
これは2019年度新歓ブログリレー5日目の記事です。
つかみ
こんにちは、誰かの誕生日にしか記事を書けないことに定評のあるhukuda222です。はい、本日3/13は「ご注文はうさぎですか?」の保登モカさんの誕生日です。
おめでとうございます!今年は新作OVA、来年はアニメ第三期とごちうさから目が離せませんね!

さて、モカさんは作中では主要キャラの姉貴分として振舞っています。そこで今回は僕も先輩ぶって、どこの研究室に行くか迷ってるB2,3の方や、自分の興味を持てる分野を探している新入生の方に向けた記事を書こうと思いました。
導入
(※ここから本編です)
皆さんは自然言語処理という分野をご存知でしょうか。
我々が普段使っている日本語や英語といった自然言語をいい感じにコンピュータで扱う技術です。
Natural Language Processing(NLP)とも呼ばれます。
具体的には、形態素解析(文章を単語で分割して品詞などを決める)、構文解析(係り受けなどを決める)、意味解析(その文章の意味を推測する)、文脈解析(前後の文脈を考慮する)という4つのステップによって行われます。
深層学習といえば、見た目が鮮やかな画像生成や、わかりやすくて面白いゲームAIの強化学習を思い浮かべる方も多いと思いますが、自然言語処理も深層学習の恩恵を受けて、大きく発展しました。
深層学習の恩恵によって、形態素解析や構文解析はかなり高い精度で行えるようになりました。
さらに、多様な手法によって分野ごとに適した意味解析、文脈解析を行えるようになってきています。
どんなことするの?
どんな分野で自然言語処理が使われているのかを大雑把に並べてみました。書いてないものもたくさんあります。
翻訳
自然言語処理の花形です。
ある言語Aの文章を入力として、別の言語Bの文章を出力します。
毎年多くの論文が公開され、現時点での最高精度と言う意味で使われるSOTA(State of the Art)は日々更新されています。
上のツイートは古いバージョンのもので、最新のgoogle翻訳はもっとうまく訳してました。来年から年賀状の文面が変わりますね! pic.twitter.com/jb6AyJP4eT
— フクダ (@hukuda222) November 11, 2016
要約
長い文章を入力として、内容の要旨を損ねない短い文章を出力します。
不必要な文全体や文の一部を切り取る方法と、要約文そのものを生成する方法があります。
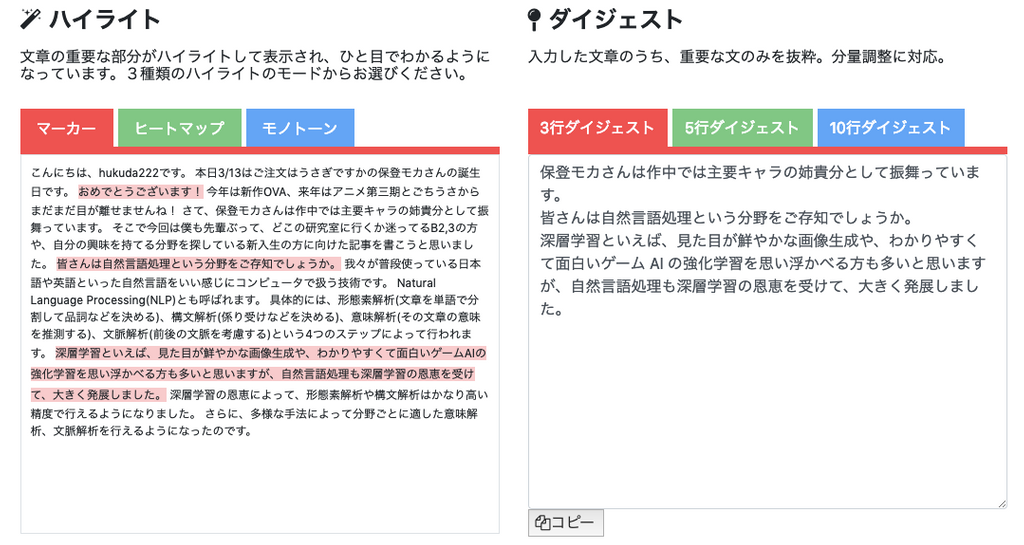
少し前にtwitterで流行ったような気がする無料の要約サービスです。これは重要そうな文章を直接抜粋するタイプのようです。
https://text-summary.userlocal.jp/
質問応答
事前に与えられた情報から入力された質問文の回答を出力します。
7年くらい昔ですが、IBMのワトソンがめちゃくちゃ有名だと思います。
米国の人気クイズ番組「Jeopardy!」に挑戦して優勝しました。これはその時の動画のようです。
https://www.ibm.com/watson/jp-ja/quiz/index.html
対話
質問にただ答えるのとは違って、正解のある質問以外の入力に対しても自然な応答を出力します。
Elizaやりんなちゃんなどが有名だと思います。
個人的に一番興味がある分野です。しかし、対話は正解かどうかの判断を人が行う必要があるとされているため、うまくいっているかの評価がとても難しいです。
ある入力に対して選択肢(4個とか100個とか)が与えられ、その中のどれが正解かを選ぶというタスクや、対話のログを入力として応答が破綻しているかどうかを判断するタスクもあります。
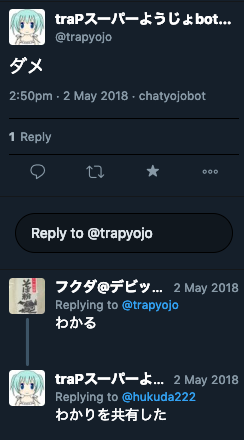
上の画像は、僕も制作に関わったチャットボットです。改良の余地が山積みなのでそのうち解消したいです。
分類
実際に社会で多く使われている分野です。
ある単語や文字列が、ネガティブかポジティブかを判定するネガポジ判定などもここに入ると思います。
ニュース記事を入力としてカテゴリを分類したり、多種多様なタスクがあります。
https://www.kaggle.com/jhoward/nb-svm-strong-linear-baseline
上記の記事では、wikipediaの害意があるコメントをどのようなタイプに属するか推定しています。
出てきた単語の種類と数を数えて分析しているだけなのですが、0.97以上のスコアが出ているらしいです。(このコンペティション優勝者のスコアが0.988くらいなのでかなり高いです)
必ずしも複雑な手法の方が高い精度が出るという訳ではないのですが、分類問題はそれが如実に出るような気がします。
で?
いや、面白くないですか?
SAOのユイやドラえもん、長門有希みたいな対話するシステムの実現に必要不可欠なのは自然言語処理です。
twitterのツイート分析みたいなのにも、あるアカウントのツイートから良い感じの特徴量を作るところで自然言語処理が使われています。
Google翻訳も自然言語処理ですし、yahooニュースのコメントの表示順を良い感じに並び替えてるのも自然言語処理らしいです。
ロボットがセンター試験でかなり良い成績をとったのが少し前に話題になりましたが、問題文を理解するのに使われるのはもちろん自然言語処理です。
最初の一歩的なサムシング
さて、ここまで読んだ方なら自然言語処理をしたくて辛抱たまらん状態になっていると思います。良さげな最初の一歩をいくつか紹介します。プログラミング言語Pythonの文法を一応把握してるくらいのレベルを想定しています。Pythonが優れた言語であるかは賛否両論あると思いますが、一番情報が出回ってるので素直に使うのが良いと思います。
自然言語処理100本ノック
http://www.cl.ecei.tohoku.ac.jp/nlp100/
東北大の乾・鈴木研究室の乾先生が作られた、自然言語処理を実践的に学べる問題集です。Pythonを使って実行することを想定されていますが、Rやjuliaなどライブラリが充実している言語なら解けると思います。
基本的な文字列の扱いから入り、正規表現やDB、Mecab、Cabochaの使い方、基本的な特徴量の作り方や分類手法の実装などが一通り網羅されています。一方で、近年の自然言語処理の論文で大きな割合を占めている、深層学習を用いた諸々の実装には触れていません(間接的に深層学習を利用するライブラリは使いますが)
全部やってもいいですが、量が多いので面白そうなところや、「こういうことをやりたいけど、どうすればいいんだろう」となった部分だけやれば良いと思います。
ググると誰かしらが書いたすべての問題の解答が見つかるので詰まることは少ないと思います。
PyTorch 1.0 Tutorials : テキスト
http://torch.classcat.com/2018/12/11/pytorch-1-0-tutorials-text-nlp-pytorch/
PyTorchは深層学習のPython向けフレームワークです。
海外だと自然言語処理の分野ではTensorFlowというフレームワークがよく使われるようですが、日本ではPyTorchがよく使われるらしいです。
どんなフレームワークを使っても良いですし、使わなくても良いですが、たくさんの人が使っているフレームワークを使った方がアドバイスを受けやすいですしググった際の情報量が多いです。個人差はあると思いますがPyTorchの方が直感的で楽なのでオススメです。
このページは公式チュートリアルを翻訳・修正したもので、PyTorchの基本的な使い方から始まって、品詞推定、文字レベルの文字列生成・分類、文字列分類、翻訳などの解説がされています。
数学
実は私は入学当時、自然言語処理系の研究室の教授に「自然言語処理したいんですけど、どんなこと勉強すれば良いですか?」という趣旨のメールを送ったことがあります。
返信は「深層学習の知識がどうしても必要になってくるので、数学、特に線形代数を重点的に勉強してね」というものでした。
僕自身の経験が浅いのでどの程度の知識がいるのか断言はできませんが、行列計算を独力でできるくらいの知識は必要だと思います。そのような計算をしてくれるライブラリは巷に出回っていますが、適切に使えているかを確認するために自分で計算できるに越したことはありません。うまく使えてないのが原因でエラーが出たりうまく動かなかったことが何度もありました。
英語
英語の記事や論文を参考にする機会も出てくるので読めるに越したことはありません。
僕は英語がとても苦手なので現在進行形でとても苦労しています。
終わりに
どんなことでもいいですが、大学の講義以外でも興味をあることをやっていると充実した大学生活が送れると思うので、興味がある人は何かやってみてはいかがでしょうか。
明日の記事の担当はnariさんです。乞うご期待!