
こんにちは、19Bの@temmaです。普段は、部内サービスの開発・運用を担当するSysAd班というチームで活動しています。
この記事は、traP夏のブログリレー 36日目の記事です。
 temma
temma
さよなら、ありがとう、S512
traPの部内サービスはConoHaのVPS上にデプロイされており、各インスタンスには東工大の教室にちなんだ名前がつけられています。


インスタンスのひとつ「S512」には、サービスの中でも特に重要な部内SNS「traQ」と部員管理システム「traPortal」、認証基盤「pipeline」がデプロイされています。
ArchLinuxくん...
SysAd班では、これらVPSのOSにArchLinuxを採用しており、当時のカーネルバージョンは5.12.3-arch1-1でした(たぶん)。
ArchLinuxはUbuntuやCentOSと異なり、SimplicityやModernityの思想からパッケージのRolling releaseを採用しています。
-
Simplicity
- 不必要な追加や修正がないこと
- オリジナルの開発者(アップストリーム)によってリリースされたソフトウェアを、ディストリビューション(ダウンストリーム)特有の変更を最小限に抑えた状態で出荷する
- ディストリビューションのQAは最小限で、アップストリームによるテストを期待する
- アップストリームにrejectされたパッチは入らず、ディストリビューションによるパッチも、殆どは次のリリースに含まれる予定の修正で構成される
-
Modernity
- システム的なパッケージの破損が合理的に避けられる限り、最新のstable releaseに追従する
-
Rolling release
- Point releaseと対象的に、ソフトウェアのアップデートを頻繁に配信するリリースサイクル
Rolling releaseの利点は、細かな修正も頻繁に更新されることです。ディストリビューションのリポジトリから常に最新のカーネルと最新のソフトウェアリリースを入手できます。
一方で、これにより、新しいソフトウェアに予期しない問題が発生する可能性もあります。
これを避けるために、UbuntuやCentOSなどが採用しているPoint releaseでは十分なQAを実施しディストリビューション独自のパッチを当てたりします。
- 参考(2021/07/14)
- ArchLinux: 5.12.15
- Ubuntu LTS 20.04: 5.4.x, 5.8.x
- CentOS Version 8: 4.8.x
SysAd班では、最近、以前より頻繁にアップデートを反映するようになったせいか(†pacman -Syuu†)、kernelのバグを踏む頻度も高くなっていました。
S512(5.12.3-arch1-1)も例にもれず、slabが時間とともに肥大化する問題に悩んでいました。
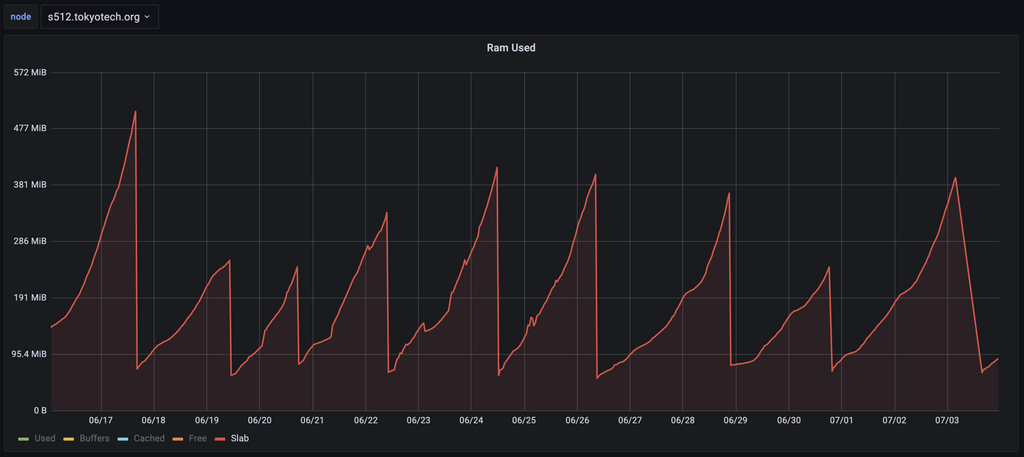
簡単な調査も行いましたが原因ははっきりせず、とりあえずパッチが当たるまでは、定期的に手でrebootをかける力技運用で対処していました。
しかし、memory usageのアラートが深夜帯に被ってしまうと、健康優良児の多いtraPでは誰も気づきません。7月3日、ついにmemoryを使い切ってインスタンスが動作しなくなるインシデントが発生してしまいます。
自動化しよう
こんな状態では夜もおちおち眠れません。労働は雑魚と誰かが言っていましたし、こういう単純作業は自動化しましょう。
とか思ってたら、メンバーが以下のようなserviceを書いてくれました。
内容は単純で、毎朝03:30に/sbin/systemctl rebootを実行するというものです。
/etc/systemd/system/daily_reboot.sevice
[Unit]
Description=Daily Reboot
[Service]
Type=oneshot
ExecStart=/sbin/systemctl reboot
[Install]
WantedBy=multi-user.target
/etc/systemd/system/daily_reboot.timer
[Unit]
Description=Reboot daily
[Timer]
OnCalendar=*-*-* 3:30:00
Persistent=true
[Install]
WantedBy=timers.target
パッと見た感じは問題なさそうです。
問題なさそうなので、そのまま本番環境に適用しました。
動作確認しよう
本番環境に適用する前には、必ず適切な動作確認をしましょう。
行けません、今から寝ます。
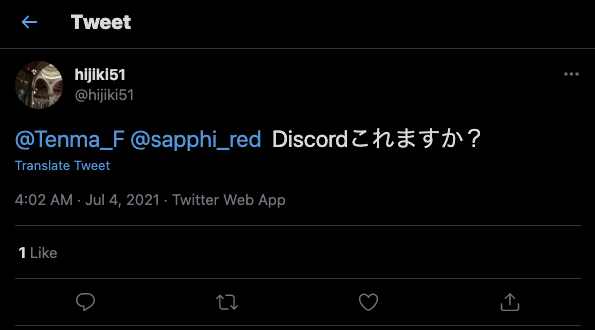
と、言うわけにも行かないのでDiscordに行くと「S512落ちてます」と言われました。
寝てもいいですか?
劇場版「鬼滅○刃」無限reboot編
何が、原因だったのでしょうか?
とりあえずGrafanaを見に行きます。
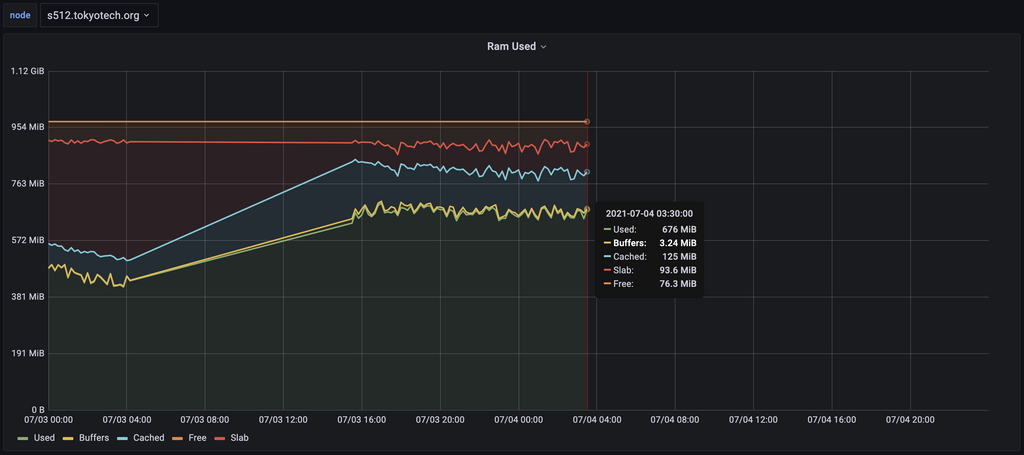
03:30...見たことのある数字だ...。
daily_rebootserviceが実行されるのがこの時間だったはずです。
しかし、再起動に30分もかかることは考えにくいです。
SSHもできないので、ConoHaのコンソールから再起動してみます。
しかし、起動しません。
一つ候補として、何らかの原因でrebootが繰り返されている場合が考えられます。
ConoHaはコンソールから、VPSのシリアルコンソールにアクセスできるので、見てみると確かにrebootを繰り返しています。
一体どんな記述が悪さをしているんでしょうか?
再度Unitファイルを確認してみます。
ドキュメントを残そう
S512にはアクセスできなかったので直接設定ファイルを確認することは出来ませんでしたが、daily_reboot導入時の背景や手順はwikiのopsに記録されていたため、確認が楽でした。
/etc/systemd/system/daily_reboot.timer
[Unit]
Description=Reboot daily
[Timer]
OnCalendar=*-*-* 3:30:00
Persistent=true
[Install]
WantedBy=timers.target
Persistent=trueこの記述が怪しそうです。
ドキュメントの説明を読んでみると、
When activated, it triggers the service immediately if it missed the last start time (option Persistent=true), for example due to the system being powered off
と書かれており、「起動時にサービスに設定されている時間を過ぎている && その一回が実行されていない」場合、その時間を待たずにすぐさま実行するようです。
つまり、今回は/sbin/systemctl rebootが完了扱いにならなかったことが原因で、Persistent=trueによって再度トリガーされていたわけです。
どうしよう
原因がわかったところでどうしましょう?
考えてみますが、このインスタンスを自力で復旧するのは難しそうです。
(ConoHaのシリアルコンソールからGnu GRUBを使用することはできましたが、その時はうまい方法を思いつきませんでした。いい方法を思いついた方は教えていただけると嬉しいです。)
俺を救ってくれるのはtwitterちゃんだけだよ💋
@Tenma_F システムがその他全部正常なら grub でブート時の cmdline に systemd.unit=emergency\.target で root ログインできます https://t.co/gmQcw6wN3S https://t.co/6UBcumyDDG
— そらは (@sora_h) September 12, 2021
仕方がないので新しいインスタンスを立てることにします。
インスタンスが立てば、Ansibleを実行するだけなので「まあ、すぐ復旧できるか」と思っていました。

おいおいおい、おいおいおいおい、おいおいおい。
ここで選択肢は3つです。
- 自分のアカウントで立てる
- S512を消して、立て直す
- ステージング用サーバーのアプリを止めて、そこにデプロイする
順当に「自分のアカウントで建てるか〜」と思いました、が、そういえばマネージドDBへのアクセスをプライベートネットワークに制限しています。
DBのアカウントはサービスごとに発行しているので、若干面倒だなと思いました。
面倒くさがらずに安全な方法を取ろう
1つ目の間違いです。どう考えてもアカウントの設定いじるほうが楽です。
俺くんのバカ!
SysAd班では安心してオペレーションできるように、殆どのデータのバックアップを取るようにしています。
かつて、バックアップが取られていないものを洗い出した際のissueを確認してみます。
「S512にローカルデータがあるよ」なんて記述はどこにもありません。
どうせ救えないS512だし消して良いやと思い、気持ちよく消しちゃいます。
さよなら、ありがとう、S512
バックアップは残しておこう
どれだけ考慮しても考慮漏れはあります。普段しないことをするときは、バックアップを極力残しておきましょう。
ちなみに、時間かかるから良いやって思ってイメージの保存をしなかったのですが(2つ目の間違い)、イメージをマウントすればローカルのファイルを吸い出せるのでしておくと良かったです。
何はともあれ。
さあ!インスタンス立てちゃうぞぉ〜〜〜〜!!

まあ、正直半分ぐらいは予想してました。(じゃあ、おとなしく自分のアカウントで立てとけと言う話ではあったね)
ステージング環境を止めてゴニョゴニョするぐらいなら、自分のアカウントで立てたほうが明らかに楽なんですが、インスタンスを消してしまった以上、ここで引いたら†負け†です😤
ゴニョゴニョやって、デプロイまで漕ぎ着けました。
ElasticSearchのインデックス構築を待って(1時間ぐらい)、起動を確認したら動作確認して就寝です( ˘ω˘)スヤァ
動作確認時には、ブラウザキャッシュを削除してファイル周りを重点的に確認しました。
投稿画像のサムネイルが欠けていましたが、ローカル保存ということは認識していたので問題なく、それ以外もうまく配信されているようでした。
最高の夜明け🌄

また、俺なんかやっちゃいました??
確認してたときは、動いてたんだけど?
もう駄目です、知りません。もっかい寝よっかな。
とか言いながら、メッセージを読み進めるとなんだか色々復旧してくれていそう。(ありがとう...ありがとう...)
サムネイルは時間がかかりますが再生成できるので再生成、スタンプ用の画像は以下のスクリプトでキャッシュから吸い出してすべて復旧出来ました。
ちなみに僕は寝る前の挙動確認時にキャッシュを消してるので1mmも力になれません、ごめんね。
ダンプ用スクリプト
const filesCache = await caches.open("files-cache");
function forceDownload(href, fileName) {
var anchor = document.createElement('a');
anchor.href = href;
anchor.download = fileName;
document.body.appendChild(anchor);
anchor.click();
}
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms))
}
const recoveredUsers = []
fetch("/api/v3/users?include-suspended=true").then((res) => res.json()).then(async (json) => {
try {
for (const user of json) {
const iconFileId = user.iconFileId;
filesCache.match(`/api/v3/files/${iconFileId}`).then((res) => res && res.ok && res.blob()).then((blob) => {
if (!blob) return
const fileReader = new FileReader();
fileReader.onload = function() {
forceDownload(this.result, iconFileId);
recoveredUsers.push(iconFileId);
}
fileReader.readAsDataURL(blob);
})
await sleep(1000)
}
} catch (err) {
console.log(err)
}
}).catch((err) => console.log(err))
const recoveredStamps = []
fetch("/api/v3/stamps").then((res) => res.json()).then(async (json) => {
for (const stamp of json) {
const fileId = stamp.fileId;
await filesCache.match(`/api/v3/files/${fileId}`).then((res) => res && res.ok && res.blob()).then((blob) => new Promise((resolve, reject) => {
if (!blob) reject()
const fileReader = new FileReader();
fileReader.onload = function() {
forceDownload(this.result, fileId);
recoveredStamps.push(fileId);
resolve()
}
fileReader.readAsDataURL(blob);
})).then(() => sleep(1000)).catch(() => {})
}
}).catch((err) => console.log(err))
チェック用スクリプト
const stamps = await(await fetch('/api/v3/stamps?include-unicode=false')).json()
const failed = []
for (const stamp of stamps) {
try {
const res = await fetch('/api/v3/files/'+stamp.fileId)
if (!res.ok) {
failed.push([stamp, res])
}
} catch (e) {
failed.push([stamp, e])
}
}
console.log(failed) // []
const users = await(await fetch('/api/v3/users?include-suspended=true')).json()
const failed = []
for (const user of users) {
try {
const res = await fetch('/api/v3/files/'+user.iconFileId)
if (!res.ok) {
failed.push([user, res])
}
} catch (e) {
failed.push([user, e])
}
}
console.log(failed)
問題はユーザーアイコン用の画像です。
現役ユーザーのアイコンはそれなりに残っていたのですが、すでに引退した人のアイコンはほぼ表示されないのでキャッシュにも残ってないです。
じゃあなくてもいいじゃんと思うかもしれませんが実はブログの筆者としては表示され続けるんですね...😢
ありがとう、でっていう。君のおかげだ、でっていう。
「でっていう」くんはtraPのメンバーです。
彼がユーザーのアイコンでモザイク画を作って、素材をすべて手元に保存しているなんてことをしていなければ、引退したユーザーのアイコンは救出できませんでした。
ちなみに、アイコンにはgifなども使用でき、mimeがDBに保存されています。でっていうくんの手元にはpngに変換されたものしか有りませんでしたが、救出できていなかったアイコンはすべて元からpngだったので晴れて完全復旧というわけです🥳
疑問点
なぜ再起動用のunitが完了扱いになっていなかったのか?
というか、Ubuntuでは期待したように動くのにArchでは実行済みにならないのか。
A. わかりません。わかる方教えて下さい。
なぜ動作確認時に正常に動いているように見えたのか?
これはなんとなく当たりが付いています。
traQではfile以下をServiceWorkerがキャッシュしているのですが、CacheStorageはHard Reloadでは消えないのでここを消し忘れたのかなと思います。
 traPtitech
traPtitech
再発防止
SysAd班ではこのようなインシデントが合った際にはポストモーテムを残すようにしています。
ポストモーテムには発生した事象・対応の時系列・一時的/最終的な対応・再発防止策・根本原因・対応の問題点などがまとめられています。
今回は再発防止のため、ローカルファイルをGCPにバックアップするスクリプトとそれを定期実行するsystemd unit、それをデプロイするansibleを書いてもらいました。
また、話の発端であるカーネルのバグについてはそもそもArchのメンテナンスコストが高いように感じたので全インスタンスをUbuntuに移行しました。
あといっぱい「対応の問題点」を書きました。
 traPtitech
traPtitechまとめ
夜は寝よう。
朝起きて対応しようね。
おやすみなさい。
明日の担当は @Uzaki くんです!楽しみ〜🥳