この記事は、夏のブログリレー2020 18日目の記事です。
導入
こんにちは、hukuda222です。本日は「ご注文はうさぎですか?」の宇治松千夜さんの誕生日です。おめでとうございます。
今回は、PyTorch( https://pytorch.org/ )のたまに使いたくなるけど、入門サイトとかに書いてなさそうな機能を紹介しようと思います。公式ドキュメント見ろって言われるとそれまでなんですが、隅々まで探すのは骨が折れるので。
v1.6.0に準拠しています。
本編
torch.scatter_add
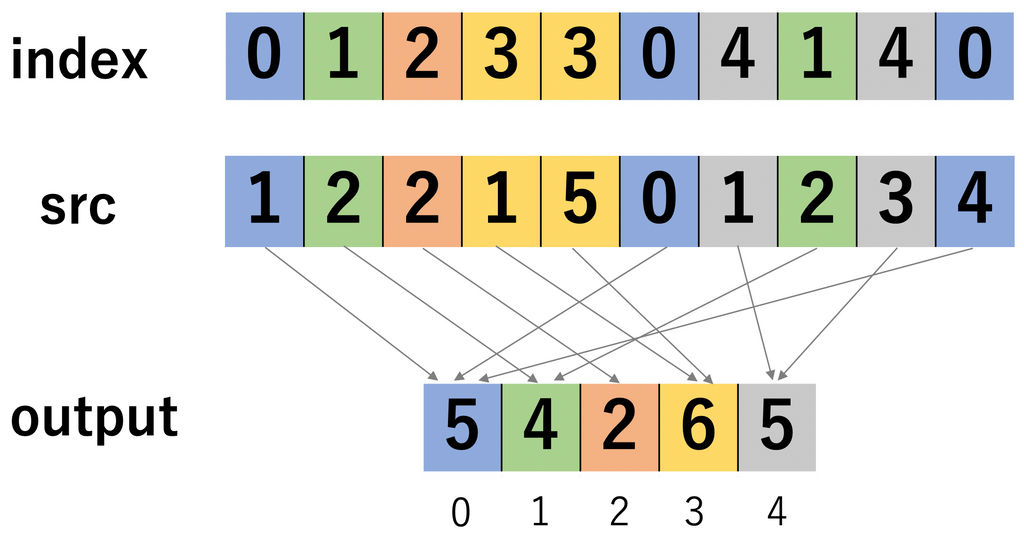
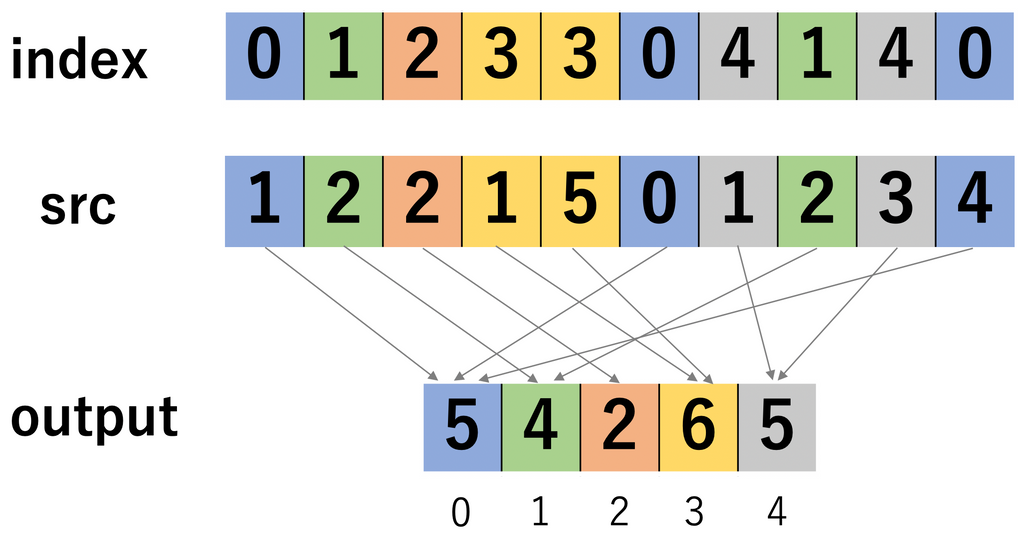
indexごとにsrcの値を合計する関数です。[公式ドキュメント]
以下のような挙動をします。
用途はいろいろあると思うのですが、僕が必要になったのはpointer-generator network( https://arxiv.org/abs/1704.04368 ) っぽいモデルを作ろうとした時です。要約文を生成するモデルなのですが、大雑把にいうと通常の生成だけではなく、入力文に含まれている単語をそのまま出力することができるモデルです。最終的に単語wを出力する確率$P(w)$は、
$$
P(w) = p_{gen}P_{vocab}(w)+(1-p_{gen})P_{copy}(w)
$$
となります。
$P_{gen}$:どのくらい生成する確率を優先するかのパラメーター
$P_{vocab}(w)$:ある単語wを生成する確率
$p_{copy}(w)$:入力に含まれている単語wをコピーする確率 (入力文に単語wが含まれてなければ0)
せっかくなのでやります。簡単のために語彙が8つのBrainf*ckみたいな言語を考えます。
>>> P_vocab = torch.softmax(torch.rand(1, 8),-1)
>>> P_vocab
tensor([[0.1418, 0.2004, 0.0820, 0.1168, 0.1110, 0.1073, 0.1145, 0.1262]])
>>> P_copy = torch.softmax(torch.rand(1, 5),-1)
>>> P_copy
tensor([[0.1451, 0.2350, 0.2080, 0.1963, 0.2157]])
>>> p_gen = 0.5
>>> input = torch.arange(5).unsqueeze(0)
>>> input
tensor([[0, 1, 2, 3, 4]])
>>> p_gen*P_vocab + (1-p_gen)*torch.zeros(1, 8).scatter_add_(1, input, P_copy)
tensor([[0.1435, 0.2177, 0.1450, 0.1566, 0.1634, 0.0536, 0.0573, 0.0631]])最後の$[0.1435, 0.2177, 0.1450, 0.1566, 0.1634, 0.0536, 0.0573, 0.0631]$が各語彙を出力する確率で、この場合だと2つ目の語彙を出力します。
ちなみにtorch.scatterは、同じindexが複数ある場合は、和をとるのではなく上書きします。そのため、図の例の場合はoutputは[4,2,2,5,3]になります。torch.scatterを使う機会はあんまりない気がします。
torch.einsum
テンソル積をいい感じに計算する関数です。使わなくても同じ処理を実装するのは可能ですが、他人のコードを読むために覚えておくと便利です。[公式ドキュメント]
第一引数は、同じテンソルの形状内で同じ記号が出ないように命名する必要があります。例えば、(5,5)のテンソル2つの積を計算する場合に、"aa,aa->aa"や"ab,ba->bb"というのはダメで、"ab,bc->ac"のようにする必要があります。
torch.diagonalとかtorch.permute, torch.nn.functional.bilinearとかもこれを使って書けますが、普通に書いた方が読みやすそうな気がします。
>>> A = torch.rand(1,2,3,4)
>>> B = torch.rand(1,3,2,4)
>>> C = torch.rand(1,3,4,2)
>>> D = torch.einsum("abcd,aebd,acdb->aecd",A,B,C)
>>> D.shape
torch.Size([1, 3, 3, 4])torch.nn.Bilinear
これはググっても出ないというよりも、torch.bmmとか使って書けるのでそもそもググらない気がします。[公式ドキュメント]
$x_1^tAx_2$を計算するのですが、計算の途中でブロードキャストするので初見だと「あれ、これどうなってるんだ?」ってなります。
>>> A = torch.nn.Parameter(torch.randn(3,5,4))
>>> l = torch.randn(2,5)
>>> r = torch.randn(2,4)
>>> f = torch.nn.Bilinear(5,4,3)
>>> f.weight = A
>>> f.bias = torch.zeros_like(f.bias)
>>> f(l,r)
tensor([[10.0714, -1.2443, -2.0329],
[ 4.4786, -4.1476, 1.0988]], grad_fn=<AddBackward0>)
>>> torch.bmm(torch.bmm(l.unsqueeze(0).repeat(3,1,1),A).permute(1,0,2),r.unsqueeze(-1)).squeeze(-1)
tensor([[10.0714, -1.2443, -2.0329],
[ 4.4786, -4.1476, 1.0988]], grad_fn=<SqueezeBackward1>)モデルのdeviceの取得
あんまり大した話じゃないんですが、Moduleオブジェクトに登録されているdeviceを取得する方法です。多分使わなくて済むように設計した方がいいです。
device_name = next(model.parameters()).device実数対称行列を半正定値行列に無理やり変換する
実数対称行列を半正定値行列に無理やり変換する方法です。固有値分解して、負の固有値を微小な正の値に変換しています。誤差が流れるので、いろいろな用途に使えます。しかし、torch.symeigは入力行列の固有値が全て異なっている場合でしか挙動が安定しないので、使い勝手はあんまり良くないです。
ちなみに、torch.eigは対称行列でなくても使えますが、誤差が流れないです。
>>> L=torch.rand(5,5)
>>> L = L + L.t()
>>> e, v=torch.symeig(L, eigenvectors=True)
>>> e
tensor([-0.5192, -0.3643, 0.1054, 0.8942, 2.3645])
>>> e=torch.clamp(e, min=1e-5)
>>> e
tensor([1.0000e-05, 1.0000e-05, 1.0536e-01, 8.9418e-01, 2.3645e+00])
>>> torch.matmul(v, torch.matmul(e.diag_embed(), v.transpose(-2, -1)))
tensor([[0.4396, 0.4224, 0.3879, 0.5366, 0.3979],
[0.4224, 0.5987, 0.1433, 0.5555, 0.6684],
[0.3879, 0.1433, 0.8694, 0.4065, 0.0529],
[0.5366, 0.5555, 0.4065, 0.6648, 0.5418],
[0.3979, 0.6684, 0.0529, 0.5418, 0.7914]])
>>> torch.einsum("ab,bc,cd->ad",v,e.diag_embed(), v.transpose(-2, -1))
tensor([[0.4396, 0.4224, 0.3879, 0.5366, 0.3979],
[0.4224, 0.5987, 0.1433, 0.5555, 0.6684],
[0.3879, 0.1433, 0.8694, 0.4065, 0.0529],
[0.5366, 0.5555, 0.4065, 0.6648, 0.5418],
[0.3979, 0.6684, 0.0529, 0.5418, 0.7914]])終わりに
ほとんど1つ目を書くつもりで書いたので2つ目以降はおまけです。scatter_addの日本語記事全然ないので、検索で上位に表示されないかなぁと思っています。
当初の予定では、「人間(僕)と事前学習してない機械翻訳器が、対等な条件で初見の自然言語をうまく翻訳ができるかを競う」みたいな企画を考えていました。しかし、僕が目を通せる翻訳対の量(めちゃくちゃ頑張って数千文)では翻訳器の方がまともな出力をしないので断念しました。
今回のブログリレーは緩めということで人が集まった日だけ記事が投稿されるらしいです。次は9/21のFogrexくんの記事です、お楽しみに。