この記事は, 2024 夏のブログリレー 1 日目の記事です.
はじめに
https://atcoder.jp/contests/arc136/tasks/arc136_d を解いたときに新しく勉強したことがあったので, 忘れないように書いておきます.
※本記事の後半にはこの問題の解法を述べる部分があります.
ゼータ・メビウス変換について
まず, ゼータ・メビウス変換の基本的な知識をまとめます.
ゼータ変換
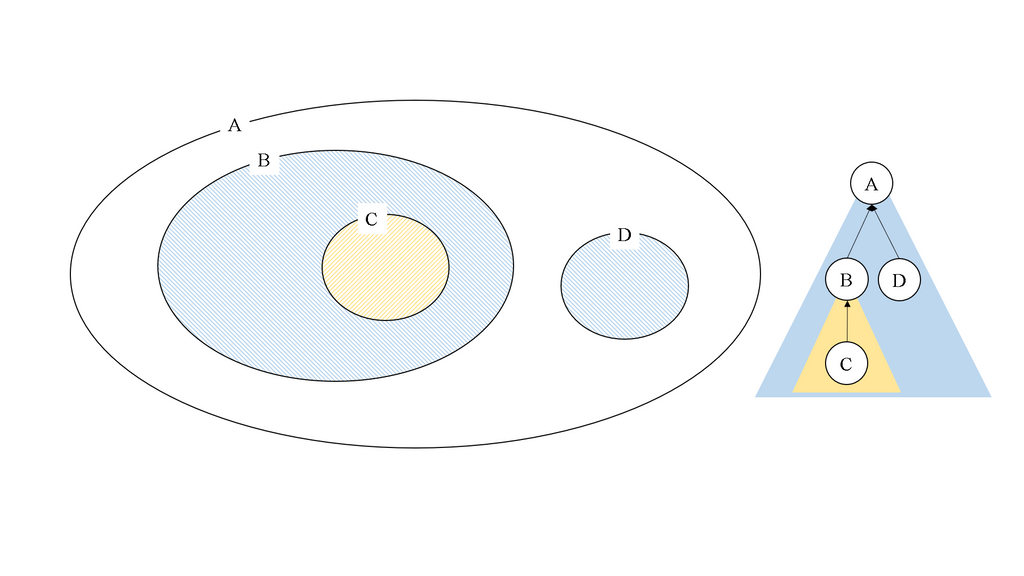
数列の添字をまとめた添字集合 を考えます. このときに, この集合で半順序関係 が成立して, かつ関数 が任意の で定義されている時, をゼータ変換した関数 を次のように定義します.
半順序関係
ある集合 について, 次の 3 つの性質を満たしているとき, 関係 は 半順序関係であるといいます.
- 反射律 : 任意の について,
- 反対称律 : 任意の について,
- 推移律 : 任意の について,
例 : 上で, 関係 は半順序関係である.
ゼータ変換は累積和を取る
上の定義を見ると, 競技プログラミング的には は累積和そのものであるとわかります. 実際, において, 関係 を考えると, このとき数列 は数列 の累積和をとったものであることが自然にわかると思います.
メビウス変換
ゼータ変換と同様の条件下で, をメビウス変換した関数を次のように定義します.
ここで, はメビウス関数であり, 次の性質を満たします.
メビウス変換は差分を取る
直感的には, ゼータ変換の逆のことを行っていると捉えることができます. すると先のゼータ変換では累積和を取ったのに対し, このメビウス変換では差分を取っていると考えられます. 実際, を のとき , のとき , そうでないとき をとる関数としてメビウス変換を行えば, 先の累積和から元の数列を復元することができます.
ゼータ変換の高速化
今回は, 次のようなゼータ変換を高速化することを考えます.
ある有限集合 に対し, 写像 が定められているとする. この時, を次のようにゼータ変換した関数 を求める.
解
for (int S = 0; S < (1 << n); S++) {
for (int T = 0; T < (1 << n); T++) {
if ((S & T) == T) F[S] += f[T];
}
}
一番簡単ですぐに思いつくのは, 愚直解だと思います. これなら確実に求められますが, 計算量は で少し重めです.
解
これを高速化するために, まずは が見る集合の数を減らしたいという気持ちになります. 今のところ は のすべての要素を調べていますが, 例えば のときに のケースは明らかに見る必要がないです. このような無駄を削ることで, が の部分集合のみを調べるようにすると, 高速化が出来ます.
for (int S = 0; S < (1 << n); S++) {
for (int T = S;; T = (T - 1) & S) {
F[S] += f[T];
}
}
サイズ の の部分集合の数は 個であり, それぞれについて部分集合は 個あるので, 計算量は です.
解 (高速ゼータ変換)
これをさらに高速化するために, dp のようなことをします. これによって計算量 で行うゼータ変換を高速ゼータ変換といいます.
とします. 例えば, のようになります. つまり, 下 桁以外は と一致して, 下 桁については任意のケタ について を満たすようなものすべてに対する の総和を求めるということになります.
次の 4 式を見比べてみましょう.
すると, 次のことが分かります.
すなわち, この dp は, のとき のとき と遷移すればよさそうです. こうすると, であることと, 個の要素からなる集合の部分集合は 個であることから, 計算量 でゼータ変換を行うことができます.
for (int i = 0; i < (1 << n); i++) {
dp[i][0] = f(i);
}
for (int i = 1; i <= n; i++) {
for (int j = 0; j < (1 << n); j++) {
if (j & (1 << (i - 1))) {
dp[j][i] = dp[j][i - 1] + dp[j - (1 << (i - 1))][i - 1];
}
else dp[j][i] = dp[j][i - 1];
}
}
ところで, この遷移を観察すると, 任意の について は必ず の形のところから遷移しているので, dp 配列を 1 次元にして使い回せるとメモリを節約できて嬉しいです.
添字のループの順番に気を付けながら実装すると, 次のように dp 配列の次元を落とすことができます. 1 次元にできたので, 名前は dp ではなく上の問題設定に従って F になりました.
for (int i = 0; i < (1 << n); i++) {
F[i] = f(i);
}
for (int i = 0; i < n; i++) {
for (int j = 0; j < (1 << n); j++) {
if (j & (1 << i)) {
F[j] += F[j - (1 << i)];
}
}
}
このようにして, でゼータ変換を行うことができました.
例
これを用いて冒頭に挙げた問題を解いていきます.
問題概要
長さ の整数列 がある. このうち, のペア であって, の計算をする際に繰り上がりが生じないものの個数を求めよ.
考察
この問題は 10 進数ですが, まずは 2 進数で同様の問題が与えられたときにどう解くかを考えてみます.
2 進数の整数がそれぞれ と表されるとします. この時, で繰り上げが発生しないためには, を満たす が存在しなければよいです. 即ち, を満たせばよいです.
ここで, 次のような dp を考えてみましょう.
この dp を考えると, ある整数 と足し合わせたときに繰り上がりが発生しないものの個数は, dp のサイズを として となります.
遷移ですが, ある bit が立っていなかったら, その bit が立っている数へ遷移するという形になります.
for (int i = 0; i < n; i++) {
for (int j = 0; j < (1 << n); j++) {
if (!(j & (1 << i))) {
dp[j + (1 << i)] += dp[j];
}
}
}
このように, 高速ゼータ変換と全く同じような考え方で解くことができるとわかります.
さて, 元のように 10 進数に戻して考えてみます.
10 進数の整数がそれぞれ と表されるとすると, 繰り上がりが発生しない条件は, を満たす が存在しないことです. よって, 各桁について, であれば より の遷移が存在します.
この遷移をすべての に対して行う, という操作をすべてのケタに対して行えばよいです.
dp 配列の初期化については, というペアだと考え, と初期化しておきます (他はすべて ) . ただ, が重複することがあるので, その際はその数だけ足します. 問題の制約より, は高々 6 桁なので, dp 配列のサイズは でよいでしょう.
vector<int>dp(1000000, 0);
for (int i = 0; i < n; i++) {
dp[A[i]]++;
}
int digit = 1;
for (int i = 0; i < 6; i++) {
for (int j = 0; j < 1000000; j++) {
if ((j / digit) % 10 < 9) {
dp[j + digit] += dp[j];
}
}
digit *= 10;
}
最終的に出力する答えは, となります. ただし, をするときに繰り上がりが発生しない場合, その分を答えから引く必要があるので注意してください.
int ans = 0;
for (int i = 0; i < n; i++) {
ans += dp[999999 - A[i]];
}
// a+b で繰り上がりが発生しなければ true, 発生すれば false を返す関数 check(a, b) を作っておくと便利
for (int i = 0; i < n; i++) {
if (check(A[i], A[i])) ans--;
}
cout << ans / 2 << endl;
あとは頑張ってコードを書くと, AC を得られます.
https://atcoder.jp/contests/arc136/submissions/56672429
最後に
調べたらもっと深いところまで色々出てきたのでそのへんも勉強していきたいですね.
明日は kashiwade さん, tatyam さん, alt--er さんです.