
こんにちは。23Mの@mazreanです。SysAd班でtraP Collectionというアプリケーションのバックエンドの開発・運用などを行なっていました。
ISUCONにはISUCON9から出ており、ISUCON11で本戦に出場していました。ISUCON12からは色々独自ツールを使って戦ってみたかったので、気楽に独自ツールを入れられる1人チームで出ています。
ISUCON14にも1人で「INUCON 14(いい感じに猫を動かすコンテスト ワン!亖ャー)」として参加しており、最終スコアfail、最高スコアが26,710点ぐらいで惨敗しました…
この記事で紹介するツール群は、一昨年から3回のISUCONを経て完成形になった環境です。LLMの使い方などもかなり面白いものになっていると思うので、ISUCONに出ていなかった人でもツール関連の部分は是非読んでみてほしいです。
また、感想戦で40万点超えた(おそらく現時点で最高スコア)解説記事も同時に公開しているので、是非そちらも読んでみてください。
独自ツール群
このツール群全体で「典型的なパフォーマンス改善を自動でできる」ようになっています。
ISUCONは基本的に最初1時間程度で計測ツールのセットアップや、MySQL、Nginxへのいわゆる秘伝のタレ流し込みなどの「初動」を行います。そして、以降「計測」を行い、その結果を「分析」することで修正すべき箇所を特定し、「実装」を行います。
自分が作ったツール群では、この「初動」「計測」「分析」「実装」を極力ミスなく高速にできるように作っています。具体的には、以下のような形となっています。
- 「初動」をansible、isutools、isuginxで完全自動化
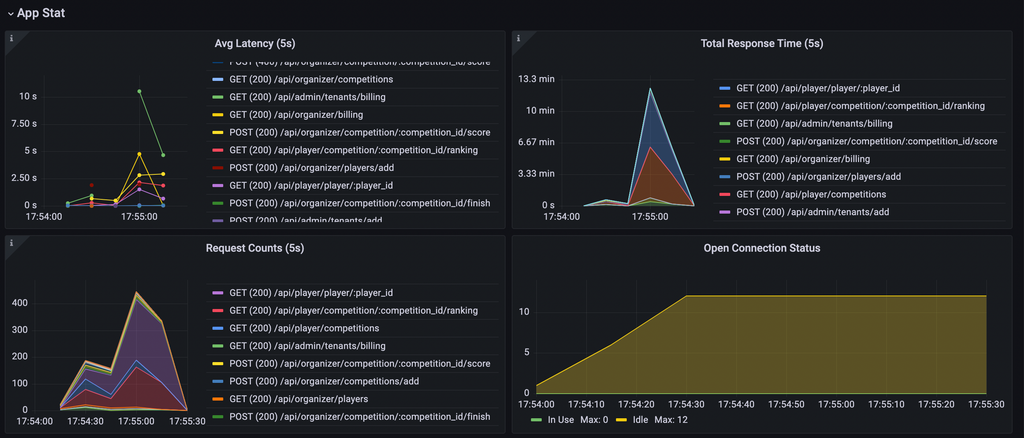
- 「計測」をGrafana、Prometheus、Loki、Pyroscopeにより情報量多く見やすく可視化
- isucrud、シナリオ解析、isurusの警告機能でコード・メトリクスを「分析」
- 「実装」ではisurusのo1を利用したクイックフィックスで典型的な改善を即座に適用
実はこの段階分けと3年間かけて前段階をそろえる計画は既に3年前から頭の中にあり、自分としては今年は3年がかりの計画が完成したかなり感慨深い解だったりします。
isurusが主に今年作ったもので、そのほかはほぼ去年までに作ったものとなります。
ここからは各ツールの説明をしていきます。去年までに作った部分に関しては大まかな説明+去年以前の参加記での説明へのリンクを貼るにとどめるので、詳細が気になる方はそちらをご覧ください。
ansible
 mazrean
mazrean一昨年に用意して細かい調整をしてきた、初動周りをほぼ完結できるansibleです。存在自体は一昨年の時点で触れていたのですが、本番中にうっかり問題情報を出してしまうと不味いのでずっとprivateにしていました。今年は公開するのですが、実際に使っている過去に企業内のISUCONなどに参加させていただいた際の設定などのコミットが入っているので全てコミットをつぶした別リポジトリで公開している点だけ注意してください。
中では以下を行っています。
- Gitリポジトリ周りの設定
- Makefileの細かい設定
- MySQL、Nginx、カーネルパラメーターの秘伝のタレ流し込み
- Nginxについてはisuginxを内部的に使用
- 計測ややって損がない系の改善適用
- 内部でisutoolsを実行
- Grafana、Prometheus、Loki、Pyroscopeの設定流し込み&起動
やっていることは地味なものばかりです。
ただ、この後紹介する大量のツール群の設定や実行を手動で行う時間はISUCONにはないため、実は全てを支えている縁の下の力持ちです。
isutools
mazrean一昨年から導入している、ソースコードを修正して自動で計測機器導入・やって損がない改善を適用するツールです。Prometheusの計測を仕込んだISUCONユーティリティも同一リポジトリに含まれています。詳細は以下をご覧ください。
一昨年の時点ではあまり広まっていませんでしたが、Orchestrionなどが出現した今見てみるとCompile-time instrumentationの先走りだったように思います。
isuginx
mazreanNginxの設定ファイルを解析して、秘伝のタレを流し込むツールです。詳細は以下をご覧ください。
Grafana,Prometheus,Loki,Pyroscope
一昨年にほぼ構築し、少しずつ強化してきた計測スタックです。以下の2か所で主に解説しています。
今年は去年導入したGrafana PhlareがPyroscopeにその役割を移したため、今年は移行しています。ただ、この以降によってPyroscopeのみに存在するFlame Graphのdiff viewが使えるようになったのは、変更前後での負荷の変化が分かりやすく便利でした。
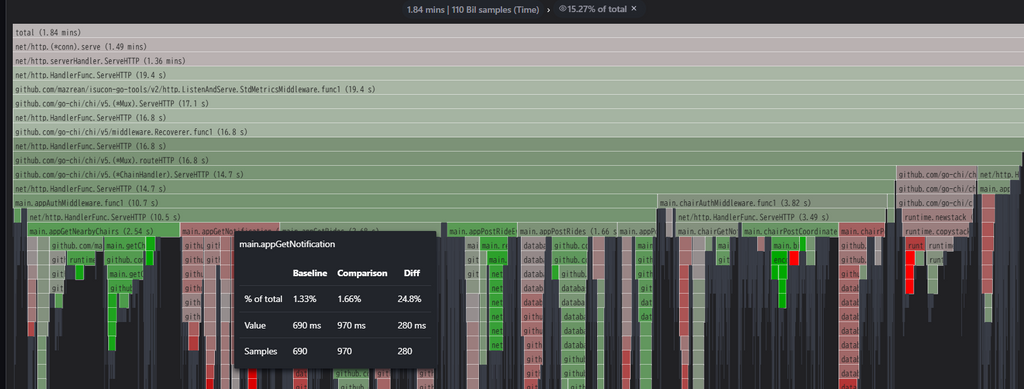
自分の特に推しポイントは以下で紹介しているCookieを利用したシナリオ解析です。これがあるだけでかなりクライアントの挙動が理解しやすくなります。
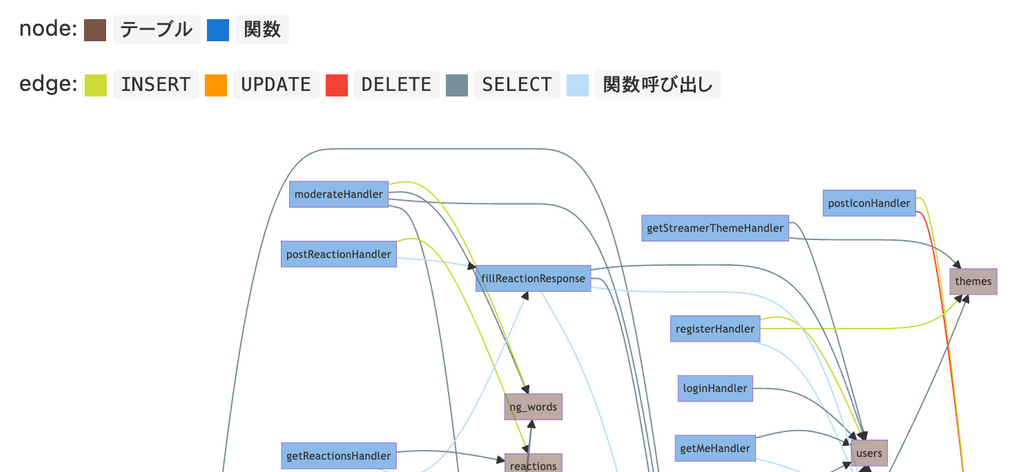
isucrud
mazrean去年作成した、ソースコード中でのSQL呼び出しまでの関数呼び出しの流れを可視化するツールです。詳細は以下をご覧ください。
今年はWeb UIと特定関数・テーブルへのフォーカス機能を追加しています。
このツールはOSSとして公開しているのですが、今年も多くの方に使っていただけたようでうれしいです。
昨年からの引き続きのお願いなのですが、悪かった点とかも含めて使用感とかを教えていただけると非常に嬉しいです。今後の意欲につながるので、是非お願いします!
また、すでに反応くださった方、本当にありがとうございました。来年以降もメンテナンスなどを続ける励みになります。
isurus
今年の秘密兵器、というよりこれを作るために3年間かけてここまでのツールを整備したと言っても良いツールです。
ここまで紹介したツールで集めた計測・コード解析結果を基にデータベースに関連する問題個所を特定し、o1を用いて変更内容を提案するVSCode拡張機能です。もう少し具体的に説明すると、DBへのindex追加、SQLのN+1問題修正、バルクインサート、SQL実行結果のオンメモリキャッシュなどの典型的な修正を自動で行います。index追加以外はクイックフィックスで簡単に適用できます。

仕組み
以下のような流れで推薦を行います。
- データベースの負荷の原因となっているSQLを特定
- PrometheusのAPIから取り出したSQLの実行時間を基に判定
- SQLが負荷の要因となる理由、関連するソースコード箇所を特定
- isucrudの解析結果を主に使用
- PrometheusのAPIから取り出したSQLの呼び出し回数、平均応答時間も利用する
- o1用のプロンプトを作成
- 具体的なプロンプトはソースコード中の以下にまとまっています
https://github.com/mazrean/isurus/blob/58776a2014679dcbc14820f32d620a8d56c1f676/src/langchain/prompt/database.ts - 問題とそれに対する修正方針、関連するソースコード、修正対象ソースコードを構造化して渡しています
- プロンプトエンジニアリングド素人なので、突っ込みどころは色々ありそう
- 具体的なプロンプトはソースコード中の以下にまとまっています
- o1の応答を基に変更提案
「RAGとかlangchainのTools、Agentとか使わないの?」という突っ込みはありそうですが、事前に試した結果単純に各種計測ツールをToolとして渡したり、ソースコードをRAGで渡すだけではあまり良いコードを生成できなかったためこのような形となっています。
ソースコードのRAGについては、コード用のEmbeddingを実装コストの関係で用いなかったせいかisucrudの解析結果でつかみ切れないような関連コードを見つけることができず、むしろ不要なコードの混入の悪影響が大きかったです。
PrometheusのAPIなどのTool化については、トークン数制限と精度の兼ね合いがうまく行かなかったため断念しました。まず、Geminiなどの安価でトークン数制限の緩いLLMにToolとして繋ぎこんでみたのですが、この場合PromQLの構築がうまく行かず適切にPrometheusのAPIを利用できませんでした。また、OpenAI系のモデルなどのコード生成に強いモデルでは、Prometheus内で使えるメトリクスの説明などを与えたうえでならPromQLの構築はできました。ただ、メトリクスの説明に使えるトークン数が少なく、対象とするメトリクスをかなり制限しなければならず安定性なども考えると事前に用意した固定クエリを基に手動でプロンプトを作成する方が良いという判断になりました。
ツール構成
本体は以下のTypeScriptで実装したVSCode拡張機能です。
mazreanここから、isucrudの解析結果などを加工するためのGoのJSON RPCサーバー(LSPではない)を呼び出す構成となっています。
mazreanJSON RPCまで使っておいてGoのLSPにしなかったのは、TypeScriptのほうがLangchain.jsがありLLMまわりの試行錯誤がしやすかったためです。GoのLSPにしてしまうとAPI直呼び出しか、Langchain非公式のLangchain.goを使用することになりますが、ドキュメントにもかなり空きが多く、ToolやRAG関連のインターネット上の知見がかなり少なくなるためこのような形となっています。
金銭的コスト
内部的にo1のAPIを使っている関係で、このツールを使うとそこそこの速度でお金が溶けていきます。
と言っても、ISUCON当日に関しては$2.4(約370円)分の消費で済んでいました。開発時や素振りで何回か事前に使っていた際を合わせると$14(約2,155円)程度です。
仮に毎日$2.4使うと月$72(約11,000円)程度の消費になるので、日常的な開発で使うとなるとかなり悩むラインな気はしますが、ISUCONの日だけ使う前提なら悪くない金額だと思っています。
使ってみての感想
正直想像の何倍も活躍してくれました。序盤の典型的なインデックス追加、N+1解決、オンメモリキャッシュはほぼこのツールがやってくれています。自分の感覚としては、「通常の3人チームで1人が行う以上の改善がこのツールにより1時間で終わっている」程度の活躍だと思っています。
この結果を一段一般化して考えるとテレメトリーとLLMをつなぐとかなり役に立つになるのかな、と思っていたりします。今回やってみての肌感覚として、障害発生時にCIでテレメトリーを食わせたLLMにより自動でPRが作成される機構とかはちゃんと作るとかなり機能するのではないかという気がしています。
また、ISUCONを戦う上でのメリットという意味では、典型的な改善に脳のリソースを使わないで良い分、序盤からシナリオなどの俯瞰した思考にリソースを割きやすくなるというのもかなり大きなメリットになっていると感じました。
ただ、isucon14ではペイメントマイクロサービスのモックサーバーのソースコードが提供されていたのですが、このような複数Goのアプリケーションが存在する状況を想定しておらず本番中に修正に15分ほど取られてしまったのはすこし痛かったです。3年間ISUCON用ツール開発をしてきてやはり「何が来るか分からない」状況に対するツールを作るのは難しいですね…
当日の流れ
ここからは当日入れた改善についての解説です。冒頭にも書きましたが、最終結果はfail、最高スコアだと26,710点で25位相当くらいになっています。
感想戦も含んでいるため当日のコミットはだいぶ前になっていますが、リポジトリは以下です。
mazrean10:00~10:20 ansible実行+マニュアル読み込み(864点)
裏でansibleを実行し、その間に自分がマニュアルを読み込みます。
ツール化はしていませんが、マニュアル読み込みにもo1を使っていて、以下のようにo1に要点を取り出させています。今見てもシナリオなどをしっかりとらえられており、かなり的を得た回答をしているように思います。

10:20~11:45 isurus適用(3434点)
isurusにより自動で変更を入れます。マイナスにならなさそうなものは片っ端から取り込んでいるので、この時点だとあまり効かない物も多数含まれていますが、以下の変更を行っています。
- chair_locations、rides、ride_statusesテーブルにindex追加
- appGetRides、appPostRides、appGetNearbyChairsのN+1解決
- 各種アクセストークン、rideStatusのオンメモリキャッシュ
上がっている点はそこまで大きくはないですが、今見ても凄まじい手数ですね…
11:45~13:05 chair locationのオンメモリキャッシュ(4434点)
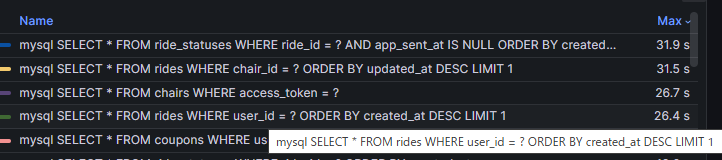
chair locationから合計移動距離を計算するSQLの実行時間が長かったので、移動距離ごとchair locationをオンメモリキャッシュします。計測結果で一番上に来ているSQLはバックグラウンドで走るマッチングのSQLなので一旦無視しています。

13:05~13:20 isurusによるgetChairStatsのN+1解決(5837点)
ここでisurusがまた仕事をしてくれて、負荷が上がってきていたgetChairStatsのN+1問題に半自動で修正が入ります。
13:20~15:30 アプリケーション向け通知周りのオンメモリキャッシュ(9707点)
実行時間が長いSQLが軒並みアプリ向け通知関連になってきたため、アプリ向け通知のレスポンスを一気にキャッシュします。
ここの選択肢としてはretry afterを大きくしてリクエスト数を下げたりSSE対応という手もあると思います。しかし、マニュアルやログ出力を見るにシナリオ上反映のラグは大きく点数に影響すると考えられます。また、SSEと比べてオンメモリキャッシュの方が慣れており実装コストが低く、SSEによるコネクション数低下勝負にまではならないだろうという判断でオンメモリキャッシュを選択しました。
なお、このタイミングから整合性まわりの細かいベンチマーカーエラーが出始めます。ただ、この時点ではリクエスト数が少ないのもありfailするほどではなかったため放置します(敗因)。
15:30~15:50 マッチングアルゴリズムの改善(17993点)
負荷の上昇速度を上げるためにマッチングアルゴリズムを複数一気にマッチさせるように改善します。
実はこのタイミングで実装を誤っており、マッチングの優先度として椅子と目的地の距離を使うという謎な実装になっています。ランダムよりはましですが明らかに効率は悪いですね…
15:50~16:25 DBサーバー分割(22257点)
最後までDBの負荷がネックなのは変わらなさそうだったため、DBサーバーをアプリケーションと別のサーバーへ移動させます。
16:25~17:05 椅子向け通知のオンメモリキャッシュ(断念)
椅子向け通知のオンメモリキャッシュ周りのSQLの実行時間が長くなっていたのでオンメモリキャッシュを試みます。
ただ、failが取れず残り1時間を切ったタイミングでそのタイミングで30位がねらえるスコアだったこともあり断念します。
17:05~17:45 retry afterの調整(26710点)
明らかに調整することで負荷のバランスを調整できそうなretry afterをこの時点では一切触っていなかったので、値をガチャガチャ調整します。
最終的には椅子、アプリともに50msにしたタイミングで最高スコアの26710点が出ます。
17:45~18:00 再起動試験(fail)
時間が少なくなってきた&上位30位以内を狙えるスコアだったので再起動試験をします。
ここで再起動起因ではなく、ガチャ運が崩壊しこれまで体感1/3程度でしか引いていなかったキャッシュの不整合周りのエラーを7連引きしてfailで終了します…
実は再起動で何か整合性崩れているとかも疑ったのですが、その後運営による再起動試験ではスコア出ていたので単にガチャ運が崩壊しただけなようです…
まとめ
振り返ってみてもツールはやはり良い仕事しているんですよね…
ツールの感想で「1人以上の働きをツールがしている」と書きましたが、自分には残り2人分の働きをする力が現状なかったのが敗因に感じています。
まだまだツール群に改善の余地はあると思いますが、自分がやりたかったことはほぼほぼできた状態で勝てない、自分の素の力不足が悔しいです。
3年間ソロで出ていて思うのは手数の圧倒的不足で、これを解消するにはやはりチームで出るしかないかな、と思っています。ツールもやりたかったことはほぼできたので、来年はチーム組んでリベンジします!
そして、この悔しさから40万点に到達した感想戦編へ続く…