
情報工学系 B3 の @abap34 です。昨年まで Kaggle 班の班長をしていました。
さて、Kaggle 班では定期的に部内データ分析コンペを開催しているのですが、

春休みということで 3/2 から 3/8 にかけて部内データ分析コンペを開催しました!
さらに、今回は日本経済新聞社様にご協力いただき、会場や日経のエンジニアの方によるサポートなどをご提供していただきました!
このブログではコンペとイベントについて振り返ります。
コンペの概要
期間は 3/2 ~ 3/8 までの一週間で、52人 (19チーム) が参加しました。事前にチームを結成しての参加という形式です。
今回は日本経済新聞社様から会場として東京本社をご提供いただき、初日と最終日に念願のオンサイトができました 🙌

コンペは 773 Sub、合わせて 18個の Discussion・公開カーネルが投稿されるという盛り上がりでした!
激戦を制したのは M1 の @SSlime さん, @Hmcmch さん, B1 の @Elmer さんからなるチームでした。おめでとうございます!
タスク
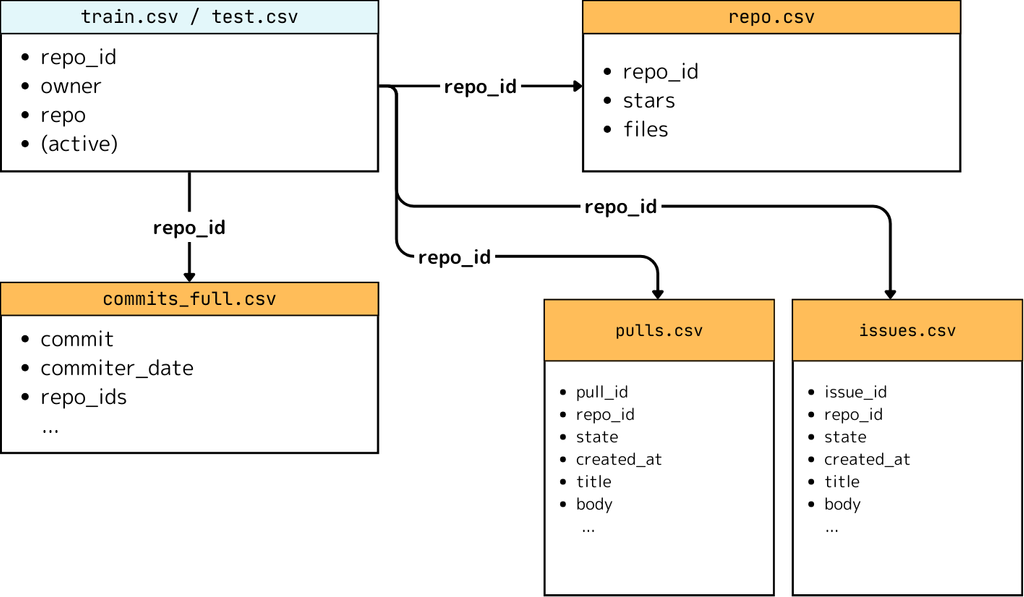
今回のお題は「GitHub のアクティブ予測」です。
データとしてコミットの列と issue, pull request などのレポジトリのメタデータを使い、2年後にそのプロジェクトは依然としてコミットされているか? かを予測する精度を競いました。
評価指標は ROC-AUC です。
データセット
Google が GitHub と協力して収集・公開している GitHub にあるレポジトリのさまざまなデータを集計した公開データセットからコミットを取得して、コミット頻度に基づいてレポジトリを4万個ほどサンプリングしました。

さらに、これらに対して GitHub の Public API を叩いて、issue, pull request, star 数などのメタデータを取得し、元データセットを作成しました。
これに対して
- 2022/01/01 までのコミットの取り出し
- 2022/01/01 時点の issue, pull request, star数にロールバック
をし、
「2025/01/01 から 2025/02/01 の間に少なくとも1件のコミットがあったか?」を「アクティブ」の定義として、ターゲットとして追加しました。
ここからターゲットがあまりにも imbalance にならないようにフィルタリングして、最終的に 約3500 レポジトリを訓練データ、約1800 レポジトリをテストデータとし、今回のコンペのデータセットとしました。
コミットデータの取得元である上のデータは 4TB, 30億行を超える非常に大きなデータセットなので、BigQuery で加工・抽出を行いました。(計算リソースは日経さんにご提供いただきました。個人の財布ではこのレベルのデータを扱うのはかなり大変なので本当に感謝しています)
GitHub の Public API は rate limit が厳しいため必要分を収集するのに 2週間近くかかりました。計算機を動かせる時間はずっと rate limit に引っかかっているせいで GitHub によるログインができなくなり、 Copilot などが死んでしまったのが辛かったです。
個人的な感想としては、いろんな目線でとても面白いタスクになったと思います。
まず競技的な目線で見ると、かなり「やることが尽きない」タイプのデータで面白いと思います。(詳しくは solution に少し書きます)
短期コンペにしてはデータ量がそこそこ多いのもありますが、それだけでなくテキスト (issue, pull request の本文など) が含まれているところなどもやり込み要素になりそうです。
また、単にソフトウェア開発者の目線で見ると「どういうレポジトリが将来的にアクティブになるのか?」は普通に気になるところです。
例えば
- author の多様性はどれくらい効くのか?
- 使っている言語によって変わるのか?
- issue の質はどれくらい影響する?
普通にコンペでなくとも調べたくなりますね。
solution
ここでは上位チームの解法に触れながら、(懇親会で話しきれなかったこともあったので) いくらか今回のコンペの solution について書きます。
上に書いたように今回のターゲットは結局コミットによって決まるわけですから「いかにコミット情報を載せるか?」が基本的に重要です。
さらに、将来的なコミット情報を伝えたい気持ちになると、コミットの間隔やその差分など、トレンドをうまく表現する特徴が作れると非常に強力です。(事前に解いた感じだと、この辺りをいくらか入れると 0.94 くらいは出るという想定でした)
上に書いたものに加えて
- 数ヶ月ごとのコミット数の集計
- 最長のコミット間隔
- コミット数の成長率
などを有効な特徴として見出しているチームが多かったです。
コミットの情報に加えて、差別化要素になりうるのが issue, pull request, star 数, fileなどのメタ情報です。これらの数などはもちろん有効ですし、close 率や close されるまでの期間などを集約しているチームもありました。
自由度が高く、個人的に面白いと思っているのは file のデータです。これにはファイル名とファイルサイズが入っているのですが、
- issue のテンプレートがあるか
- README.md のサイズ
などを作っているチームがありました。
短期コンということもあり、コミットメッセージや issue / pr の本文などのテキストに手を出せたチームはなかったようですが、これらの質を調べてみても面白いかもしれません。例えば
- title が body のいい要約になっているか調べる
- issue / pr の互いの類似度を調べることで、みんなが同じような形式を守っているか調べる
- ネガポジを調べてコミュニティの雰囲気の良さを調べる
などしてもらうことを出題者としては想定していました。
モデルは基本的には GBDT を使っているところが多く、実際うまく働いていたようですが、NN に手を出しているところもあったようです。
他にも、実装までは間に合わなかったようですが pseudo labeling を検討しているチームなどもあったようです。今回のようなタスクでは試したい選択肢だと思います。
オンサイトのイベント
オンサイトでは初日にキックオフと 1 Sub までのサポート、最終日には講評や日経のエンジニアの方による業務の紹介、上位入賞者の表彰や懇親会などを開催しました!




やはり実際に集まることの効果は大きいなと思いました。懇親会でずっと互いに効いたことやうまくいかなかったことなどを話し合っていてよかったです。
感想
念願だったオンサイトの開催と懇親会をできたこと、かなり面白い問題が作れたこと、個人的には大満足しています。
実は自分はこれで引退なのですが、機械学習に興味がある人がいる限り Kaggle班は盛り上がり続けていくと思いますので、今後にご期待ください!
問い合わせの窓口としては @abap34 はまだ有効なので、Kaggle 班に興味がある科学大生・企業の方などはお気軽にご連絡ください!
以上です。