夏のブログリレー2022年の42日目の記事です。
はじまり
「あれこのPythonプログラム、1行で書けるんじゃね...?」皆さんこう思ったことはありませんか?ありますよね?そんな皆さんのために、この記事ではPythonワンライナーの自分なりの書き方を紹介します。
※ ほとんど私の主観です
基礎
応用はないです。
とりあえず先人の知恵を引用↓
- https://qiita.com/gyu-don/items/1c200d4e9fc6e22d3c7b
- https://qiita.com/KTakahiro1729/items/819318043f06f07be8c0
- https://qiita.com/KTakahiro1729/items/b2b1a9b82fc6e6d8c158
強調したいこと↓
- セミコロン
;,execはいらない- あれは邪道だ(過激派)
- ラムダ式
λ.でも()=>{}でも[](){}でもなくlambda:- デフォルト引数でメモできる
- 関数/ライブラリを使いこなす
enumerateはもちろん、itertools.accumulateとかも__import__という関数がありましてね...
- ちょっと関数型な思考回路になる
- 再帰とか部分適用とか
mapとかreduceとか - 副作用の考え方も
- 再帰とか部分適用とか
- 評価タイミングの話
- 計算をすることが副作用だと考えるといいかも
- truthy, falsyの話もある
A if X else BとX and A or Bと[B, A][X]は違う- セイウチ演算子
:=はめんどくさい
- 内包表記ってなんかダサくないか
mapを使いたい気分forの内包表記は時代遅れ(主観)
type関数- 実はこれで型を作れる
- つまり、クラス定義の文もPythonなら式1つに落とし込める
- チューリング完全
- やはりPythonは1行あれば十分
FizzBuzz
みなさんご存知のあれです。まずは普通に書くと↓のようになります。
for i in range(1, 101):
mod3 = i % 3 == 0
mod5 = i % 5 == 0
out = ""
if mod3:
out += "Fizz"
if mod5:
out += "Buzz"
if not out:
out = str(i)
print(out)
これをワンライナーで書く場合、いろんな書き方ができます。
# type 1
[print("FizzBuzz" if (mod3 := i % 3 == 0) * (mod5 := i % 5 == 0) else "Fizz" if mod3 else "Buzz" if mod5 else str(i)) for i in range(1, 101)]
# type 2
print(*("Fizz" * (not i % 3) + "Buzz" * (not i % 5) or str(i) for i in range(1, 101)), sep="\n")
# type 3
(lambda f: any(map(lambda i: print(f(i)), range(1, 101))))(lambda i: "Fizz "[:-(not i % 3)] + "Buzz "[:-(not i % 5)] or str(i))
注目したいのは↓の2点です。
- ループの評価方法
- 各イテレーションで、1から100の各
iから"Fizz"などの文字を得る式- 以降はこの式を
fizzbuzz(i)で表します
- 以降はこの式を
各typeについて箇条書きでざっくりと解説します。
type 1
[print(fizzbuzz(i)) for i in range(101)]- リスト内包表記
- 無駄な配列ができるのが、うーんってところ
"FizzBuzz" if (mod3 := i % 3 == 0) * (mod5 := i % 5 == 0) else "Fizz" if mod3 else "Buzz" if mod5 else str(i)- 愚直に場合わけ
- 長くてめんどくさい
*をandにしてはいけないandにするとmod5 := ...が評価されなくなる可能性がある- セイウチ演算子つきの式は必ず評価したい
type 2
print(*(fizzbuzz(i) for i in range(1, 101)), sep="\n")printの引数でジェネレーターを*展開- ありがちな方法(多分)
print呼び出しが一度になる反面、sep="\n"がついてくるのがなんとも- ↑が嫌だったら
"\n".joinを使うという手がある
"Fizz" * (not i % 3) + "Buzz" * (not i % 5) or str(i)- 文字列なのに数値みたい
"Fizz" * False + "Buzz" * Falseが""になるの、暗号では- 空文字列
""はfalsyなので、FizzもBuzzも当たらなかった時にorで右辺のstr(i)が評価される
type 3
(lambda f: any(map(lambda i: print(f(i)), range(1, 101))))(fizzbuzz)- 無理やりラムダ式使った
- 1と2で明確に処理が分離されて嬉しい
fizzbuzzがfという変数に代入された、と見れる- セイウチ演算子より楽かも
any関数ってなかなか見ないよねprint(f(i)) or i == 15とかにしたらわかるけど、途中にtruthyな要素があったらループが切れるmapでforを消せる、それはそう
"Fizz "[:-(not i % 3)] + "Buzz "[:-(not i % 5)] or str(i)[:-(これすき- 作者(私)「スライスしたかった」
"Hello"[:-False]は"","Hello"[:-True]は"Hell"末尾1文字の罠- type 2の暗号よりはましな暗号?
オレオレコーディング規約
ワンライナーを真面目に1行でやるのは無理なのでいい感じに改行したい、というわけで普段なんとなく考えていることを書いておきます。
(lambda f:
any(map(
lambda i: print(f(i)),
range(1, 101)
))
)(lambda i:
"Fizz "[:-(not i % 3)] + "Buzz "[:-(not i % 5)] or str(i)
)
オレオレ規約なので、テキトーに聞き流してください。以降はこんな感じでワンライナープログラムに改行、インデントを入れていきます。
再帰
クイックソートを考えましょう。まずは普通に書くと↓のようになります。
def quicksort(items: list[int]) -> list[int]:
if len(items) <= 1:
return items
head, *tail = items
return quicksort([e for e in tail if e < head]) + [head] + quicksort([e for e in tail if e > head])
この関数をワンライナーにするとこうでしょうか?
quicksort = (lambda items:
items if len(items) <= 1 else (
quicksort([e for e in items[1:] if e < items[0]])
+ [items[0]]
+ quicksort([e for e in items[1:] if e > items[0]])
)
)
ラムダ式内でquicksortを参照しているため、関数名をquicksortからquick_sortとかに変えるとエラーになります。
再帰をラムダ式内で完結させられたら嬉しいですね。ということで、そのように書きましょう。
quicksort = (lambda f:
lambda items: f(items, f)
)(lambda items, f:
items if len(items) <= 1 else (
f([e for e in items[1:] if e < items[0]], f)
+ [items[0]]
+ f([e for e in items[1:] if e > items[0]], f)
)
)
Yコンビネータなんて複雑なものを作らなくても、関数に自分自身を受け取る引数があればいいのです。
まあ僕はYコンビネータとか全くわかりませんが...
Brainf*ck
チューリング完全といえばやはりこれですね。
python3 bf.py helloworld.bfみたいに実行できることを想定してプログラムを作成します。
まずは普通に書きます。
import sys
class StateMachine:
def __init__(self) -> None:
self.mem = [0]
self.pointer = 0
self.cin = sys.stdin
self.cout = sys.stdout
def inc(state) -> None:
state.mem[state.pointer] += 1
def dec(state) -> None:
state.mem[state.pointer] -= 1
def left(state) -> None:
state.pointer -= 1
if state.pointer < 0:
state.mem.insert(0, 0)
state.pointer = 0
def right(state) -> None:
state.pointer += 1
if state.pointer >= len(state.mem):
state.mem.append(0)
def read(state) -> None:
state.mem[state.pointer] = ord(state.cin.read(1))
def write(state) -> None:
state.cout.write(chr(state.mem[state.pointer]))
def parse(code: str, exprs) -> list:
result = []
nest_count, nest_start = 0, 0
for i, char in enumerate(code):
if char in exprs:
not nest_count and result.append(exprs[char])
elif char == "[":
nest_count += 1
if nest_count == 1:
nest_start = i
elif char == "]":
nest_count -= 1
if nest_count == 0:
result.append(parse(code[nest_start + 1 : i], exprs))
return result
def run(code: list, state: StateMachine =None) -> None:
state_machine = state or StateMachine()
for expr in code:
if isinstance(expr, list):
while state_machine.mem[state_machine.pointer]:
run(expr, state_machine)
else:
expr(state_machine)
def main():
filename = sys.argv[1]
with open(filename) as f:
code = f.read()
exprs = {
"+": inc,
"-": dec,
"<": left,
">": right,
",": read,
".": write,
}
run(parse(code, exprs))
if __name__ == "__main__":
main()
↑のプログラムのワンライナー版が↓になります。
(lambda sys:
(lambda StateMachine, inc, dec, left, right, read, write:
(lambda parse, run, filename: (
run(parse(
(f := open(filename)).read(),
{"+": inc, "-": dec, "<": left, ">": right, ",": read, ".": write}
)),
f.close()
))(
(lambda f: lambda code, exprs: f(code, exprs, f))(
lambda code, exprs, f: (nest_count := 0) or (nest_start := 0) or list(filter(bool, (
(nest_count := nest_count + 1) == 1 and (nest_start := i) and None if char == "[" else
(nest_count := nest_count - 1) == 0 and f(code[nest_start + 1 : i], exprs, f) if char == "]" else
not nest_count and exprs.get(char, None)
for i, char in enumerate(code)
)))),
(lambda f: lambda code, state=None: f(code, state, f))(lambda code, state, f:
(state_machine := state or StateMachine()) and any(map(
(lambda expr:
not any(map(
(lambda _: [f(expr, state_machine, f), state_machine.mem[state_machine.pointer] == 0][1]),
iter(object, None)
)) if isinstance(expr, list) else
expr(state_machine)
),
code
))
),
sys.argv[1])
)(
type("StateMachine", (), {"__init__": (lambda self:
setattr(self, "mem", [0])
or setattr(self, "pointer", 0)
or setattr(self, "cin", sys.stdin)
or setattr(self, "cout", sys.stdout)
)}),
lambda state: state.mem.__setitem__(state.pointer, state.mem[state.pointer] + 1),
lambda state: state.mem.__setitem__(state.pointer, state.mem[state.pointer] - 1),
lambda state: (setattr(state, "pointer", state.pointer - 1) or state.pointer < 0) and state.mem.insert(0, 0),
lambda state: (setattr(state, "pointer", state.pointer + 1) or state.pointer >= len(state.mem)) and state.mem.append(0),
lambda state: state.mem.__setitem__(state.pointer, ord(state.cin.read(1))),
lambda state: state.cout.write(chr(state.mem[state.pointer])) and None
)
)(__import__("sys"))
書いててあたま爆発しそうになりました。実際に1行にしたものがこちら
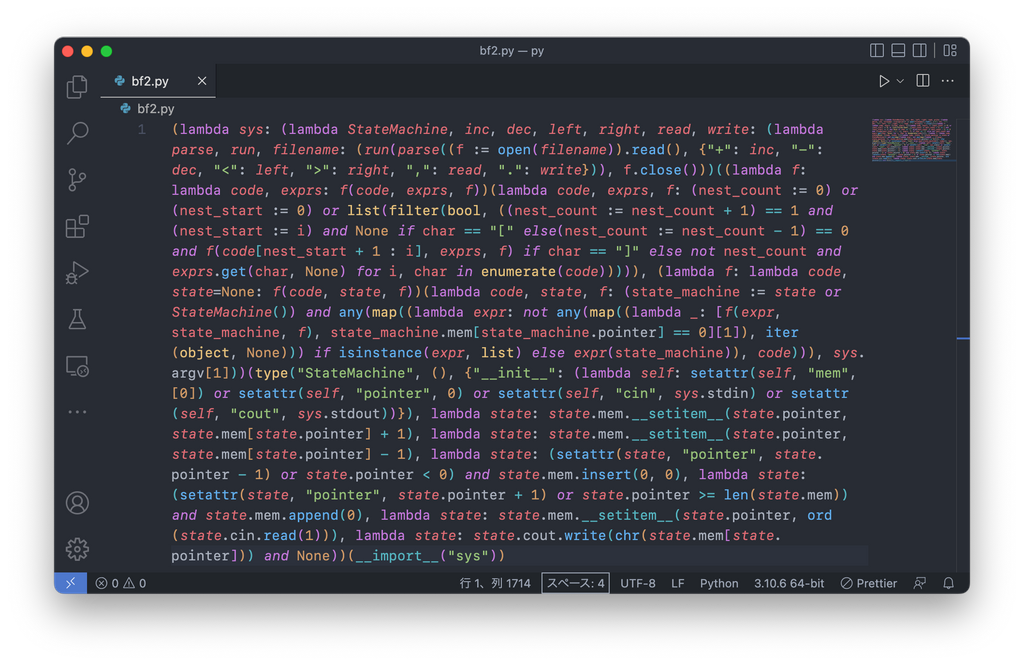
Pythonってすげえ...
AtCoder
おまけ的な実践編です。
freee プログラミングコンテスト2022(AtCoder Beginner Contest 264)のA, BをPythonワンライナーで解きます。
ABC264のネタバレになるので折りたたんでおきます
A
問題文
文字列
atcoderの文字目から文字目までを出力してください。制約
- は整数
(lambda l, r: print("atcoder"[l - 1:r]))(*map(int, input().split()))
添字の罠に注意しましょう。
B
問題文
次の図に示す、各マスが黒または白に塗られた縦行横列のグリッドにおいて、上から行目、左から列目のマスが何色かを出力して下さい。
制約
- は整数

print((lambda r, c: ["white", "black"][r & 1 if r > c else c & 1])(*map(lambda a: abs(a - 8), map(int, input().split()))))
ちょっと複雑な感じがあるのでやっていることを書いておきます。
- 対称性に注目して、
lambda a: abs(a - 8)で"第一象限"に限定- といったところ
- グリッドの右下だけ考えるイメージ
- の大小で場合わけ
- のとき、の偶奇を見る
- それ以外のとき、の偶奇を見る
maxでいいじゃん
- 偶数→白、奇数→黒
- 中心の白から外側に0, 1, 2, ... と番号が増えていく感じ
おわり
皆さんもPythonワンライナーしましょう
次の担当は@SlimySlimeさんです!