
こんにちは、19Bの@temmaです。普段は、部内サービスの開発・運用を担当するSysAd班というチームで活動しています。この記事は、traP夏のブログリレー 50日目の記事です。
 temma
temma
GoでPDFを一から作って見ます。
基本はISO 32000-1:2008(PDF1.7)を読むだけですが、量が多いので先人の知恵を借ります。以下の参考資料に言及がない機能は、既存のPDFを頑張って読むか、仕様(サンプルコードもあるよ)を読んだほうが早いと思います。
- 資料1: https://aznote.jakou.com/prog/pdf/index.html
まとまっていてわかりやすかったです。 - 資料2-1: https://brendanzagaeski.appspot.com/0004.html
資料2-2: https://brendanzagaeski.appspot.com/0005.html
最初に「PDFって作れんの?」って思ったときに出てきました。助かる。 - 資料3-1: https://gendignoux.com/blog/2016/10/04/pdf-basics.html
資料3-2: https://gendignoux.com/blog/2017/01/05/pdf-graphics.html
図が分かりやすいです。
基本は↑を見れば書けます。
実際にコードを見ながら説明する前に、最低限のPDFの概要を見ておきます。(資料3から抜粋・補足して訳したもの)
PDFファイルはバイナリフォーマットですが「圧縮されている場合・暗号化されている場合・バイナリコンテンツを持つ可能性のある特定の要素(画像やフォントなど)」を除いてテキスト(ASCII)ファイルとして解釈可能です。
また、COS(Carousel Object System)と呼ばれる形式のサブセットを使用しています。
PDFのデータ構造は、大まかに以下の4つの部分で構成されています。
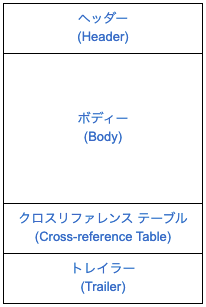
ヘッダー
PDFファイルは%PDF-1.7などのフォーマットのバージョンを含むヘッダーで始まります。
The first line of a PDF file shall be a header consisting of the 5 characters
%PDF–followed by a version number of the form1.N, whereNis a digit between 0 and 7.
また、マジックナンバーが含まれることがありますが、PDFとしては無視されます。
ボディー
PDFファイルの内容に当たる部分で、基本的に複数のオブジェクトをノードとした有向グラフで構成されます。
オブジェクトに以下のようなラベルを付けることで、他のオブジェクトから参照できます(Indirectオブジェクト)。
ラベルは空白区切りの「オブジェクト番号」「世代番号」で構成され、その後にobj,endobjキーワードで囲まれたオブジェクトの値が続きます。
1 0 obj
<<
/Type /Catalog
/Pages 2
>>
endobj
他のオブジェクトから参照する時は1 0 Rのように「オブジェクト番号」「世代番号」にRキーワードを付けます。
trailer
<<
/Size 11
/Root 1 0 R
>>
startxref
28423
%%EOF
クロスリファレンステーブル
クロスリファレンステーブルは、PDFファイル内のオブジェクトへのインデックスです。これにより特定のオブジェクトを探すためにファイル全体を読む必要がなくなり、高速な読み込み・表示が可能になります。このテーブルには、各オブジェクトに対して1行のエントリがあり、ファイル本体内のオブジェクトのバイトオフセットが指定されています。
トレイラー
トレイラーにはクロスリファレンステーブルのバイトオフセットと特定の種類のオブジェクトへの参照があります。PDFリーダーはトレイラーの情報を使って、読み込みの最初に必要な情報を取得します。
より詳細には以下のとおりです。
オブジェクトは、書き方が違うJSONのようなものだと思えば理解しやすいです。オブジェクトは、以下のデータタイプで構成されています。
- Booleanオブジェクト:
true,false - Numericオブジェクト
- Integerオブジェクト: ex.
123,-71 - Real numberオブジェクト: ex.
1.23-0.456- 指数表記は使用不可
- Integerオブジェクト: ex.
- Stringオブジェクト: カッコで囲まれたASCII文字列 ex.
(foo),(Hello world\n)- バックスラッシュ
\はエスケープ文字 <>で囲むことで16進数表記も可能 ex.<48656C6C6F20776F726C64>(equivalent to(Hello world))
- バックスラッシュ
- Nameオブジェクト: スラッシュ
/で始まるASCII文字列/bar,/Hello#20world- Identifier(キー)として機能する
- Number sign
#はエスケープ文字
- Arrayオブジェクト: ex.
[123 456 789],[[123 (foo)] /bar true 45.6] - Dictionaryオブジェクト:
<<>>で囲まれた空白区切りのキーバリューペア ex.<< /key (value) /foo 123 >> - Streamオブジェクト:
stream,endstreamキーワードで挟まれたバイト列- Stream Extent: 少なくともStreamオブジェクトの長さを示す
Lengthが必要
- Stream Extent: 少なくともStreamオブジェクトの長さを示す
- Indirectオブジェクト: ラベル付きオブジェクトへの参照 ex.
1 0 R - Nullオブジェクト:
null- 参照先が存在しないIndirectオブジェクトもNullオブジェクトとして扱われる
加えて%始まり改行で終わるコメントも挿入可能(改行: \r, \n, \r\n)
Validな例
<<
/C [0 1 0]
/Rect [149.373 465.656 159.335 472.481]
/Type /Annot
/A <<
/S /GoTo
/D (24)
>>
/Border [0 0 1]
/Subtype /Link
% This is a comment
>>
30分、冷蔵庫で冷やしたものがこちらです。
 isucon
isucon実際にコードを見ながら解説します。生成されたPDFの例も公開しておくので見比べながら読むと分かりやすいと思います。
func PDF(text string, img *Image) []byte {
w := &countingWriter{
buf: bytes.Buffer{},
}
// ヘッダーのwrite
if err := header(w); err != nil {
panic(err)
}
// 各種オブジェクトがwriteメソッドを実装している
objs := []obj{
&catalog{
pages: "2 0 R",
},
&pages{
pageCount: 2,
kids: "3 0 R 7 0 R",
pageHeight: 1000,
pageWidth: 1600,
},
// p1
&page{
parent: "2 0 R",
resources: "4 0 R",
contents: "6 0 R",
},
&procset{
fonts: map[string]string{"F1": "5 0 R"},
},
&font{
baseFont: "Helvetica",
},
&textContents{
text: text,
x: 64 * 2,
y: 1000 - 100,
fontID: "F1",
fontSize: 64,
},
// p2
&page{
parent: "2 0 R",
resources: "8 0 R",
contents: "10 0 R",
},
&procset{
xObjects: map[string]string{"I1": "9 0 R"},
},
img,
&imageContents{
imageID: "I1",
x: 100,
y: 100,
mag: 700,
},
}
// オブジェクトのwriteとxrefに必要な情報の取得
linelens, _ := body(w, objs)
objNum := len(objs)
// クロスリファレンステーブルのwrite
if err := xref(w, objNum, linelens); err != nil {
panic(err)
}
// トレイラーのwrite
if err := trailer(w, "1 0 R", objNum); err != nil {
panic(err)
}
return w.Bytes()
}
body関数では、オブジェクトの配列に対して順にオブジェクト番号を割り当てて、書き込んだバイト数を記録しています。
trailerにはRootとしてCatalogオブジェクトへの参照である1 0 Rを渡しています。trailerには少なくとも、ファイルリファレンステーブルの総エントリー数であるSizeと、オブジェクトの階層構造の根(Catalogオブジェクト)への参照であるRootが含まれている必要があります。
xref関数、trailer関数の詳細が知りたい方は、ドキュメントの7.5.4 Cross-Reference Table, 7.5.5 File Trailerを参照してください。
オブジェクトの中身を改めて確認してみます。
objs := []obj{
&catalog{
pages: "2 0 R",
},
&pages{
pageCount: 2,
kids: "3 0 R 7 0 R",
pageHeight: 1000,
pageWidth: 1600,
},
// p1
&page{
parent: "2 0 R",
resources: "4 0 R",
contents: "6 0 R",
},
&resources{
fonts: map[string]string{"F1": "5 0 R"},
},
&font{
baseFont: "Helvetica",
},
&textContents{
text: text,
x: 64 * 2,
y: 1000 - 100,
fontID: "F1",
fontSize: 64,
},
// p2
&page{
parent: "2 0 R",
resources: "8 0 R",
contents: "10 0 R",
},
&resources{
xObjects: map[string]string{"I1": "9 0 R"},
},
img,
&imageContents{
imageID: "I1",
x: 100,
y: 100,
mag: 700,
},
}
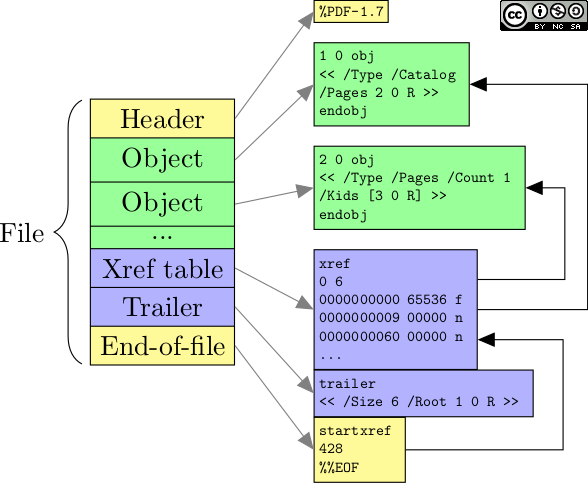
書き起こすと以下のような構造になっています。
ドキュメント(72ページ)の図を見ても分かりやすいかもしれません。
.
├── catalog
│ └── pages
│ ├── page
│ │ ├── resources -> font (as F1)
│ │ └── textContent (-> F1)
│ └── page
│ ├── resources -> img (as I1)
│ └── imageContet (-> I1)
├── font
└── img
catalogやpages、pageオブジェクトは見たままなので省略します。
fontやimgオブジェクトはそれぞれの仕様に従って、リソースを登録しています。
詳しくはそれぞれ9.6 Simple Fonts, 6.9 Imagesを参照してください。
content stream
content streamは内容を実際に、グラフィカルな要素として描画するための手順を記述したStreamオブジェクトです。ページのContentsとして指定します。
content streamはstate machineで、テキストとして記述された命令列を順に実行していきます。content stream内ではIndirectオブジェクトを使用できないため、resources(resource dictionaries)内で各オブジェクトの名前と内容を紐付け、content stream内ではその名前を使ってデータを参照します。
具体的にtextContentとimageContentについて、実際に生成されたPDFを見ながら解説します。
textContent
6 0 obj
<<
/Length 200
>>
stream
BT
128.00 900.00 Td
/F1 64.00 Tf
70.40 TL
(L0132 part 1) Tj T*
(code S00147) Tj T*
() Tj T*
(Q1. x) Tj T*
(Q2. o) Tj T*
(Q3. 2) Tj T*
(Q4. 3) Tj T*
(Q5. x) Tj T*
() Tj T*
ET
endstream
endobj
BT(Begin Text), ET(End Text)オペレーターの間で記述されたテキストは一つのテキストオブジェクトとして扱われます。
Td, Tfなどのオペレーターはそれぞれオペランドを受け取って実行されます。
ここではポジションのオフセットの設定やフォントの指定、行間の設定、文字列の描画、改行などを行っています。フォントの指定にはresourcesで登録した名前をNameオブジェクトとして使用しています。
詳しくは資料1を参考にしてください。
imageContent
10 0 obj
<<
/Length 44
>>
stream
q
700 0 0 700 100.00 100.00 cm
/I1 Do
Q
endstream
endobj
画像の描画も同様で、I1をDoオペレーターで描画しています。q, Qオペレータを使って、現在のページの状態をスタックに保存したり、スタックから復元したりすることでcmオペレーターによる変換を画像のみに適用しています。
ページ内に画像を配置する場合は、大きさをユーザー空間単位に合わせる必要があります。
「画像の幅・高さ = ユーザー空間での 1.0」として扱われるため、変換行列で指定した拡大率 (行列内での a と d の値) は、そのまま、ページ内での画像のサイズとなります。
このcmオペレーターが無いと、1x1の極小画像が描画されて「なんで画像が描画されないんだ、う〜ん」と悩むことになります。僕は悩みました。
あと、既存のPDFはデフォルトでStreamオブジェクトの中が圧縮されてることが多くていちいち面倒だったりします。正しいんだけども。
上手に焼け書けました〜♪
はい、まあこんな寸法でPDFを生成しました。
わりとやるだけ感が強かったですね。
誰もやってないからか良い資料にたどり着きにくくて、途中まではウンウン言いながら既存のPDFとにらめっこしてました。
小噺
ISUCON11でキャッシュ対策として、PDFを動的に生成するために書いたコードですが結局最後までベンチマーカーインスタンスに余裕があったので、実は普通にライブラリを使えばよかった説があります。悲しい。
あと、実際にPDFを手元で開いた方がいるかわかりませんが、画像は https://trap.jp へのQRコードになってました。
 isucon
isucon明日(物理今日)の担当者は@iroriくんです。楽しみ!