
19JKのなぽりんです。
3Qは教養卒論と研究プロジェクトが重なっててなんか毎日忙しいなあって言いながら虚無を過ごしています。期末までに激重課題がたんまり降ってきそうなので破滅が見えててつらいです。
さて、今回はその研究プロジェクトの一環として取り組んだHLSチャレンジについて話したいと思います。私は高位合成(HLS)に関して全くの無知だったのでそこについても適当に触れます。
HLSチャレンジって何
HLSチャレンジは、高位合成を用いて与えられた問題をどれだけ高速化できるかを競うサイトで、アダプティブコンピューティング研究推進体(ACRi)が運営しています。2021年8月に生まれたばかりのサービスで、競技人口が少なく、付随する情報も少ないため、かなり手探りな状態で取り組むことになりました。
AtCoderなどの競技プログラミング界隈では、ggればいくらでも実装テクニックが出てきます。それに比べHLSチャレンジでは、情報がほぼマニュアル頼りになってしまい初心者が参加するハードルが高かったので、そのハードルを少しでも下げるために紹介を兼ねてこの記事を書くことにしました。
https://acri-vhls-challenge.web.app/
高位合成って何
そもそも高位合成とは、ハードウェア記述言語(HDL)をC言語などソフトウェア用の言語を用いて自動的に合成(コンパイル)できるようにする技術のことです。ハードウェア記述言語としてはVerilog HDLやVHDLが挙げられますが、これらを使って回路合成するためにはレジスタ転送レベル(RTL)での記述が必要で、ソフトウェア言語に比べて習得の難易度が高いです。そこで、レジスタやクロックタイミングの管理を自動化し、アルゴリズムのみに焦点を当てて簡単に記述できるというのが高位合成の強みです。
ハードウェア実装の抽象化度のレベルとして、ゲートレベル/レジスタ転送レベル/ビヘイビアレベルという3つの段階があります。ゲートレベルはAND,OR,NOT等のみで構成される記述、レジスタ転送レベルは組み合わせ回路等の記述(ifとか使える)、ビヘイビアレベルは動作(forとか使える)の記述を行います。ソフトウェアでいうと機械語/アセンブリ言語/高級言語の段階に対応するような感じです。
HLSはビヘイビアレベルをレジスタ転送レベルに変換することができる技術で、C言語をコンパイルしてアセンブリ言語に変換するようなものです。しかし、HLSはそこまで普及してるわけではなく、今どきアセンブリ言語でソフトウェアを作る人はほぼ居ませんが、ハードウェアにおいてはRTLでの記述が多く用いられています。
HLSで高速化してみよう
通常、C++で書かれたプログラムはコンパイラによってアセンブリ言語に変換され、見かけ上1つ1つの処理が逐次的に実行されます。高位合成による変換でも同様で、通常はC++と同様の動作をするようにRTLの記述が設計されます。これに対し、並列実行できる領域、パイプライン実行すべき領域などの情報を与えてやると、高位合成ツールはそれに沿った設計を試みます。設計が上手くいけば、for文等の展開(並列実行)が可能となるため、高速な処理が可能になります。そして、その指示を行うのがプラグマで、Xilinx社が提供するHLSツールでは#pragma HLS xxxxxの形式で記述できます。
高速化のポイント
- 入出力配列へのアクセスが多い場合はバッファを用いる
- 入出力配列をストリーム化する
- for文は展開して並列実行できるようにする
- for文はパイプライン実行できるようにする
バッファを用いる
入出力配列への読み書きは、モジュール外とのやり取りが必要となるので時間がかかる場合が多いです。そのような場合には、モジュール内に一時配列を用意し、入力をいったん読み込んでから処理を行うと効率がよいです(出力の場合は、処理を行ってから最後に書き込む)。
また、必要に応じてバッファの分割を考えましょう。指定をしない場合、配列は1本のBRAMを持ちいて実装されます。これは2つの読み書き両用ポートを持つので、1クロックサイクル当たり2つのメモリにアクセス可能です。多くの処理を並列実行したいとき、ポートが2つでは足りなくなることもあると思います。そんなときは、1つの配列を複数のBRAMを用いて実装させましょう。仮想的にポートが増えるので、より多くの並列処理が可能になります。ただし、個々のBRAMはやはり2つのポートしかもたないため、どのインデックスなら並列アクセスできるかというのはプログラマ側で把握しておく必要があります。
実装には#pragma HLS array_partition mode=block/cyclic/complete variable=arr_nameというプラグマを用います。主に2つの戦略があり、blockとcyclicです。両者の違いは要素を2次元に並べたときの分割の方向の違いで、12個の要素を持つ配列を3分割したときの挙動は下図のようになります。
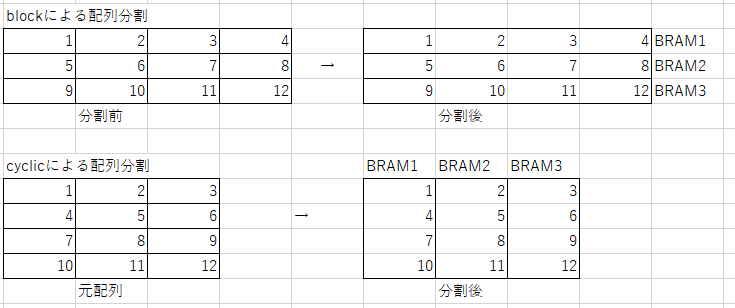
配列へのアクセスの仕方に合わせた分割をすることで、高いパフォーマンスを発揮できるようになります。なお、completeは配列を個々のレジスタに割り当てる(完全に分割する)形式になります。
入出力配列のストリーム化
通常、入出力配列へのアクセスはメモリマップド方式で実装されます。簡単に言えば、配列にアクセスするためにアドレスを用いてやり取りするため、遅いです。一方、配列の任意の要素にアクセス可能という利点があります。配列へのアクセスが昇順にできる場合、その配列をストリームとして扱うことが可能になります。ストリームは順次アクセスしかできない代わりに、高速です。#pragma HLS interfaceというプラグマを用いて入出力のインターフェイスを指定することが可能で、modeをaxisに指定すれば入出力が上記のようなストリームとして実装されます。
バッファと同様、より多くの処理を並列実行するためには分割を利用しましょう。
for文の展開(並列化)
for文においてループ依存性がない場合、そのループは展開して並列実行することができます。
例えば配列中の値の出現回数を数える以下のようなコードは、異なるループで同じインデックスにアクセスする可能性があるため、ループ依存性があるコードです。
int s[i_max_val];
for(int i=0;i<in_size;i++){
s[in[i]] += 1;
}
このような処理を並列化するためには、配列の書き込み先を分散させることが必要になります。そこで、「配列中の値の出現回数を数える」というタスクの分割を考えましょう。例えば、配列をいくつかに分割し、それぞれについて値の出現回数を数え、最後に足し上げる。という戦略が考えられます。それぞれの配列に関して値の出現回数を数えるタスクは、相互干渉しないため、並列実行が可能になります。最後に足し上げるという操作が余計に必要になりますが、並列化によるサイクル数削減の利点が上回るので高速になります。
実装の仕方は様々ですが、個人的に1次元配列の方が頭でごちゃごちゃこねくり回し安いので1次元配列で実装しました。
int s[i_max_val * 64]
for(int i=0;i<in_size;i++){
#pragma HLS unroll factor=64
s[(in[i]<<6) + (i&63)] += 1;
}
配列sの インデックスの下位6ビットをオフセットとして利用し、書き込み先が被らないように設計しています。これにより少なくとも64回単位でアクセス先が被ることはないので、64処理を並列で実行できるようになります。
これにより64個の小配列が出来上がるわけですが、最後にこれを足し上げる処理があります。単純な足し上げの実装は、以下のようになると思います。
int sum=0;
for(int i=0;i<i_max_val;i++){
sum += arr[i];
}
最初のループ依存の話を思い出してください。明らかにループ間でデータ依存が生じていますね。この実装だと、次のループの処理に移るために前のループの処理の終了を待たなければいけないうえ、並列化も当然行えないのでかなり時間がかかります。ここの部分もうまいこと実装するといい感じに高速化できるのでぜひチャレンジしてみてください。また、最後に私が実装した見るも無残なCコードを載せるので、参考にしてみてください。
パイプライン化
例えば、上述の足し上げの処理に少し手を加えて、次のようなコードを考えてみましょう。
int sum=0;
for(int i=0;i<i_max_val;i++){
sum += arr[i];
arr[i+1] = func(sum);
}
このコードには、命令間でのデータ依存(funcを実行するためにsumの値が必要)と、ループ間のデータ依存(次のループのsumを計算するためにはarr[i+1]の計算を待つ必要がある)があります。このようなコードの場合、処理が行単位で逐次的に実行されます。
一方で、別のコードを考えてみます。(似た記述ですが、処理結果は全く別)
int sum=0;
int some_arr[i_max_val];
for(int i=0;i<i_max_val;i++){
sum += arr[i];
some_arr[i] = func(sum);
}
このコードには、やはり命令間のデータ依存性(funcの実行にsumの結果が必要)と、ループ間のデータ依存性(次のループのsumを計算するために前の命令のsumの計算結果が必要)があります。しかし先ほどとは異なり、sumの計算を行った次のサイクルで次のループのsumの計算を行うことが可能です。つまり、funcの処理を待たずに次のsumの計算を行えるので、そこの処理が同時に行えます。これによりパイプラインが実現されます。
命令間・ループ間のデータ依存を避けるように記述すれば、パイプライン化はある程度自動でやってくれます。明示的にしたい場合、#pragma HLS pipelineというプラグマが使えます。オプションでレイテンシや深さも指定できますが、設計制約がなければ自動でいい感じにしてくれるはずです。
for文の展開とパイプライン化は似て非なる概念なので、頭の中で混ざらないように注意しましょう。
チャレンジ:histgramの実装
上記のテクニックを用いてhistgramという問題に取り組みました。以下のコードによるタイムは1142nsで、ベースライン(素朴な実装)によるタイムが9132854nsなので、およそ8000倍の高速化に成功した計算になります。
上記で紹介しているテクニックのみでコンテスト1位を獲得することができました。競技人口が少ない分、頑張れば1位もそこそこ狙えるので競プロはプロがプロすぎて辛いみたいな人は参加してみるといいかもしれません。
#include "kernel.hpp"
void kernel(
const uint8_t in[8192],
const int size,
uint16_t hist[256]
) {
static uint16_t tmp[256*64];
static uint16_t tmp2[256*16];
#pragma HLS array_partition cyclic factor=64 variable=tmp
#pragma HLS array_partition cyclic factor=64 variable=tmp2
#pragma HLS array_partition cyclic factor=32 variable=hist
#pragma HLS array_partition cyclic factor=64 variable=in
#pragma HLS interface mode=axis port=in
#pragma HLS interface mode=axis port=hist
for(int i=0;i<size;i++){
#pragma HLS unroll factor=64
tmp[(in[i]<<6) + (i&63)] += 1;
}
for(int i=0;i<256*16;i++){
#pragma HLS pipeline rewind
#pragma HLS unroll factor=32 skip_exit_check
int k=i<<2;
tmp2[i] = (tmp[k] + tmp[k+1]) + (tmp[k+2] + tmp[k+3]);
}
for(int i=0;i<256*4;i++){
#pragma HLS pipeline rewind
#pragma HLS unroll factor=32 skip_exit_check
int k=i<<2;
tmp[i] = (tmp2[k] + tmp2[k+1]) + (tmp2[k+2] + tmp2[k+3]);
}
for(int i=0;i<256;i++){
#pragma HLS pipeline rewind
#pragma HLS unroll factor=32 skip_exit_check
int k=i<<2;
hist[i] = (tmp[k] + tmp[k + 1]) + (tmp[k + 2] + tmp[k + 3]);
}
}
マニュアルを読もう
今まで長ったらしく高速化の手法を述べてきました。これらは全てXILINX社提供のユーザーガイドを読んで雑に解釈した内容になります。そのため、最終的にはユーザーガイドを読むのが一番だと思います。しかし、XILINX社のマニュアルは読みにくいことに定評があるらしく、例にもれずこのマニュアルもかなりわかりにくい内容となっていました。定義・動作の説明はあるが、具体的にそれを用いるとどのようになるのかが非常に分かりにくく、難儀した記憶があります。そのため、本記事においてはなるべく具体例を挙げ、直感的に理解できる内容にしました(したつもりなだけかも)。
参考までに、私が何度も読み直したサイトを紹介しておきます。
インターフェイスの定義
SDAccel 開発環境ヘルプ (2019.1 用) HLSプラグマ
おわりに
以上のポイントを押さえることができれば、あなたはHLSチャレンジランカー間違いなしです。仕組みがわかって高速化できるようになると楽しいので、ぜひチャレンジしてみてください。
明日は@Uzakiさんが怪奇創作について記事を書いてくれるそうです。そろそろ寒くなってきたのでこたつでアイスを食べながら読むのがおすすめです。楽しみ~