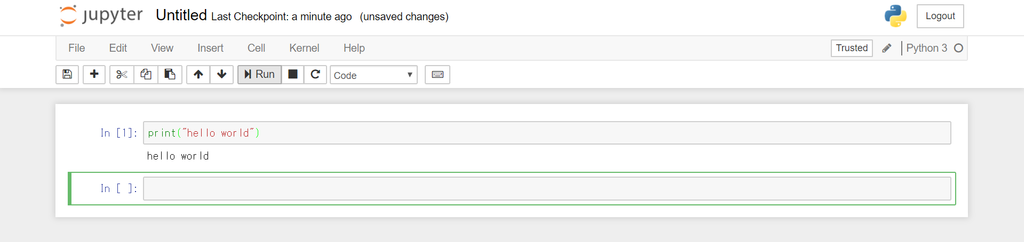
これ以降のPythonのプログラムは全てJupyter Notebookで実行されていることを想定して書いています(必ずこれを用いないといけないという訳ではありません)。
コメントを入れる
Pythonのコードだけでなく形式でMarkdown形式でテキストを入力することもできます。上の方にあるCodeをMarkdownに変えると入力することができます。

(整形前)
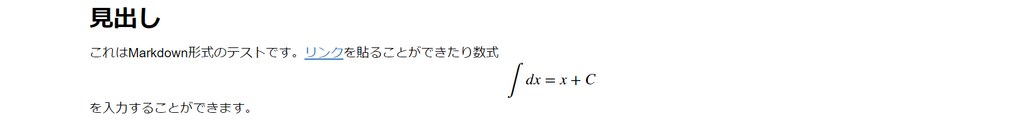
(整形後)
コードの実行を中止する
重い処理をしてしまったり、無限ループなどでいつまで経っても終わらないコードを間違えて実行してしまったときにはKernelメニューからInterruptを選ぶと中止します。
Jupyter notebookの停止
Jupyter Notebookを停止するには、Jupyter Notebookを動かしているコンソール画面からCtrl + Cを押すとShutdown this notebook server (y/[n])?と聞かれるのでyキーを押して終了します。

Pythonのライブラリ
ライブラリの確認
Pythonのライブラリについてです。次のコマンドでインストールされているパッケージを確認することができます。
$ pip freeze
ライブラリのインストール
次のコマンドで新しくパッケージをインストールすることができます。
$ pip install 'パッケージ名'
Numpy
ここではPythonのライブラリNumpyについて説明したいと思います。もしNumpyがインストールされていないのならば次のコマンドを使ってインストールしてください。
$ pip install numpy
NumpyはPythonの科学技術計算パッケージです。行列計算やフーリエ変換や乱数を容易に行うことができます。
Numpyのインポート
Numpyを使うためにはインポートが必要です。よくnpという名前を与えてインポートします。
# numpyをnpでインポート
import numpy as np
一様乱数
np.random.rand()で0~1の一様乱数を生成します。引数を指定すれば複数の乱数を発生させることができます。
np.random.rand() # 0〜1の乱数を1個生成
np.random.rand(100) # 0〜1の乱数を100個生成
np.random.rand(10,10) # 0〜1の乱数で 10x10 の行列を生成
np.random.rand(100) * 40 + 30 # 30〜70の乱数を100個生成
matplotlib
ここではPythonのライブラリmatplotlibについて説明したいと思います。もしmatplotlibがインストールされていないのならば次のコマンドを使ってインストールしてください。
$ pip install matplotlib
matplotlibはPythonの様々なグラフの描画を可能にするライブラリです。折れ線グラフや散布図などに対して、詳細に表示設定をすることが可能です。
実際に描画をしたいと思います。
# 各方程式を設定するためにNumpyをインポート
import numpy as np
# matplotlibのpyplotをpltでインポート
import matplotlib.pyplot as plt
# x軸の領域と精度を設定し、x軸を用意
x = np.arange(-3, 3, 0.1)
# 各方程式のy値を用意
y_sin = np.sin(x)
# 一様乱数
x_rand = np.random.rand(100) * 6 - 3
y_rand = np.random.rand(100) * 6 - 3
# figureオブジェクトを作成
plt.figure
#1つのグラフで表示する設定
plt.subplot
# 各方程式の線形とマーカー、ラベルを設定し、プロット
## 線形図
plt.plot(x, y_sin, marker='o', markersize=5, label='line')
## 散布図
plt.scatter(x_rand, y_rand, label='scatter')
# 凡例表示を設定
plt.legend()
# グリッド線を表示
plt.grid(True)
# グラフ表示
plt.show()
これを実行すると以下のような図が出てくると思います。
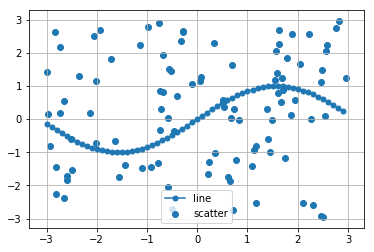
分類問題
scikit-learnを使って、実際に分類器を作ってみます。ここではscikit-learnに含まれる手書き数字データセットdigitsを使います。
digitsデータセット
digitsデータセットは0から9までの手書き数字の画像データからなるデータセットです。画像データは8*8ピクセルのモノクロ画像で、1797枚含まれています。
import matplotlib.pyplot as plt
from sklearn import datasets
# digitsデータをロード
digits = datasets.load_digits()
# 画像を2行5列に表示
for label, img in zip(digits.target[:10], digits.images[:10]):
plt.subplot(2, 5, label + 1)
plt.axis('off')
plt.imshow(img, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('Digit: {0}'.format(label))
plt.show()
これを実行すると以下のような図が出てくると思います。
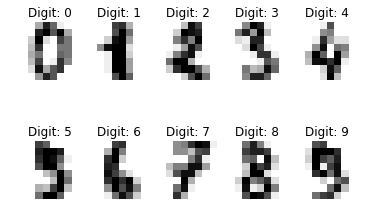
このデータを用いて3と8の画像データを分類する分類器を作ってみます。
分類器を作って評価する
3と8の画像データを分類する分類器をscikit-learnで作ってみます。
import numpy as np
from sklearn import datasets
# digitsデータをロード
digits = datasets.load_digits()
# 3と8のデータ位置を求める
flag_3_8 = (digits.target == 3) + (digits.target == 8)
# 3と8のデータを取得
images = digits.images[flag_3_8]
labels = digits.target[flag_3_8]
# 3と8の画像データを1次元化
images = images.reshape(images.shape[0], -1)
次に分類器を生成して学習を実施します。
from sklearn import tree
# 3と8の画像データを1次元化
images = images.reshape(images.shape[0], -1)
# 分類器の生成
n_samples = len(flag_3_8[flag_3_8])
train_size = int(n_samples * 3 / 5)
classifier = tree.DecisionTreeClassifier()
classifier.fit(images[:train_size], labels[:train_size])
最後から2行目の
tree.DecisionTreeClassifier()で分類器を生成しています。ここでは決定木というアルゴリズムを使って分類器を生成しています。決定木については後で説明します。
最後の行のclassifier.fit()で生成した分類器に学習データを与えて、学習を実施しています。
最後に分類器の性能を計算してみます。
from sklearn import metrics
expected = labels[train_size:]
predicted = classifier.predict(images[train_size:])
print('Accuracy:\n', metrics.accuracy_score(expected, predicted))
print('\nConfusion matrix\n', metrics.confusion_matrix(expected, predicted))
print('\nPrecision:\n', metrics.precision_score(expected, predicted, pos_label=3))
print('\nRecall:\n', metrics.recall_score(expected, predicted, pos_label=3))
print('\nF-measure:\n', metrics.f1_score(expected, predicted, pos_label=3))
結果は以下のようになります。
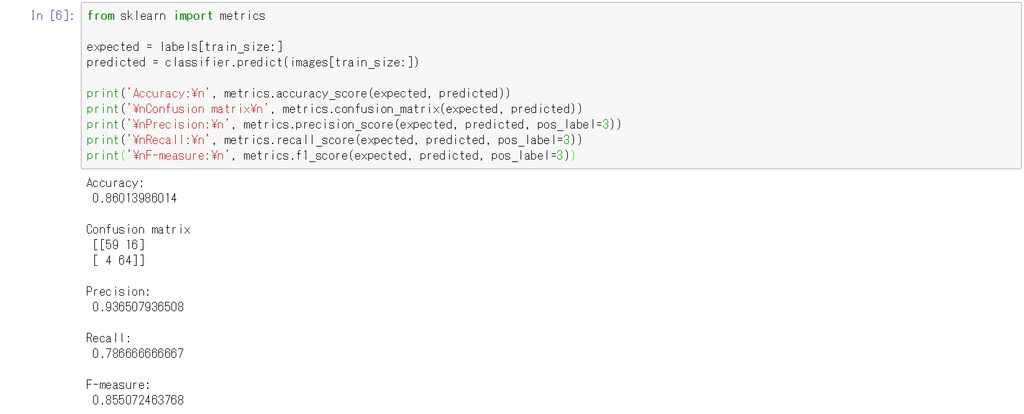
Accuracyは正答率、Precisionは適合率、Recallは再現率、F-valueはF値です。詳しい説明は次でします。
分類器の性能
PositiveとNegativeのいずれかを返す2値分類器を考えます。この場合、Positive/Negativeそれぞれについて正解/不正解があるので、表の4つの組み合わせがあります。
| 実際\予測 | Positive | Negative |
|---|---|---|
| Positive | True Positive (TP) | False Negative (FN) |
| Negative | False Positive (NP) | True Negative (TN) |
この表は混合行列(Confusion Matrix)とよばれています。「実際」と「予測」を転置して書く場合もあります。分類器の性能指標としてよく使われるのは以下の3つです。
正答率は、全体の事象の中で正解がどれだけあったかの比率です。分類器に対して1つの値が定義されます。
適合率は、分類器がPositiveと予測した中で、真にPositiveなものの比率です。Positiveと予測したもののうち、どれくらいが当たっているか、確度が高いかの指標です。
再現率は、真にPositiveなものに対して、分類器がどれだけ予測できたかを表します。実際にPositiveなものの中からどれくらい検出できたかの指標と言うこともできます。
分類器の性能は大まかに正答率で見ますが、それだけで不十分な場合があります。もう1つよく使われる指標としてF値があります。
これは適合率と再現率の調和平均です。2つの指標を総合的に見るときに使用します。
様々な分類器
最後に様々な分類器のアルゴリズムについて紹介しようと思います。
決定木
決定木はデータを複数のクラスに分類する教師あり学習の1つです。「樹木モデル」と呼ばれる木構造を利用した分類アルゴリズムです。
決定木の学習は学習データから樹木モデルを生成します。何を基準に分岐を行うかで、決定機はいくつかの手法に分類できます。
決定木のメリットは、分類ルールを樹木モデルとして可視化できるため、分類結果の解釈が比較的容易である点です。
ただし、決定木は過学習してしまう傾向があります。
アンサンブル学習
アンサンブル学習はいくつかの性能の低い分類器を組み合わせて、性能の高い1つの分類器を作る手法です。イメージとしては弱識別器の多数決です。アンサンブル学習は弱仮説器の生成方法によって2つに分類できます。
- バギング
- 学習データを抜けや重複を許して複数個のグループに分割し、学習データのグループごとに弱仮説器を生成する手法です。分類時は、各弱仮説気の出力した分類結果の多数決を取ります。
- ブースティング
- 複数の弱仮説器を用意し、重ね付きの多数決で分類を実現する方法です。その重みも学習によって決定します。難易度の高い学習データを正しく分類できる弱仮説器の判別結果が重視されるように重みを更新していきます。
Random Forest
Random Forestはアンサンブル学習のバギングに分類されるアルゴリズムです。学習データ全体の中から重複や欠陥を許して複数個の学習データセットを抽出し、その一部を使って決定木を生成します。
分類器の生成
3と8の手書き数字の画像データを分類する分類器をRandom Forestで作っていきます。
from sklearn import ensemble
# 3と8の画像データを1次元化
images = images.reshape(images.shape[0], -1)
# 分類器の生成
n_samples = len(flag_3_8[flag_3_8])
train_size = int(n_samples * 3 / 5)
classifier = ensemble.RandomForestClassifier(n_estimators=20, max_depth=3, criterion="gini")
classifier.fit(images[:train_size], labels[:train_size ])
最後から2行目のensemble.RandomForestClassifier()でRandom Forestの分類器を生成します。生成時にはパラメータを指定することができます。
AdaBoost
AdaBoostはアンサンブル学習のブースティングに分類されるアルゴリズムの1つです。AdaBoostでは、難易度の高いデータを正しく分類できる弱仮説器の分類結果を重視するよう、弱仮説器に対して重みを付けます。難易度の高い学習データと性能の高い弱仮説器に重みを付けることで、精度を上げます。
分類器の生成
3と8の手書き数字の画像データを分類する分類器をAdaBoostで作っていきます。
from sklearn import ensemble
# 3と8の画像データを1次元化
images = images.reshape(images.shape[0], -1)
# 分類器の生成
n_samples = len(flag_3_8[flag_3_8])
train_size = int(n_samples * 3 / 5)
estimator = tree.DecisionTreeClassifier(max_depth=3)
classifier = ensemble.AdaBoostClassifier(base_estimator=estimator, n_estimators=20)
classifier.fit(images[:train_size], labels[:train_size])
最後から2行目のensemble.AdaBoostClassifier()でAdaBoostの分類器を生成します。生成時にはパラメータを指定することができます。
まとめ
PythonのインストールからJupyter Notebookの始め方について書いていき、最後には機械学習の話となっていきました。ここまで読んでいただき本当にありがとうございました。
明日の担当は@Shoma-Mさんと@thorium129さんです。お楽しみに~
参考文献
村上和夫.Pythonによる機械学習入門.株式会社オーム社,2016.