こんにちは。23Mの@mazreanです。SysAd班でtraP Collectionというアプリケーションのバックエンドの開発・運用などを行なっていました。
ISUCONにはISUCON9から出ており、ISUCON11で本戦に出場していました。ISUCON12からは色々独自ツールを使って戦ってみたかったので、気楽に独自ツールを入れられる1人チームで出ています。
また、ISUCON夏祭りで「ISUCONは良い発想が生まれやすい環境」という話をしたりしていました。

ISUCON13にも1人で「INUCON 13(いい感じに猫を動かすコンテスト ワン!ミャ〜!)」として参加しており、最終スコア(おそらく)fail、最後にでたスコアが19300点ぐらいで惨敗しました…
今回はその参加記です。
使用ツール
今年も色々独自ツールを作ったり拡張していたのでその紹介です。
インフラ構成
構成図はこんな感じです。
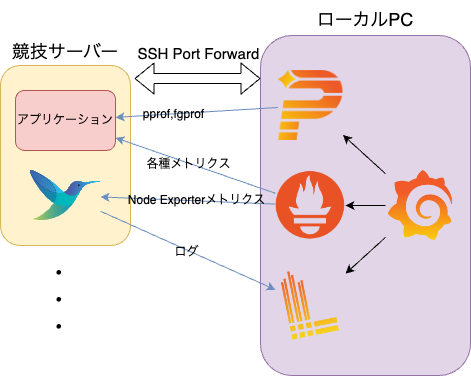
ローカルPCにGrafana+Prometheus+Lokiを構築し、ssh port forwardでサーバーとポートを繋いでいます。
そして、fluent-bitでlog収集とnode-exporterと同等のメトリクスの収集を行い、aアプリケーションからアプリケーション関連のものを中心にメトリクスを収集しています。
ここまでは去年とほぼ同じですが、今年からGrafana Phlareを導入しています。これによりpprofやfgprofのメトリクスもGrafanaで確認できるようになっているのが嬉しいポイントです。
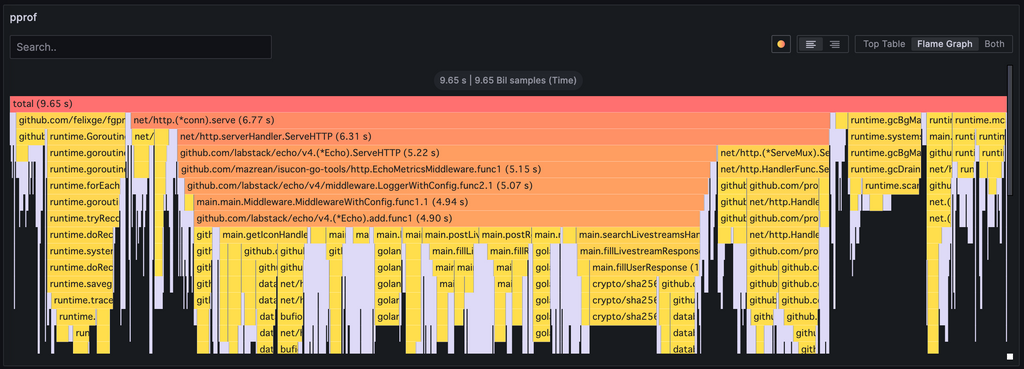
ただ、Grafana Phlareはほぼ同等のことをやろうとしていたPyroscopeと合流し開発が停止されたため、来年までに切り替えないといけない…
自作ユーティリティ
去年作った、ISUCONでよく使うキャッシュやキューなどが入ったユーティリティライブラリです。
詳細は去年の記事を見ていただけるとわかると思います。
今年はここにいくつか拡張を加えて以下のメトリクスを追加しています。
プロセス関連のメトリクス
サーバー上のプロセス単位でのCPU使用率やメモリ使用率です。
fluent-bitのNode Exporterと合わせるとtop/htopの完全な代替になるようになっています(実際今回はhtopは一切使っていません)。
当然この手のメトリクス取ってくれるprometheusのexporterは存在するのですが、デプロイするコンポーネントの数が増えるとオーバーヘッドもデプロイでの事故確率も上がるのを考慮した結果、procfsからメトリクス吐き出す機構を自前実装してしまうことにしました。
実装自体はprometheusがwipという注意はついているもののprocfs解析用のパッケージを提供してくれていたので、結構楽にできました。
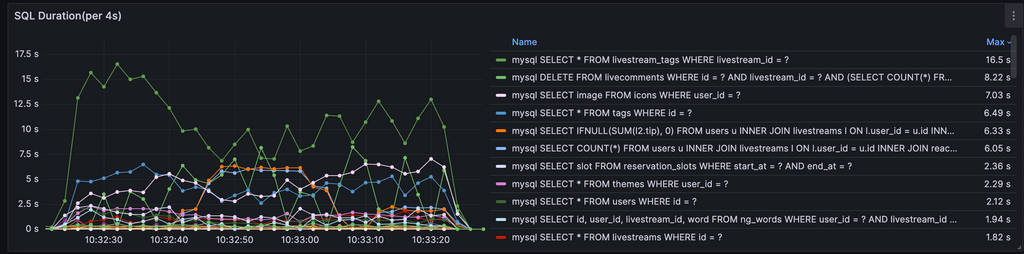
SQLの実行時間、実行数のメトリクス
アプリケーション側からSQL関連のメトリクスを取れるようにして、以下のようなメトリクスを取れるようにしていました。
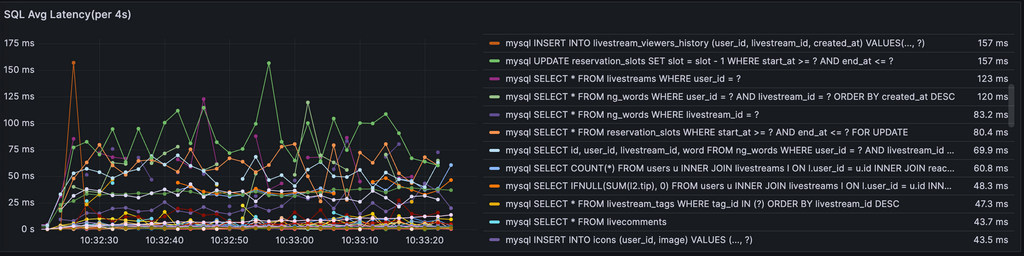
slow query logで十分と言えばそうなのですが、去年のSQLiteに自作ツール潰されたのがトラウマになって作りました()
そのため、各種DBに対応しており、MySQL、トラウマの元のSQLiteは当然として。PostgreSQLでも問題なく使えます。
強いてsqlow query logとの大きな違いをいうなら、時系列データで扱えることかな、と。途中で傾向が大きく変わるタイプのシナリオだと結構優位性があるんじゃないかと思っています(実際isucari解いた時とかはキャンペーンの時に叩かれるSQLが確認できるのは便利でした)。
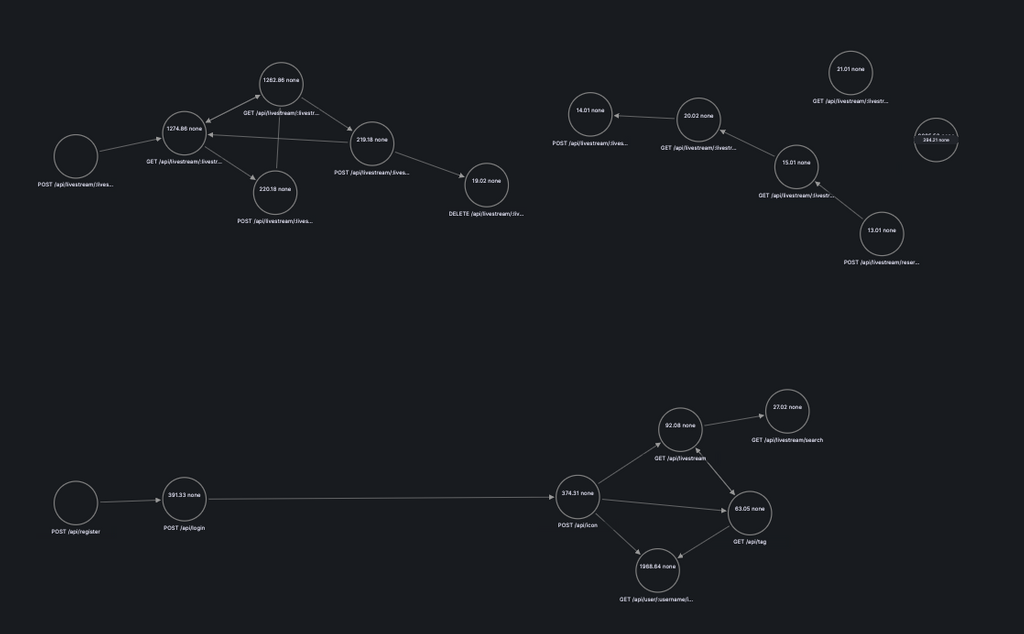
ユーザーの行動遷移メトリクス
cookieを利用してユーザーが「どのAPIを叩いた後、どのAPIを叩いたか」を計測したメトリクスです。
実は、isucandarができて大半のベンチマーカーがクッキーを保持してくれるようになったことで機能するようになった仕組みなので、isucandar未使用の過去問だと時々気のしないやつがあったりします。
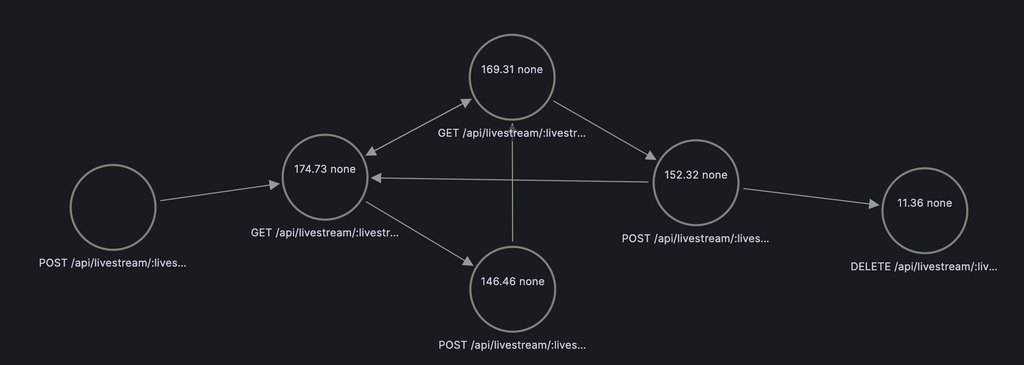
GrafanaのNode Graphと組み合わせると、こんな可視化ができます。ノードがAPI、エッジがユーザーの遷移になっており、ホバーすると実際にその経路を通った数が見れます。これがあるだけでシナリオの把握がかなり楽になってくれます。
自作CLIツール
去年から存在していた初動のコード書き換えを行うisutoolsやNginxのconfigに秘伝のタレを流し込むisuginxは今年も使っています(詳細は去年の記事)。
今年は追加で1つ可視化ツールを作っています。
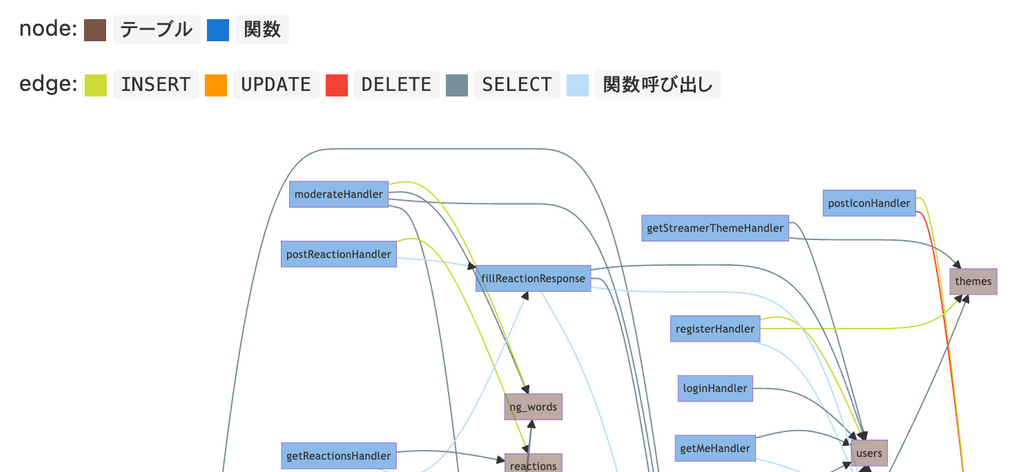
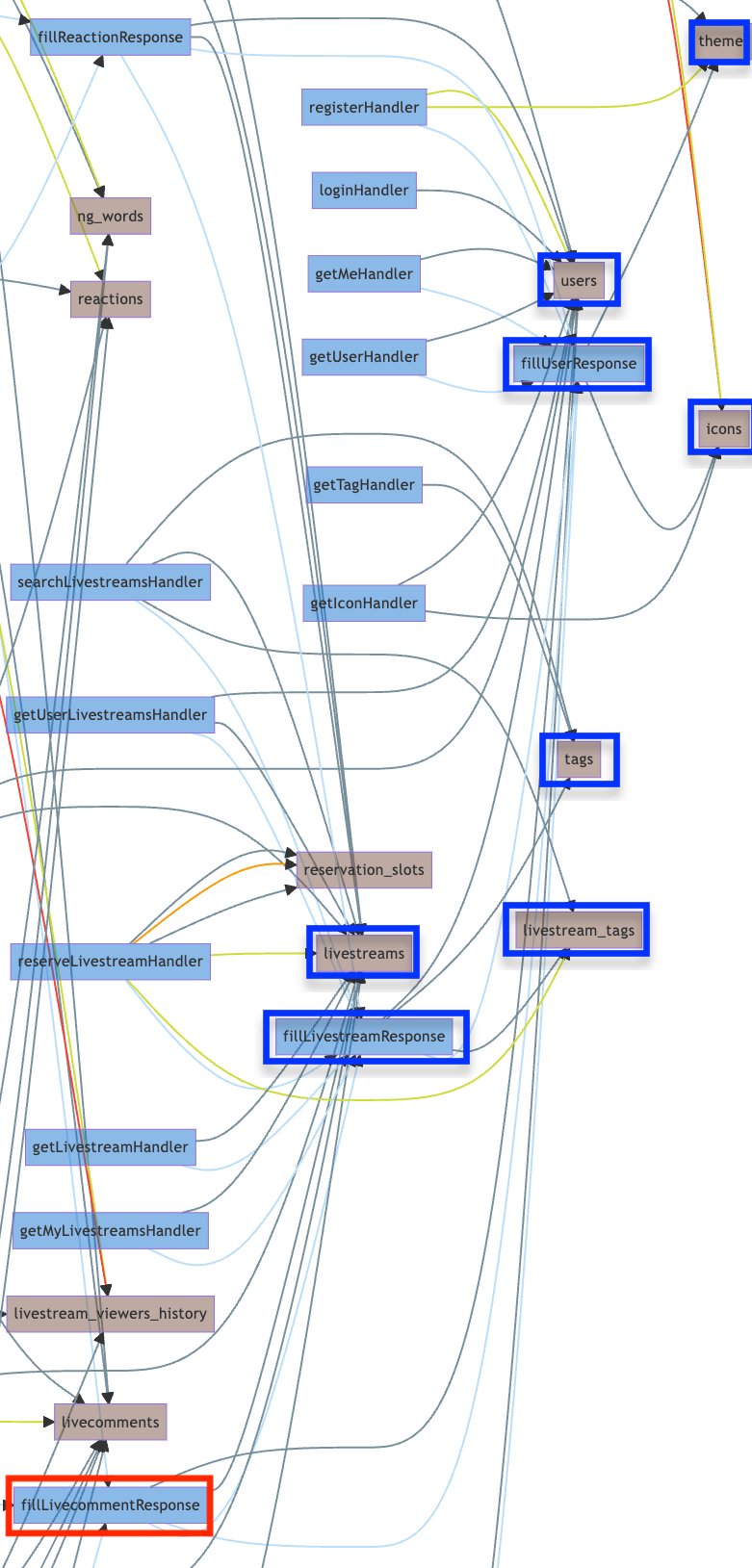
isucrud
ソースコードをもとに、どの関数を通ってどのテーブルにCRUDが発生するSQLが実行されているか解析して以下のようなグラフを吐き出してくれるやつです。
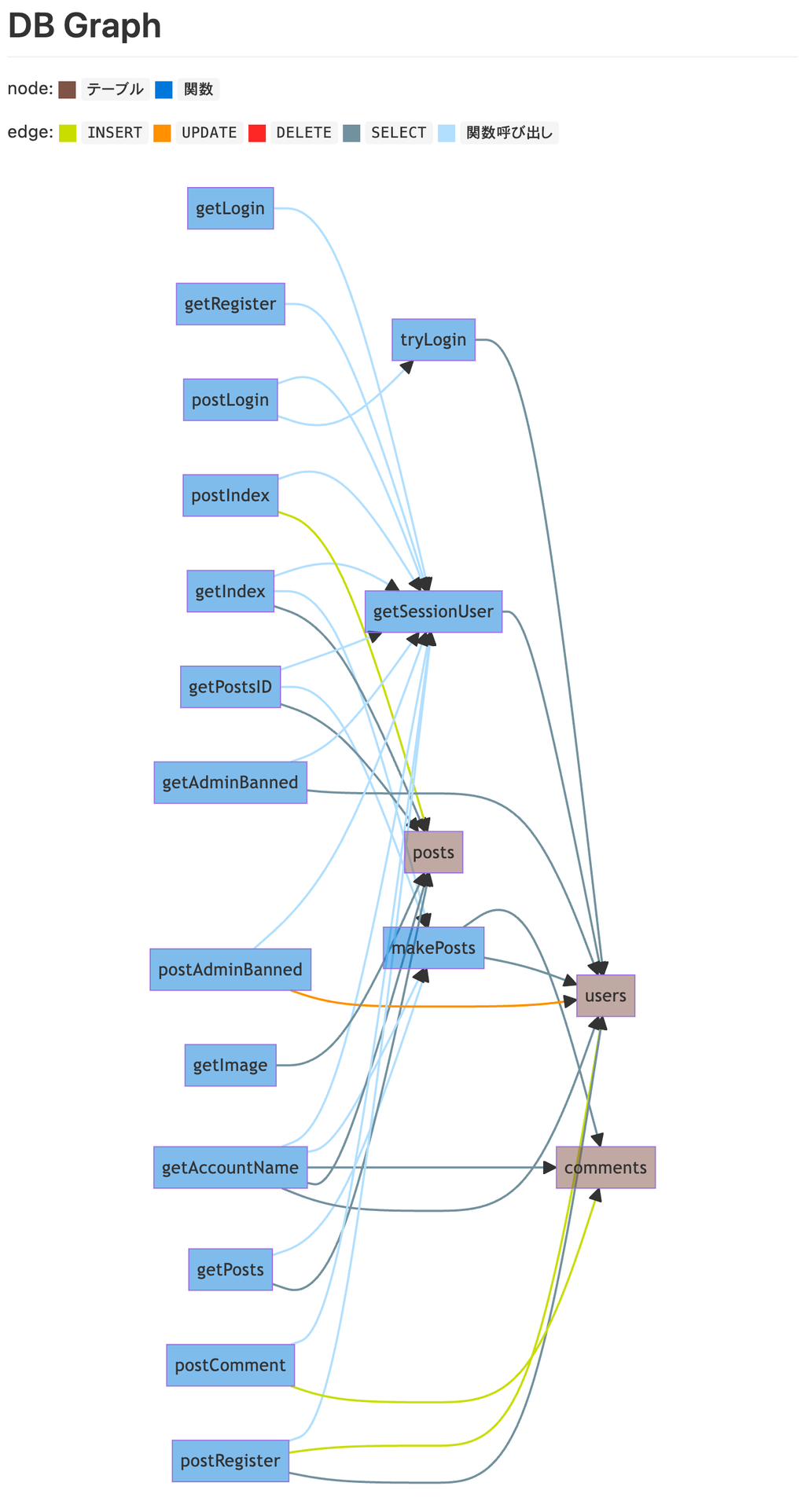
以下のリポジトリで公開しており、誰でもかなり簡単に使えるようにしているつもりです。
 mazrean
mazreanISUCON13のdiscordでも紹介させていただいて、反応やGitHubのclone数を見た感じそこそこ使ってもらえたんじゃないかな〜、と思っています。
discordやX(旧Twitter)でも投げた通り、悪かった点とかも含めて使用感とかを教えていただけると非常に嬉しいです。今後の意欲につながるので、是非お願いします!
また、すでに反応くださった方、本当にありがとうございました。実際に使ってもらえたのがわかって非常に嬉しかったです!また来年も何か作ろうという気持ちが強くなりました。
当日
リポジトリは以下。最後のベンチマークはfailで終わっています…
最後に出た点は19.300点ぐらいだったはずです。ソロ難しい…
mazrean10:00~10:30 初動+マニュアル確認(3800点)
ansibleを実行して計測環境を整えつつ、マニュアルを読んでいました。
マニュアルについては、明らかに問題のキーになる感じの「DNSサーバーについて」の項目が目立っていたのでそこに注目していました。
そして、ここでアプリケーションマニュアルがあるのを見逃すという最悪のミスをやらかします…(敗因 その1)
後々、これによってiconへの対応を完全に誤って大幅に時間ロスすることになります…
計測環境構築のansibleが何も問題なく通ったのは素振りの成果でよかったポイントだと思っています。
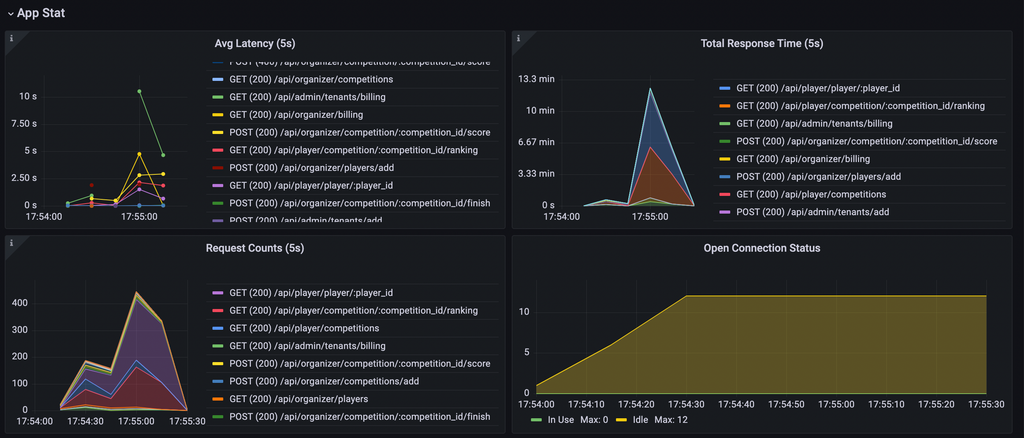
10:30~10:45 計測結果確認
計測結果を確認していきます。
まず、リソース食っているものの確認ですが、完全にMySQLのCPU食っているのがネックになっています。とりあえずMySQLのCPU使用率下げるのが目標になりそう。
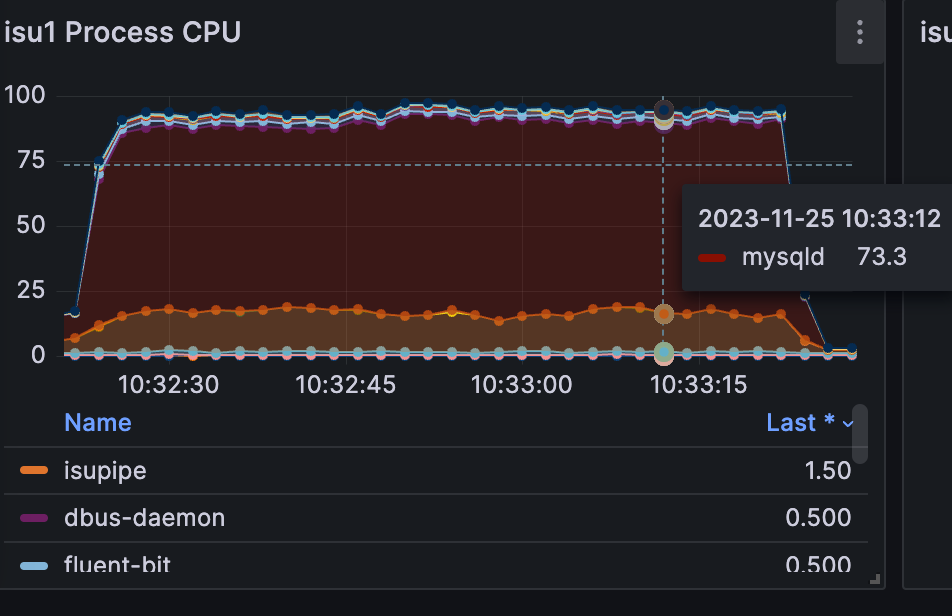
SQLの実行時間を見るとトップにSELECT * FROM livestream_tags WHERE livestream_id = ?が居るのがわかります。また、次点のlivecommentsのSELECTやiconの取り出しもこの後確実に問題になってきそうな感じがします。
次にユーザーの遷移のグラフを見ていくと、以下の3パターンの動きがありそうなことがわかってきます。
配信検索: ユーザー登録&ログイン→アイコン変更→(タグ取得)→配信一覧取得→配信検索

配信視聴: 視聴開始→コメント・リアクション取得→コメント・リアクション投稿→視聴終了
配信者: 配信予約→NGワード取得→ レポート取得→NGワード設定
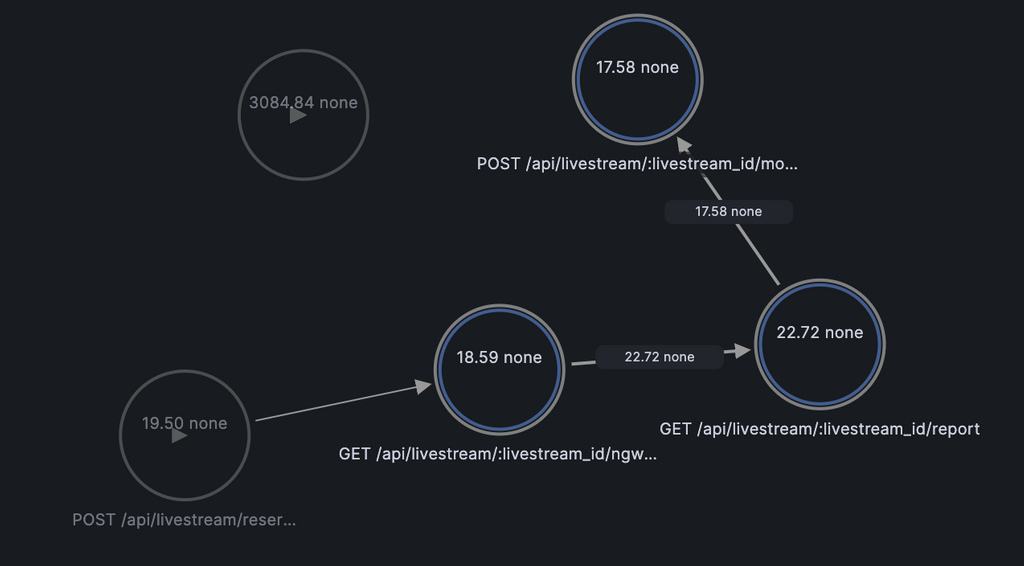
配信者の動きだけなんか不自然な気はしますが、リクエストの流れ上はこういう動きをしているっぽいです。
これを踏まえて、現在の重いポイントを見ると、配信検索のiconやtagあたりでユーザーが詰まっていそうです。常識的に考えて、ここを突破したら配信視聴の動きにつながってきそうなので、ここをつぶしたらコメントやリアクションに負荷が移動してきそうです。
そして、さらに先を推測すると視聴者が増えてきたら今度は配信者が増えないと点が伸びなくなってくる、みたいなシナリオになっていそうです。
10:45~12:30 livestreaming tagのキャッシュ(4800点)
とりあえず第一関門の配信検索を早くするためにlivestreaming tagのSQLを潰しに行きます。
案の定、検索周りなどで問題のクエリが使われているfillLivestreamResponseがループで呼ばれているので潰しにかかります。
ここでオンメモリキャッシュかJOINで解決するかを選択することになります。
こういう時のためにisucrudがあるので見ると、livestream_tagsもtagsもDELETE、UPDATEがないことがわかります。
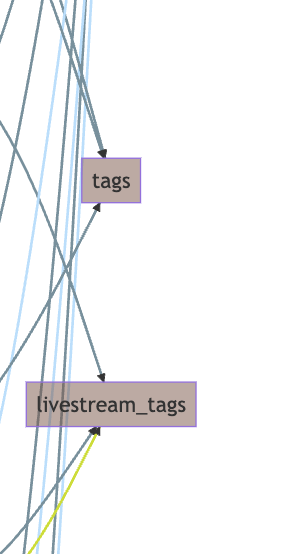
というわけで、オンメモリキャッシュを選択します。
ここまではよかったのですが、織時屋の@tokiの作ったキャッシュライブラリscを使って実装しようとしたところ、なぜか配信予約のレスポンスにタグが反映されなくなり整合性チェックが通らなくなります…(たぶん自分の実装が何か良くなかった)
結局、素直にmapを利用したキャッシュを使用するようにして実装完了したのが12:30になってしまいました…
12:30~16:00 iconのファイル書き出し試み
ボトルネックもiconに移動したので、iconの読み書きを改善していきます。
ここで、最初のマニュアル確認でアプリケーションマニュアルを見逃していた結果、If-None-Matchが設定されるのに気づかず、iconをファイルへ書き出しNginxに配信させようとしてしまいます…
そして、今考えるとIf-None-Matchあたりが原因でNginxのキャッシュが効いたりしていたんじゃないかと思うのですが、なぜかiconの変更がベンチマーカーで確認されない問題に悩まされ時間を溶かします…(ブラウザでは普通に変更反映されているの確認できたので何もわからなくなっていた)
結局解決する前にもう一度マニュアルを見に行ったことでIf-None-Matchを使えば良いことに気がつき、そこまでの実装を捨てます…
もっと早くに気がつける力が欲しかった…
16:00~16:15 iconでIf-None-Match使用(6000点)
userごとのiconのhashをキャッシュした上で、キャッシュあり&If-None-Match一致の時に304 Not Modifiedを返すようにします。
マニュアルちゃんと読んでいれば3時間半浮いていた…
16:15~16:30 fillLivecommentResponseキャッシュ(10000点)
isucrudをよくよく見ると、実はfillLivecommentResponseの結果で変更があるのはuserのiconHashだけなことがわかります(青がReadされているテーブル、iconsにUPDATEがある以外は全てINSERTかSELECTだけ)。
というわけで、userハッシュのみキャッシュを利用して読み込み、それ以外の返り値全体をキャッシュすることで、fillLivecommentResponseをほぼDB呼び出しなしにできます。
これにさっさと到達したかった…
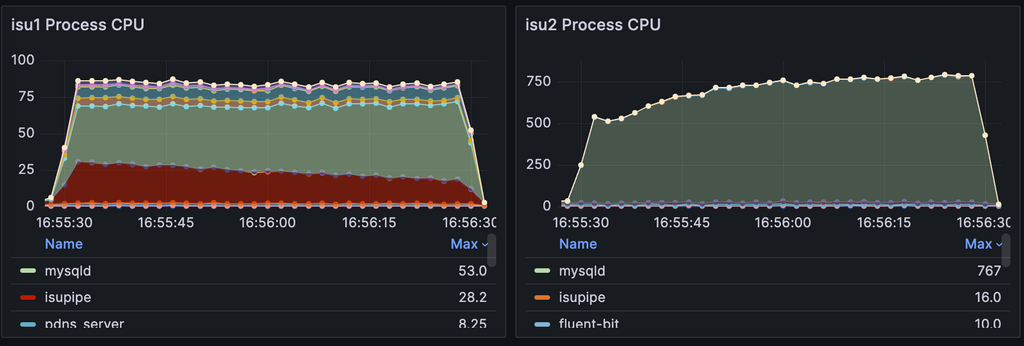
16:30~17:00 MySQL(アプリケーション)の鯖分割(15000点)
時間も時間なので、サクッとできて確実に点が上がるサーバー分割をします。
ここは素振りで何回もやったのでほぼつまらずにサクッと実装できました。
PowerDNSの方は触り慣れていないのもあってすぐにできるか怪しかったので一旦放置。
これによって、CPU使用率が以下のようになり、PowerDNSのMySQL周りがネックになります。
17:00~17:15 fillReactionResponseキャッシュ(18500点?)
comment取得が早くなったことでreactionが重くなってきていました。本当はPowerDNSのMySQLを3台目へ移動させたかったのですが、時間が少なかったのとfillLivecommentResponseと同様の方法で対応可能なのがisucrudでわかっていたのでfillReactionResponseの返り値全体キャッシュを行います。
17:15~17:20 jsonライブラリ置き換え
残り時間が少なくなってきたので、簡単にできるjsonライブラリをgo-jsonへ置き換えるのをやってしまいます。
なんかこの辺り焦って計測回していない気がする()。
17:20~17:35 moderateのN+1排除
唐突ですがtraPの部内SNS traQで最近動き始めたtraQ gazerというハッカソンで作られたBotがあります。
このBotは特定文字列がされた投稿があるとDMで教えてくれる、という今回の問題のNGワードそっくりな挙動をします。
このBotですが、以下のような最高にCool()な実装があります。
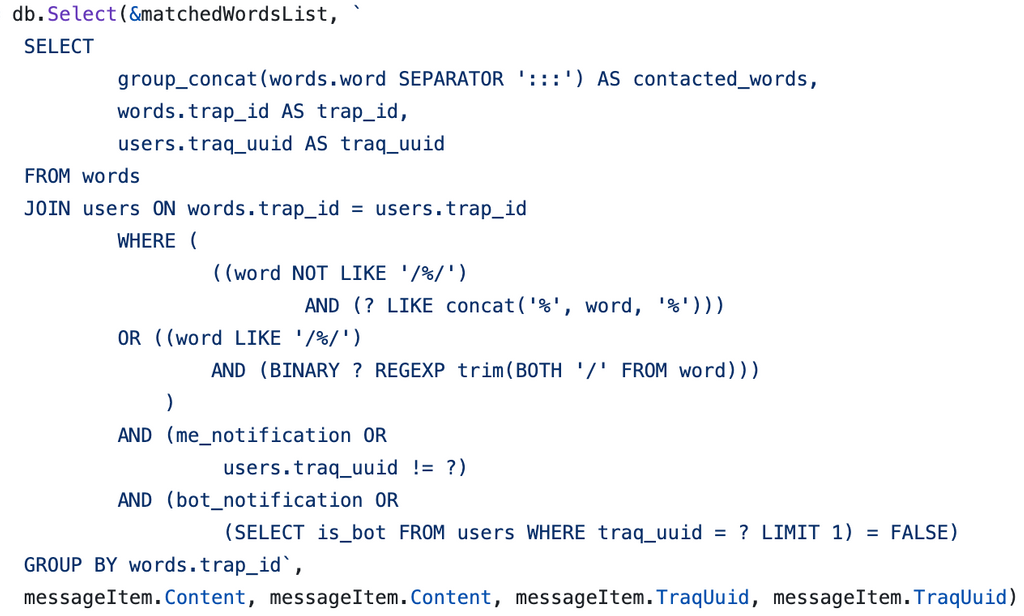
ヤバそうなクエリではありますが、今回のN+1を潰すのに役には立つので真似して以下のような変更を入れてmoderateの軽量化を試みてみました(計測結果は覚えていない…)。
mazrean17:35~17:40 userのname→idをキャッシュ(19300点)
iconの中で行われていたnameからidを引くクエリを削るためにキャッシュを入れました。
今考えると一旦放置で良かった気もする。
17:40~18:00 そして絶望へ…
細かい改善のネタが一旦尽きた&この点数では上位には絶対入れないので、仕方なくPowerDNSのDBを3台目に移すのに着手します(遅い)。
PowerDNSの設定何もわからないのでChatGPTとおしゃべりして設定ファイルの見つけ方や書くべき設定を教えてもらい、1台目のPowerDNSに反映しました。
しかし、なぜかPowerDNS用のDBだけではなくリクエストの流れるアプリケーションも3台目になってしまい、とりあえず設定を戻したところfailするようになり終了時刻を迎えました…
感想
結構自作ツールはいい仕事してくれたと思うのですが、自分の力が足りませんでした…
ソロだと変な見逃しとかのミスをしてしまうと誰も訂正してくれない、のやっぱり難しいと感じています。来年はもっと強くなって帰ってきます!