この記事はtraP Advent Calendar2016 1日目の記事です
みなさん、こんばんはとーふとふ(@to_hutohu)です。
ついに始まりましたね!traP Advent Calendar2016
一年前に、受験生として去年のアドベントカレンダーを見ていた自分が、今こうして書く側になっていると思うとなんだか感慨深いですね。
今年は、部員も増えて一人一記事ずつ書いても一日2記事ずつの更新になります。
ぜひ楽しんでくださいね!!!
この記事でわかること
- Windows10でTensorflowを始める方法
- サンプルプログラムCifar10を動かしてみる方法
- Cifar10を改造して自分用の画像分類機を作る方法
この記事を書いた人
とーふとふ
大学一年生で機械学習は11月に入ってから初めて触りました。
プログラミング自体も本格的に始めたのは大学に入ってからです。
この記事の目標
Tensorflowのチュートリアルの一つであるcifar10を改造して、自分で用意した画像セットで訓練し、画像分類機を作ることです。
機械学習を始めるモチベーションとしてよくあるものが、画像を分類したい!ということだと思います。
そこで色々ググってみたのですが、なかなかこのチュートリアルを実行する第一歩から自分でモデル(学習するプログラムの構造のようなもの)を構築する独り立ちまでの間を詳しく書いた記事があまりなかったので、ここに自分の奮闘をまとめます。
少しでも皆さんが機械学習に挑戦するときの手助けになりたいと思っています。
環境
今回は多くの人が使っているであろうWindows10で、Bash on Ubuntuを用いてTensorflowの環境を構築していきます。
さらに、簡単のためにCPU版のTensorflowをインストールします。
もし、GPU版をインストールしたい場合はこちらなどを参考にすると良いと思います。
http://ill-identified.hatenablog.com/entry/2016/08/11/204205
(Bash on UbuntuでGPUの利用は難しいようです。Linuxをインストールしてください)
(12/1 追記 この記事を書いたのは11月の半ばなのですが、タイミングがいいのか悪いのかTensorflowのバージョンアップが来ました。 r0.11 -> r0.12
今回変更するコードには支障はありませんが、ダウンロードするURLなどは適宜読み替えてください!!
しかもWindowsでTensorflowがサポートされたらしいですね!!!なんと間の悪い!!!)
TensorflowのインストールができればMacやLinuxでもTensorflowのコードは同じように動くので、参考になると思います。
それでは早速はじめていきましょう
Bash on Ubuntuの設定
Windows10ではBash on Ubuntuという機能を利用することで、Windows上でUbuntuのコンソールを実行することができます。
起動するために多少設定が必要です。
スタートボタンを右クリックして、プログラムと機能をクリックします。
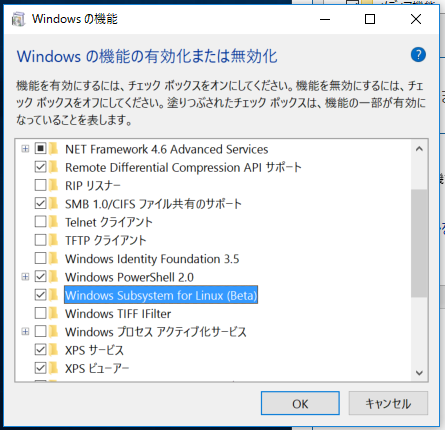
Windowsの機能の有効化と無効化→Windows Subsystem for Linuxを選択しOKを選択します。
インストールが始まるので待ちましょう。(再起動が必要です)
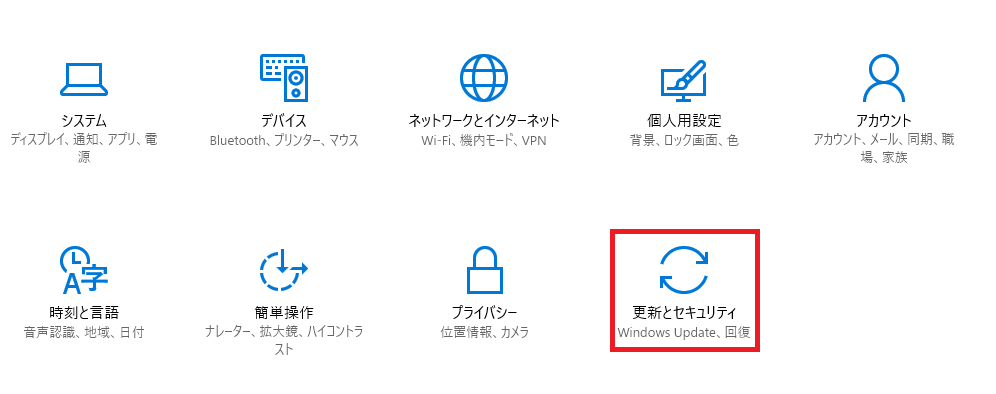
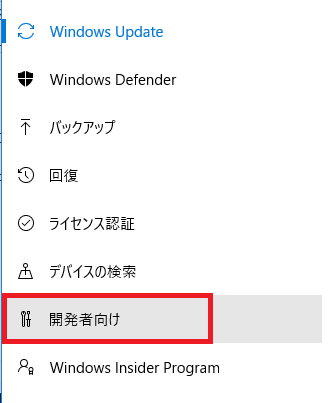
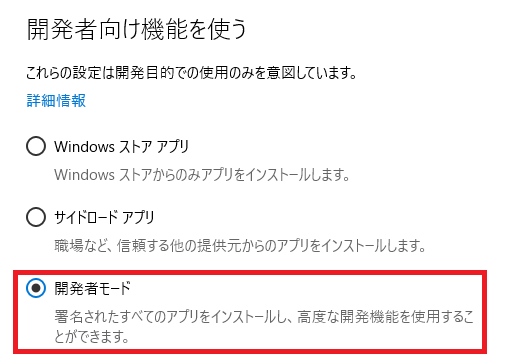
再起動したらスタートボタン→設定→更新とセキュリティ→開発者向けに行き、開発者モードを選択します。
コマンドプロンプトを起動して、
bash
を実行します。
途中でパスワードを設定するよう求められます。
これは、このあとsudoコマンドを実行するために必要になってくるので適切に設定してください。
インストールが終わると、Bash on Ubuntu on Windowsがスタートメニューに追加されます。
これ以降はBash on Ubuntu 上での作業となります。
Tensorflowのインストール
それではTensorflowをインストールしていきます。
既存パッケージのアップデート
初めに
$ sudo apt update
$ sudo apt upgrade
をしておきましょう。
デフォルトで入っているソフトが最新になります。
pyenvのインストール
pythonのバージョン管理ツールであるpyenvをインストールします。
pyenvをインストールするためにはgitが必要です。
下のコマンドを順に実行してください。
$ sudo apt install git
$ git clone https://github.com/yyuu/pyenv.git ~/.pyenv
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc
$ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
$ echo 'eval "$(pyenv init -)"' >> ~/.bashrc
$ source ~/.bashrc
Anacondaのインストール
pythonのパッケージ管理ツールであるAnacondaをインストールします。
$ pyenv install --list | grep ana
最新のAnacondaを確認 書いた時点ではanaconda3-4.1.1
$ pyenv install anaconda3-4.1.1
Anacondaを使うように設定
$ pyenv global anaconda3-4.1.1
$ pyenv rehash
Tensorflowのインストール
いよいよ本丸です。
$ conda install -c conda-forge tensorflow
これだけ
Hello, World
お約束のHello, Worldをやりましょう
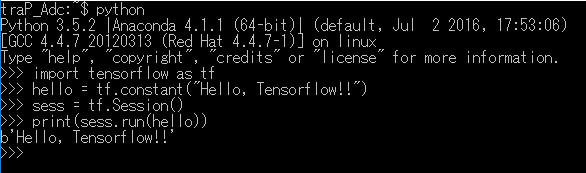
がついているところが自分で書くところです。
1行目でtensorflowをインポートしています。
2行目で文字列を定義し3・4行目で実行出力しています。
プログラムの書き方はまだわからなくても大丈夫ですが、ちゃんとb'Hello, Tensorflow!!'と出力されることを確認してください。
サンプルプログラムCifar10を動かす
ここからTensorflowで画像を学習させていきます
今回はCifar10というデータセットを学習するサンプルプログラムを使います。
ソースはGitHubに公開されています
https://github.com/tensorflow/tensorflow/blob/r0.11/tensorflow/models/image/cifar10/
※注意:ここまでの手順でTensorflowをインストールすると2016/11/18現在バージョンr0.11がインストールされます。
Googleで「Cifar10 Tensorflow」でググるとリポジトリが出てきますが、masterブランチのコードではエラーが出て実行することができません。
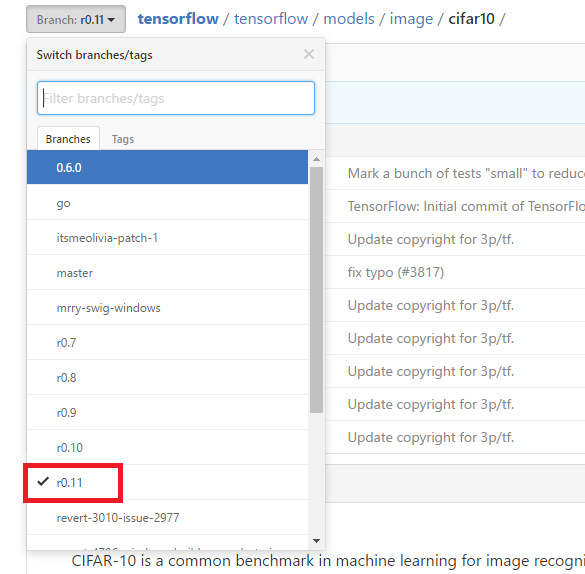
左上のブランチ選択からr0.11を選択するようにしましょう。(上のリンクはr0.11が選択された状態になっています)
必要なファイルのダウンロード
学習に必要なファイルのダウンロードをします。
今後のためにデスクトップ直下にフォルダを作りその中で作業をしていきたいと思います。
$ cd /mnt/c/Users/ユーザー名/Desktop
$ mkdir cifar10
$ cd cifar10
$ curl https://raw.githubusercontent.com/tensorflow/tensorflow/r0.11/tensorflow/models/image/cifar10/cifar10_train.py -o cifar10_train.py
$ curl https://raw.githubusercontent.com/tensorflow/tensorflow/r0.11/tensorflow/models/image/cifar10/cifar10_eval.py -o cifar10_eval.py
学習
$ python cifar10_train.py
を実行することで、/tmp/に訓練データがダウンロードされ学習が開始されます。
ただし、とにかく時間がかかります。
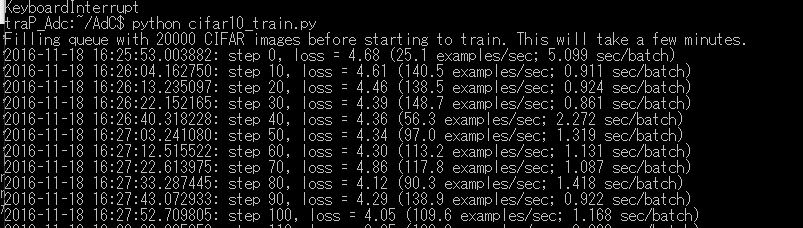
私の環境だと10stepに大体十秒かかっているので、デフォルトの設定である100万stepをこなすためには約4か月かかってしまいます。
ちょっと早く終わるようにしてみましょう。
このプログラムでは、実行時にオプションを設定することで学習回数や一度に学習する画像の数を設定することができます。
- --batch_size={number} 1stepで学習する画像の数 デフォルト:128
- --max_steps={number} 何stepの間学習するか デフォルト:1000000
処理される分量はだいたい batch_size × max_steps です。
つまりこんな感じ
$ python cifar10_train.py --batch_size=64 --max_steps=1000
ここは自分の時間とPCのスペックによって変更するようにしてください。
評価
学習をしたモデルを使って評価用の画像を判定させてみましょう。
$ python cifar10_eval.py
を実行することによって、上の学習の結果を用いてテストをすることができます。
デフォルトでは5分ごとに実行されるようになっているので、おそらく学習と並列して実行することを想定されているのだと思います。
こちらのプログラムにもオプションが用意されています。
- --eval_interval_secs={number} 何秒ごとに実行するか デフォルト:300
- --num_examples={number} 一度のテストで使う画像数 デフォルト:10000
- --run_once={boolean} テストを連続で行うか デフォルト:True
- Falseにした場合eval_interval_secsの値は関係ない
可視化
TensorflowにはTensorboardという強力な可視化ツールが付属しています。
今回は/tmp/cifar10_train と /tmp/cifar10_evalにログが保存されているので
$ tensorboard --logdir=/tmp/
として実行するとサーバーが起動します。
サーバーが起動したあと、アドレスが表示されるのでそこにブラウザでアクセスします。
(ポートは6006で固定のようですが、127.0.0.1:6006 の場合と localhost:6006 の場合があるようです)
コラム:cifar10のtensorboardの見方(書けるか?)
自分で用意した画像で教師データを作る
さて、サンプルプログラムを実行できました。
でも私がやりたかったのはあらかじめ用意された、飛行機とか馬とかの画像を分類することではなくて自分で決めた分類の仕方で画像を分類することです!!
それではそこを目指して頑張っていきましょう。
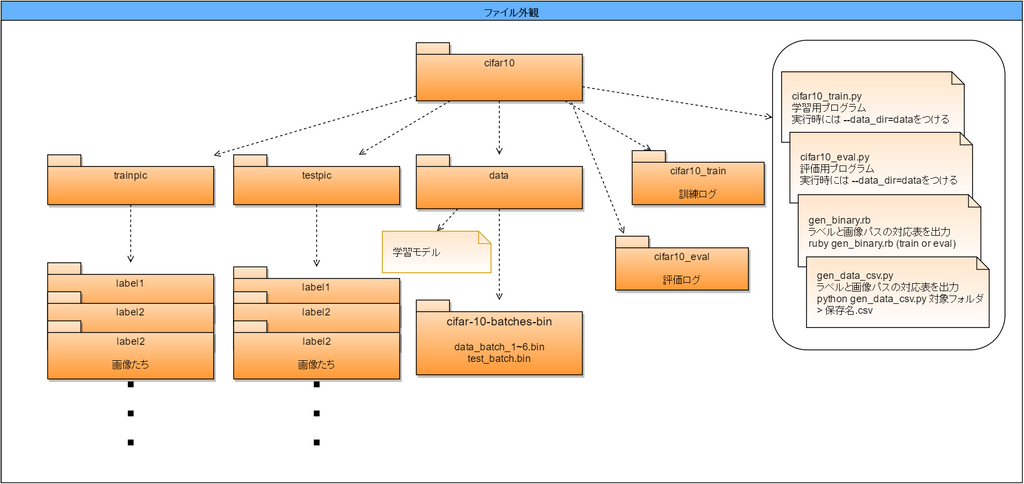
Cifar10のデータ構造
自前で訓練データを準備するためには訓練データの構造を理解しなければなりません。
その構造がこちら
Binary version
The binary version contains the files data_batch_1.bin, data_batch_2.bin, ..., data_batch_5.bin, as well as test_batch.bin. Each of these files is formatted as follows:
<1 x label><3072 x pixel>
...
<1 x label><3072 x pixel>
In other words, the first byte is the label of the first image, which is a number in the range 0-9. The next 3072 bytes are the values of the pixels of the image. The first 1024 bytes are the red channel values, the next 1024 the green, and the final 1024 the blue. The values are stored in row-major order, so the first 32 bytes are the red channel values of the first row of the image.Each file contains 10000 such 3073-byte "rows" of images, although there is nothing delimiting the rows. Therefore each file should be exactly 30730000 bytes long.
…はい、わかりませんね。
つまりこんなイメージ

これがずっと羅列されていく感じですね。サイズは32×32です。
改行はありません。
それではこのファイルを作るために準備をしていきましょう
必要なソフトのインストール
今回は画像ファイルの変換をrubyのrmagickを使って行います。
上から順番に実行していけばエラーなく実行できると思います。
ruby ruby-dev
$ sudo apt install ruby ruby-dev
make
$ sudo apt install make
imagemagick 及び外部からいじるために必要なライブラリ
$ sudo aptitude install&nbsp;imagemagick libimagemagick libmagickcore libmagickcore-dev libmagickwand-dev
これだけはaptitudeで実行しなければいけません。
結構時間がかかります。
rmagick
$ sudo gem install rmagick
フォルダ構造から画像パスとラベルを対応させたcsvファイルを作る
今回は画像の置いてあるフォルダの位置からラベルを対応させるようにしましょう。
ソースコードはこちら
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
import os
if __name__ == '__main__':
outdir = sys.argv[1]
if not os.path.isdir(outdir):
sys.exit('%s is not directory' % outdir)
names = {
"label0": 0,
"label1": 1
#最大10個まで設定できます。画像の置いてあるフォルダーを記入してください。
}
exts = ['.JPG','.JPEG']
print("path,value")
for dirpath, dirnames, filenames in os.walk(outdir):
for dirname in dirnames:
if dirname in names:
n = names[dirname]
member_dir = os.path.join(dirpath, dirname)
for dirpath2, dirnames2, filenames2 in os.walk(member_dir):
if not dirpath2.endswith(dirname):
continue
for filename2 in filenames2:
(fn,ext) = os.path.splitext(filename2)
if ext.upper() in exts:
img_path = os.path.join(dirpath2, filename2)
print ('%s,%s' % (img_path, n))
13行目~のnamesの場所は適宜変更してください。
例えば下の画像のようなフォルダ構造の場合
name = {
"cocoro":0,
"Notcocoro":1
}
という風にします。(連番で設定してください)
最大10種類まで指定可能です。
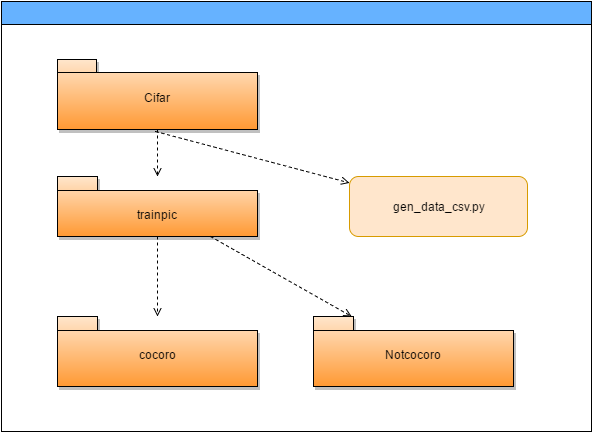 実行時の第一引数に指定された、フォルダの下のフォルダを順に回ってラベルと対応させ、出力していくのでそれをcsvファイルとして保存しましょう。
実行時の第一引数に指定された、フォルダの下のフォルダを順に回ってラベルと対応させ、出力していくのでそれをcsvファイルとして保存しましょう。
具体的には下のコマンドを実行します。
$ python gen_data_csv.py trainpic > train.csv
画像を読み込んでバイナリ形式に変換する
ソースコードがこちら
ファイル名はgen_binary.rbとしています。
require 'csv'
require 'rmagick'
require 'fileutils'
SIZE = 32
BIN_DIR = './data/cifar-10-batches-bin/'
if(ARGV[0] == 'train')
csv_data = CSV.read('train.csv', headers: true)
else
csv_data = CSV.read('eval.csv', headers: true)
end
puts "start..."
file = String.new
csv_data.each do |data|
buf = String.new
puts data
buf << [data[1].to_i()].pack('C')
img = Magick::Image.read(data[0]).first.resize(SIZE,SIZE)
%w(red green blue).each do |color|
img.each_pixel do |px|
buf << [px.send(color) >> 8].pack('C')
end
end
file << buf
end
FileUtils.mkdir_p(BIN_DIR) unless FileTest.exist?(BIN_DIR)
if(ARGV[0] == 'train')
File.binwrite(BIN_DIR + "data_batch_1.bin", file)
File.binwrite(BIN_DIR + "data_batch_2.bin", file)
File.binwrite(BIN_DIR + "data_batch_3.bin", file)
File.binwrite(BIN_DIR + "data_batch_4.bin", file)
File.binwrite(BIN_DIR + "data_batch_5.bin", file)
File.binwrite(BIN_DIR + "data_batch_6.bin", file)
else
File.binwrite(BIN_DIR + "test_batch.bin", file)
end
このコードはすぎゃーんさんのコードを参考にさせていただきました。
このコードでは第一引数としてtrainを指定するとtrain.csvを、それ以外の場合はeval.csvを読み込んでバイナリーを./data/cifar-10-batches-bin/に生成します。
ソースコードの流れとしては、指定されたcsvファイルを読み込んで、順番にファイルを処理していっています。
23行目で8個ビットシフトしているのは、imagemagickではRGB各色を16ビットで保持しているからです。
(imagemagickのインストールオプションで変更できるようですが…)
実際のcifar10のデータではそれぞれのファイルの中身は異なるのですが、
これでも問題はないのでこのような手抜きをしています。
訓練データを作るときは第二引数をtrainとし、評価用データを作るときは引数無しで実行します。
ソースコードの修正
ここまでで用意してきた、学習データを読み込ますためにソースコードをちょこっとだけ修正します。
cifar10_train.py
50行目あたり:tf.app.flags…の上の行に
cifar10.NUM_CLASSES = {設定した分類数}
を追加し、その下にあるtrain_dirの指定を"/tmp/cifar10_train"から"./cifar10_train"に変更します。
127行目:main関数の一番初めの処理である
cifar10.maybe…の行をコメントアウトします。
cifar10_eval.py
48行目付近:tf.app.flags…の上の行に
cifar10.NUM_CLASSES = {設定した分類数}
その下にある、
eval_dirの指定を"/tmp/cifar10_eval"から”./cifar10_eval”へ
checkpoint_dirの指定を"/tmp/cifar10_train'"から"./cifar10_train'"へ変更します。
(logと評価モデルの保存位置の変更)
151行目:main関数の一番初めの処理である
cifar10.maybe…の行をコメントアウトします。
(cifar10のデータのダウンロードをさせない)
実行
実行時には、どちらのファイルもオプションとして --data_dir=train を指定するようにしてください。
これで自分用の画像分類機ができました!!!!
すごい!簡単!
ここまでのまとめ
ここまでごちゃごちゃとやってきたので学習する流れをまとめてみましょう。
フォルダの構成は画像の通りです。

1.画像の準備
教師用と評価用の画像を準備します。
数はできるだけ多くあったほうがいいです。
1種類100枚ほどはないとどうにもならないと思います。
一度環境が整うとここが一番大変な作業になるかもしれません。
2.画像の分類
画像を各種別に分類し、適切なフォルダに置きます。
3.バイナリデータの作成
gen_data_csv.pyおよびgen_binary.rbを実行してバイナリデータを作成します
$ python gen_data_csv trainpic &gt; train.csv
$ python gen_data_csv testpic &gt; eval.csv
$ ruby gen_binary.rb train
$ ruby gen_binary.rb eval
4. 学習&評価
$ python cifar10_train.py --data_dir=data
$ python cifar10_eval.py --data_dir=data
普通のjpegファイルから予測をする
画像分類機を作って、その精度の評価をすることができるようになりました。
しかし、現状では予測をさせるために毎回バイナリファイルを作らなければなりません。
めちゃくちゃ面倒ですね。
次はjpegファイルを読み込んで、予測した結果を出力することを目標に進めていきましょう。
これが達成できれば、外部から利用することも簡単になります。
そこで書いたコードがこちら。
import sys
import tensorflow as tf
from tensorflow.models.image.cifar10 import cifar10
FLAGS = tf.app.flags.FLAGS
cifar10.NUM_CLASSES = 2 //自分で設定したクラス数にしてください
tf.app.flags.DEFINE_string('checkpoint_dir', './cifar10_train',
"""Directory where to read model checkpoints.""")
def evaluate(filename):
//filename:画像ファイルのパス
with tf.Graph().as_default() as g:
jpg = tf.read_file(filename)
image = tf.image.decode_jpeg(jpg, channels = 3)
image = tf.image.resize_images(image, [32,32])
image = tf.image.resize_image_with_crop_or_pad(image, 24, 24) //cifar10は内部処理で32×32を24×24に切り出して利用している
logits = cifar10.inference([image])
top_k_op = tf.nn.top_k(logits,k=2)
//ここのkの値もクラス数と一致させるようにしてください
saver = tf.train.Saver()
sess = tf.InteractiveSession()
sess.run(tf.initialize_all_variables())
ckpt = tf.train.get_checkpoint_state(FLAGS.checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
else:
print('No checkpoint file found')
return
tf.train.start_queue_runners(sess=sess)
values, indices = sess.run(top_k_op)
ratio = sess.run(tf.nn.softmax(values[0]))
//予想したラベルとそれぞれに対する確信度
print(indices[0])
print(ratio)
def main(argv=None):
evaluate(sys.argv[1])
if __name__ == '__main__':
tf.app.run()
こころ判定Botを作った
以上の方法を使ってこころ判定Botを作りました。
こんな感じ
@to_hutohu pic.twitter.com/4jxUBZAvDj
— うぃにおん (@UMA76343951) November 28, 2016
こうやってTweetすると
Did you go Cocoro?
cocoro
0
[ 9.99920011e-01 7.99999980e-05]
cocoro sonota
99.97% 0.03%https://t.co/mk0o29QLvM— 四号成長中 (@to_hutohu) November 28, 2016
こんな感じで判定することができます。
英語がガバガバなのはネタです(見逃して…)
TLにはNodejsでStreaming接続してその画像ファイルのパスを渡して予測させ、その結果をNodejs側で標準出力で受け取って結果次第で、ツイートするといった構造になっています。
次のステップへ
CNNの理解をする
Convolutional Neural Networkとは何なのか - Qiita
誤差逆伝播法をはじめからていねいに - Qiita
畳み込みニューラルネットワークの仕組み | コンピュータサイエンス | POSTD
最適化手法を変えて性能を比較する
CNNの学習に最高の性能を示す最適化手法はどれか - 俺とプログラミング
気をつけたいポイント
バージョンには気をつけよう!!!
Tensorflowではバージョンによって大きく違いがあり、自分が今見ているコードがバージョンいくつなのかを意識しないといけません。
例えば、変数を初期化する関数があります。それがr0.11からr0.12でこう変わりました。
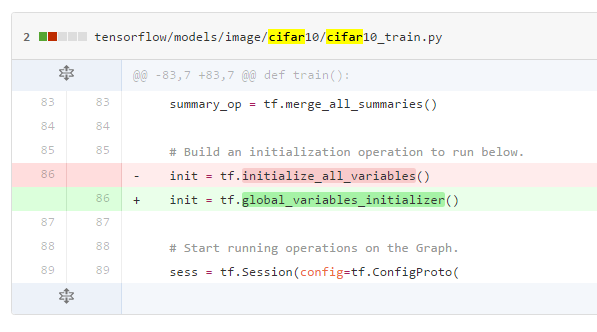
その他にも多くの汎用的な関数の名前や機能が変わっているようです。
これから、Tensorflowを始める人はr0.12を導入すると思うのですが、現在ネット上にあるコードの殆どがr0.11以前のものなので、コピペして動かない!!!とかになったら 公式ドキュメントで確認するようにしましょう。
まとめ
非常に非常に長い記事になってしまいました。
原理がよくわかってなくても、学習が進むごとに精度が上がっていく様子を見るのはとても楽しいものです。
そこで、なんでこんな挙動をするのだろうという疑問から原理のほうに進むのも一つの道ではないのかなあと思います。
明日はSaltnとsigmaの記事です
Saltnはサウンド・企画 sigmaはデザイン・グラフィック・プログラマーのメンバーです。
コラム:Bash on Ubuntu のフォルダ構造は?
Windowsから見たルートディレクトリ
非常に見つけづらい場所に設置されています。
C:\Users\ユーザー名\AppData\Local\lxss
です。
ただし、C:\Users\ユーザー名\AppData\Local にアクセスしてもダメなんですねー
隠しフォルダを表示するようにしていても、見つけることができません。
エクスプローラーのアドレス欄に直に書き込んでください。
Bashから見たWindowのフォルダ
各ドライブが /mnt/ にマウントされています。
例えば、デスクトップに移動するならば、
cd /mnt/c/Users/ユーザー名/Desktop
最適化手法を変更する方法
一回目はちょっと面倒ですが、二回目以降はめちゃくちゃ簡単です。
1回目の準備
cifar10.pyのダウンロード
毎度のことですが、GitHubのTensorflowのサンプルコードをダウンロードします。
$ curl https://raw.githubusercontent.com/tensorflow/tensorflow/r0.11/tensorflow/models/image/cifar10/cifar10.py -o cifar10.py
cifar10_train.pyの変更
最初の
from tensorflow.models.image.cifar10 import cifar10
を
import cifar10
に書き換えます。
cifar10.pyの変更
上のほうにある、tf.app.…で始まる行をすべて削除します。
変更部分
ここからが最適化手法を書き換えるところです。
https://www.tensorflow.org/versions/r0.11/api_docs/python/train.html
ここを参考にして
cifar10.pyのtrain関数内の
opt = tf.train.GradientDescentOptimizer(lr)
の~~Optimizerを書き換えてください。
たったこれだけで最適化手法が変わります。