こんにちは。19Bの@mazreanです。普段はSysAd班でanke-toやtraP Collectionというアプリケーションの開発・運用などを行なっています。
去年のISUCON11予選は@Azon、@xxpoxxと一緒に「手が3本あるテディーベア」として参加し、学生枠で突破していました。興味がある人はそちらの記事も是非見てください。
 mazrean
mazrean
今回はISUCON12予選に1人で「INUCON 12(いい感じに猫を動かすコンテスト ワン!ニャン!)」として参加し、最終スコア6048点で完敗しました…
この記事はその参加記です。
計測環境
自分もいつものISUCONはkataribe、pt-query-digestにpprofを組み合わせた軽量な計測環境を使っています。
今回はせっかく気楽な1人チームなので、Grafana+Prometheus+Lokiに自作ツール群を組み合わせて、ガンガンに攻めたリッチな構成をansible一発で立てる方向性で準備をしました。
かなり雑ですが、構成図はこんな感じです。
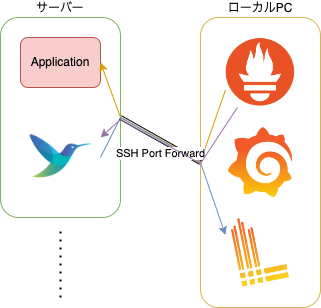
ざっくり説明すると、ローカルPCにGrafana+Prometheus+Lokiを構築し、ssh port forwardでサーバーとポートを繋いでいます。
そして、fluent-bitでlog収集とnode-exporterと同等のメトリクスの収集を行い、applicationからAPI周りのリクエスト数やDBのコネクション、myprofilerに近いメトリクス、その他自分で埋め込んだメトリクスなどが収集できるようになっています。
applicationにメトリクスのexportを追加するのは後述のisutoolsによりほぼ全自動で行えるようになっています。
このようなリッチな構成は構築に失敗すると大幅な時間のロスにつながるというリスクを抱えています。
その点はとにかく素振りする()という脳筋対処により解決する方向で行きました。
具体的には、予選準備用ということでいただいたさくらのクラウドのクーポンを使って、過去の問題環境を可能な限りUbuntu 18.04、20.04、22.04の全てで建て、ansibleを問題が出なくなるまでひたすら適用し続けました。
しかし、結局本番で少しトラブってしまい計測環境ができるまでに1時間を要してしまったので、やはりISUCONには軽量な計測環境が一番だな、と感じました。
自作ツール
全体で、「初動をansibleを叩くだけで終わらせる」を意識してツール整備をしました。
というのも、1人チームだとマニュアルやコードの読み込みと計測の構築が並列に行えないのが初動での大きなマイナスポイントになると考えました。
これがansible一本で終わるようになると、ansibleを裏で走らせつつ、その間にマニュアルやコードを読むことができ、初動時間の削減につなげられると考えました。
この考え自体はそれなりにうまくいき、最初の1時間で3人チームの時と同等の計測環境構築とマニュアルとコードの読み込みが実現できたのではないかと思います。
isutools
 mazrean
mazreancacheやBulk Insertなど、ISUCONでよくする実装を簡単かつPrometheusのメトリクスを埋め込みつつするGo言語用ライブラリ群と、それを自動で埋め込むcliです。
ライブラリに含まれているpackageは
- cache(AllPurgeによりcache全リセットができるon memory cache)
- db(database/sql,sqlxのDB構造体に各種メトリクス計測を仕込む)
- http(echo,net/http,etcに各種メトリクス計測を仕込む)
- pool(sync.PoolにGenericsで型をつけつつ、メトリクスを仕込む)
- query(Bulk Insert、Bulk Updateの実装を少し楽にする)
- queue(channelによるキューにメトリクスを仕込む)
です。また、github.com/mazrean/isucon-go-toolsはブランクimportするだけでPrometheusとpprof、fgprof用のエンドポイントが設定されるようになっています。
cliではgolang.org/x/tools/go/analysisのSuggestedFixを利用して、上記のライブラリ群を以下のようなコマンド一本で仕込めます。
go run https://github.com/mazrean/isucon-go-tools/cmd/isutools@latest -fix本来は静的解析で見つけた修正点を自動で修正するための機能なのですが、これを利用することでコード書き換え時にうまく使うことで大幅に実装を楽にできました。
ISUCON以外でもそれなりに使い所のある知見で、ISUCON準備中一番の知見でした。
isuginx
mazreannginxの秘伝のタレを自動で仕込むためのcliツールです。
このツールを実装する際の肝になっている(というより、cliはこれを使ってるだけ)のが以下のライブラリです。
tufanbarisyildirimこのライブラリではnginxの設定のparseとdumpができます。
これにより、コマンド一発でnginxの秘伝のタレを仕込むcliツールを作れました。
その他の使用ツール
その他に
- htop
- pt-query-digest
で計測の穴を埋めました。
また、Warpによりsshで入った環境でもコマンドのsuggestなどが利用できるローカルに近い快適さが得られました。
当日
リポジトリ:
mazrean10:00(2705点)
競技開始。
CloudFormationでインスタンスを立てた後、最初の計測を回しつつ、問題環境に対応したパラメーターを設定し、ansibleを実行しました。
同時並行でマニュアル読みを始めます。
マニュアル読みで
- 反映までの猶予時間→何処かでworkerに処理移すことになりそう
- 429 Too Many Requests→リクエストをある程度捨てられる
- player側のGETの一部の点数が他の1/10→admin側重視?
ということを読み取ります。
このうち最後は計測結果を見て誤りだったと判定します。
10:15
ansibleが終了した通知がでます。
fluent-bitはUbuntu 22.04用のaptのpackageをまだ公開していないため、22.04の場合ソースコードからbuildするようにしていたのですが、素振りした環境にはあったヘッダーファイルが今回の環境にはなかったようで、そこで失敗していました。
不足していたのが
- libyaml-dev(yaml.h)
- openssl
- package-conf
という言語によっては問題環境に必要になりそうなものだったので、これまでは入っていたが、今回dockerによる環境だったために入っていなかったのではないか、と考えています。
急いでログを見てこれらの不足packageを見つけ、ansibleにinstallを追加した上で再実行します。
ここで慌ててしまい30分ほどロスしてしまいます。
11:00
やっと計測環境ができ、再計測します。
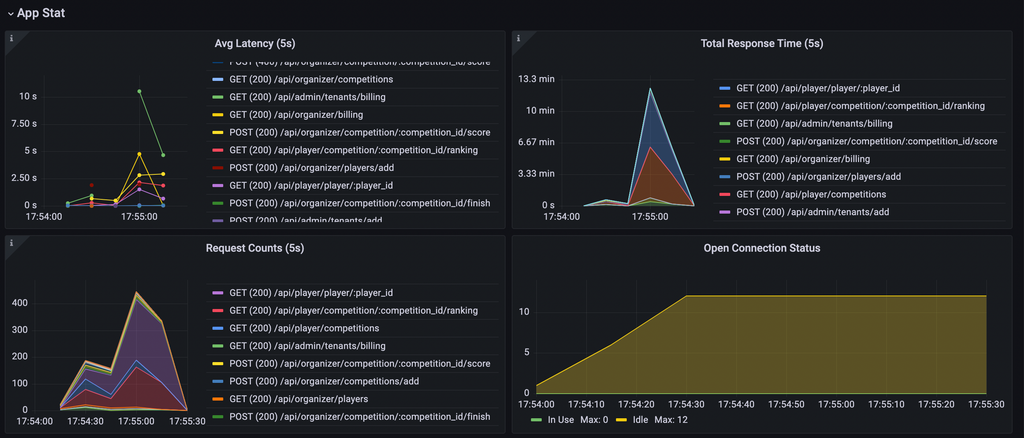
- /api/admin/tenants/billingが重い(pprof/fgprof,pt-query-digestより)
- playerが増えていくことでリクエスト数が増え、点数が伸びるシナリオっぽそう(リクエスト数の変化、ベンチマークのログより)
- GET /api/player/player/:player_id,/api/player/competition/:competition_id/rankingの高速化がキーになる(リクエスト数より)
- ↑2つと比べれば少ないが、POST /api/organizer/competition/:competition_id/scoreもそれなりに時間を食っているので頭の片隅に置いておく
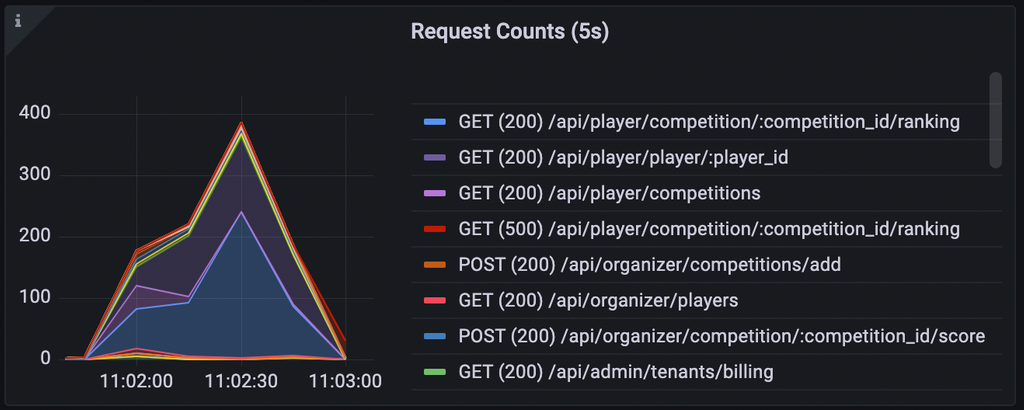
という考察をします。
player側の点数が低いですが、リクエスト数が明らかに10倍より多い&ユーザー増加により大きく増加していることを鑑みて、シナリオの予想を修正します。
とりあえず、CPUを大量に使ってplayer側にも影響を出してしまっているGET /api/admin/tenants/billingのを軽減しなければと考え、その部分を重点的に見ます。
11:20(4323)
以下のindexを追加します。
create index idx_visit_history_tenant_id_competition_id ON `visit_history`(`tenant_id`,`competition_id`);まだGET /api/admin/tenants/billingのアプリーションのCPU使用率が高いため、よう改善ポイントとして頭の片隅に置いておきます。
12:00(4383)
pprofにも出てきていたことと、重要と思われるエンドポイント複数に影響していたため、flockに着手します。
「SQLiteのTransactionのLockはデータベース単位だったはず」という記憶を頼りに、それならアプリケーション側でロックをとってしまった方が早そうと考え、アプリケーションでsync.RWLockを利用してロックを置き換えます。しかし、この時点では対してロックによる問題が発生していなかったようで、あまり点は伸びません。
12:45(4138)
playerのon memory cacheを実装**したつもりになります**。
重要なエンドポイントのN+1問題が複数解消されるので大きく点が伸びると思っていたのですが、読みが外れて???になります。
それもそのはず、この後発覚するのですが、追加や更新の対応だけして、playerの取得を置き換え忘れていました…
Prometheusのメトリクス吐いていた上に、cacheはグラフのコピペで可視化できるようにしていたのだから、ちゃんとグラフ作ってチェックするべきでした…
13:10(4019)
visit_historyがplayerごとに最も古い1件しかいらないことに気づき、GET /api/admin/tenants/billingの改善として最も古い1件のみを格納する以下のようなテーブルを作ります。
CREATE TABLE `visit_history2` (
`player_id` VARCHAR(255) NOT NULL,
`tenant_id` BIGINT UNSIGNED NOT NULL,
`competition_id` VARCHAR(255) NOT NULL,
`created_at` BIGINT NOT NULL,
PRIMARY KEY (`tenant_id`, `competition_id`, `player_id`)
) ENGINE=InnoDB DEFAULT CHARACTER SET=utf8mb4;これもplayer系のエンドポイントの高速化にあまり影響がないため点の伸びにはつながりません。
13:30(4982)
GET /api/player/player/:player_idのon memory cacheで解消されるのとは別のN+1問題を1クエリにまとめることで解消します。
これはplayer系のエンドポイントの高速化に直結するのでしっかり点が伸びます。
この点の増加により、「player系のエンドポイントの高速化が点数増加のキー」という予想がまず間違いないと判断します。
13:40(5501)
先ほどの変更でGET /api/player/player/:player_idのコードを触ったことで、on memory cacheの実装でplayerの取得の置き換えを忘れていたことに気づき、修正します。
これによりGET /api/player/player/:player_id,/api/player/competition/:competition_id/ranking,POST /api/organizer/competition/:competition_id/scoreが全て高速化され、点が伸びます。
15:15
複数台構成のためにMySQLへの移行を試みるも失敗し、断念します。
アプリケーションのCPUが張り付いており、それが最後まで変わらなさそうなことから複数台構成をするべきと考えました。
そのためにsqliteのままではデータの共有が難しいと考え、それまで実装コストを考えて放置していたSQLiteからMySQLへの置き換えに着手します。
後から冷静に考えるとtenantごとでのリクエスト振り分けの方が実装コスト対効果がどう考えても良いので、ここでこの手は完全に悪手だったと思います。
用意されていたsqlite3-to-sqlを利用することでデータをMySQLに入れるところまでやりましたが、initializeを時間内に収める実装とplayer_scoreが1テーブルになることによる速度低下を改善する実装がすぐに思いつかず断念します。
16:40
次の手がすぐに思いつかなかったので、とりあえずアプリケーションのlog出力をoffにしたところ、なぜか不整合でエラーが出るようになり、その解消をします。
最初、流石にlog出力offと不整合に全く思い当たらず、DBのデータの初期化や、使っていなかったインスタンスへの移動など試みますが、直らずにかなりの時間をロスします。
最終的に変更を順番に戻していったところlog出力offがきっかけのようだ、ということがわかり、log出力を戻します。
log出力が直接問題の原因になるとは考えづらいので、速度向上により何処かで不整合が発生するようになった、と考えるのが自然な気はするのですが、まだ原因の特定はできていません…
ここで1時間半近くロスしたのは本当に痛かったです…
17:00(5718)
fgprofでGET /api/player/player/:player_idの処理時間をそれなりに食っていたretrieveCompetitionの高速化と、player系APIの多数のN+1の解消のためにcompetitionをon memory cacheします。
17:50(6048)
rankingのSELECT文の高速化を狙ってLIMITをかけに行きますが、書いたSQLがSQLiteだと思ったように最適化されてくれないようで逆に速度が落ちてしまいrevertします。
最後に計測を切ってベンチマークをして終了しました。
反省と感想
技術面での反省は分析力と実装コストを見積る力の不足の2点に尽きるかな、という気がします。
後から他のチームの話を聞いて、自分のやっていない改善としてPOST /api/organizer/competition/:competition_id/scoreのinsertをbulk insertに変更するものがありました。
latencyがかなり悪いことは認識していましたが、totalの処理時間内での比率を見るとGET /api/player/player/:player_id,/api/player/competition/:competition_id/rankingと比べて少なかったため、後に回すのが正解と判断していました。
しかし、コードをちゃんと見ると修正がかなり楽で、多く見積もって5分あれば入れられるぐらいと感じました。
まだベンチマーカーが公開されていないので確証はないですが、playerの挙動を考えると、ここが遅いとplayer増加の妨げとなり他のplayer系エンドポイントへの流量が減る原因にもなりそうです。
これを考えると、ここの改善が入れられるだけで楽にそれなりに点を伸ばせたのではないかと思います。
この辺りを考えると、分析力と実装コストを見積る力の不足が点数の伸び悩みの原因だったのかな、と思います。
来年こそ、しっかり予選を突破して本戦でのリベンジができるよう頑張りたいと思います。