
この記事は,traP夏のブログリレー2020・26日目の記事です.
はじめに
YumizSuiと言います.貴重な18Bの新入部員です.SysAdでくねくねと活動をしています.
今年の夏休みはコロ助の影響でどうにも屋外活動する気になれない.かと言って無為な夏休みを消耗するのもナンだということで,岡崎研でやってると噂の言語処理100本ノック 2020をやってみました.
ちなみに言語処理100本ノックって何?
これ
言語処理100本ノックは,実用的でワクワクするような課題に取り組みながら,プログラミング,データ分析,研究のスキルを楽しく習得することを目指した問題集です.
らしいです.10本で1章×10で100本というスタイルになってます.
終わってみると色々と得るものがあったのでこの場を借りて紹介してみたいと思います.解説記事ではありませんのでご了承ください.
なお,自分は言語処理に関する知識はほとんどゼロに等しい状態からスタートしましたが,ググれば割となんとかなりました.詳細が気になる人はネットに答え転がっていたり解説記事が上がってるのでそういうの見るといいと思います.
環境
1〜5章
- Windows10+WSL
最初は手慣れた環境でやってましたが,windows10の環境構築がしんどすぎて脱北しました.condaをWindowsで動かしてたのが災いして一日環境構築で潰した結果うまく行かなかったという背景があります.Windowsでやるなら完全にWSL上で完結させるのが良いかと思います(そうするとGPUとか面倒そうだけど).
6〜10章
- Manjaro Linux
初心なる人々はLinuxを信ぜよ.さらば救われん.
ガチプロなおLinux以て精進を遂ぐ,況んや初心者をや.
と昔の人も言っています[要出典].初心者こそLinuxを使ったほうが良いということですね!(個人の見解です)
その他
- Google Colaboratory Pro
実はGPUが使えてない!ことに10章で気がついた.というか10章は全体的に個人でやるにはやや辛いのでどのみちGoogle Colaboratoryに頼らざるを得なかった.無料でも使えるが,データが消えないように定期的にアクセスする必要があり,面倒なので結局Proにした.おかげでtesra v100のような強いGPUの効能が知れたので良かった.環境構築めんどくさいのでこれ使うのはアリだと思います.ただ手違いで学習したデータが消えると本当に萎えるのでメイン使いはちょっと…って感じでした.月額$9.99/月に過度な期待はしないでください.
やる
GitHubに上げたリポジトリのコミットログなどを漁ってどんな感じに進めていったのか記録していく.開始日は8/18
1.準備運動
終了日:8/18
pythonの基本的な使い方など.やる必要はなさそうだが100本ノックなのでやる.「パタトクカシーーってなんですか?」
2.UNIXコマンド
終了日:8/18
UNIXコマンドと同じことをするというやつ.前処理のすゝめ.1,2章は3時間くらいで終わった.やるぞ〜とみなぎっていたらしい.
3.正規表現
終了日:8/20
Wikipediaのデータをろ過していく章.言語処理,全体的に前処理で苦労するんだなあという気持ち.pythonの正規表現は触ったことがなかったので半日かかったっぽい.
4.形態素解析
終了日:8/20
吾輩は猫であるの形態素解析をMeCabを使ってやりました.この辺からいよいよ自然言語処理だ〜〜って感じですよね.
この辺までは順調に行っていたので,8月中には終わるだろうとか思ってましたが甘かったようです.
5.係り受け解析
終了日:8/23

wikipediaの人工知能の章をかかり受け解析します.この辺から間隔が空いてますね.一日5タスクくらいでやってました.100本ノック以外にも何かと精進もしていたらしい.
係り受け解析は大変でした.何が大変かというとCabochaの環境構築です! これを機にLinuxで作業するようになった.一日潰れた作業がLinuxでは秒で終わるなどして呻いてました.
6.機械学習
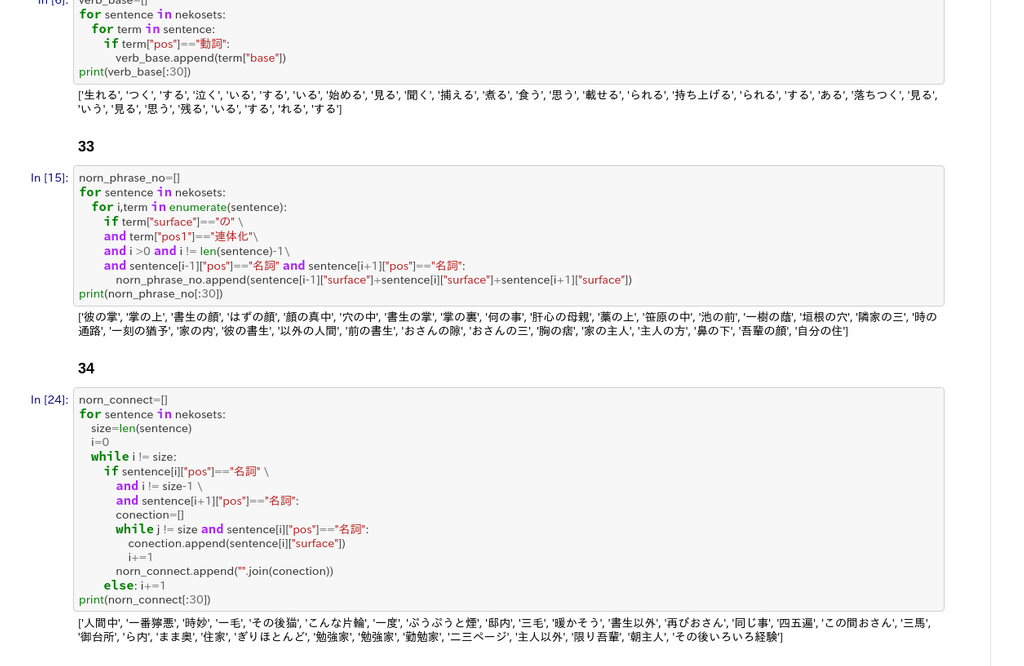
終了日:8/25?くらい
後半戦です.ここでは記事タイトルを元にカテゴリ分類を行うタスクを行います.上のように,素朴な機械学習でも9割くらいの性能が出ており,なるほど馬鹿にできない.このデータは以降の章でも使います.この辺は割と知ってるつもりでしたが,tqdmや,optunaなどは初めて使った.
7.単語ベクトル
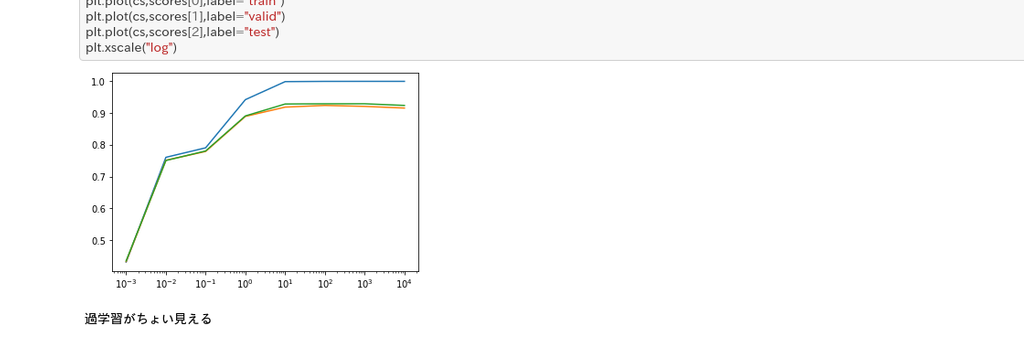
終了日:8/27
word2vecを使って国をクラスタ分類をします.この辺はグラフで出力できるタスクが多く,いろいろ分析できて楽しかったです.環境を移行する中途でgithubのデータが消えてしまってた:sadparrot:
8.ニューラルネット
終了日:8/31
ずっと左みたいなの見て学習進まないなあと思ったらアレだった pic.twitter.com/WqIfIwXsvd
— 湯水🐧水 (@YumizSui) August 31, 2020
pytorch, pytorchです.カテゴリ初めて触りました.思ったより簡単でびっくりしました.ハイパーパラメータの調整で無限に時間を使ってました.↑のは少しでも学習率を上げるとまともに学習できないのですが,epoch20くらいまでは全然学習進まなくて大変でした.学習率の感度を下げるにはどうしたら良いんでしょうね.GPUが使えないので(この時点では気づいてない)学習が遅くて大変でした.
9.RNN,CNN
終了日:9/3?
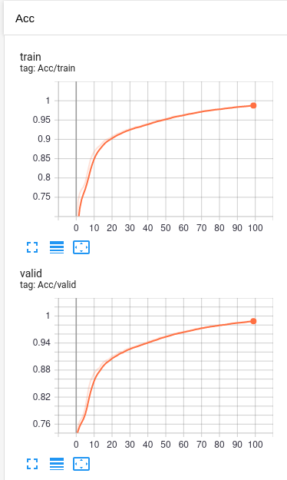
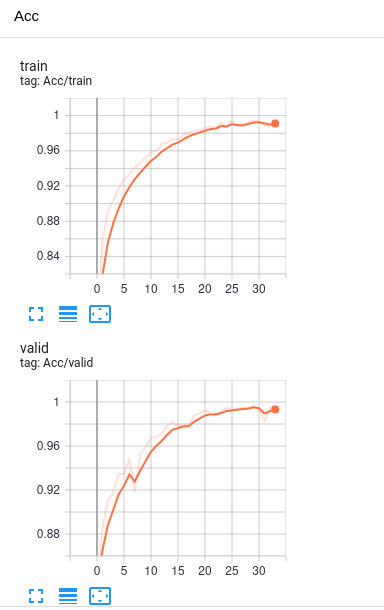
自然言語処理といえばRNNだと思ってましたが,LSTMにしないとまともにパフォーマンスがでなかった.この程度だとモデルの出来によってはCNNの方が良いという現象が起きるというのは手を動かさないと分からないなと思った.この辺はライブラリの力が強いのでそんな苦労しなかった気がする.
10.機械翻訳90~98
終了日:9/5?
これはニューラル機械翻訳の既存のツールを用いて機械翻訳をする回.この章は割とニッチな内容が多くて調べる時間のほうが多かった.fairseqのコマンドを叩いて学習していたので一応動くけど何だろうこれ? という感じではあったので,気が向いたら論文でも読もうかしらん.
ただ,この章はちょっと出来たとは言い難い.全然性能が出ない.答えを公開している人の数値と照らし合わせても数値が噛み合ってないので謎だった(損失が同じくらいなのにBLEUスコアが数倍違う等).
Google Colab Proを使ったのでtesla v100の計算力を体感できたが,それでもすごい時間がかかる.深層学習の発展が計算リソースの拡大に依るところが大きいのだな,というのは分かっていたけれど驚きがあった.
そして
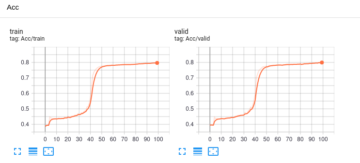
最終課題: 99.翻訳サーバの構築
終了日:9/20
終わる目処が立ったので割とのんびりやってました.
最終課題のラスボス感しゅごい.
traPに入って少しずつwebに触れるようになったものの,自前で一個作ったことはなかったので,この機会にちゃんとやってみることにした.
実は,traPではWebエンジニアになろう講習会という,余裕で2-3単位くらい出そうな講習会をやっています.自分も新入生(18B)として参加しましたが,その最終回でも何かwebアプリケーションを作るという課題が出てました(ここまで到達した人は少なそうですが).
本当はtwitterクローンとかを作るのだけど,せっかくなので100本ノックと一纏めにしてやってみました(認証などをする必要ないのでこっちのほうが難易度は低いけど).
やる
Golang+Vue.jsでやります.作ったwebアプリケーションはshowcaseと呼ばれる静的なコンテンツを配信するための部内向けPaaSサービスを用いました.
やった
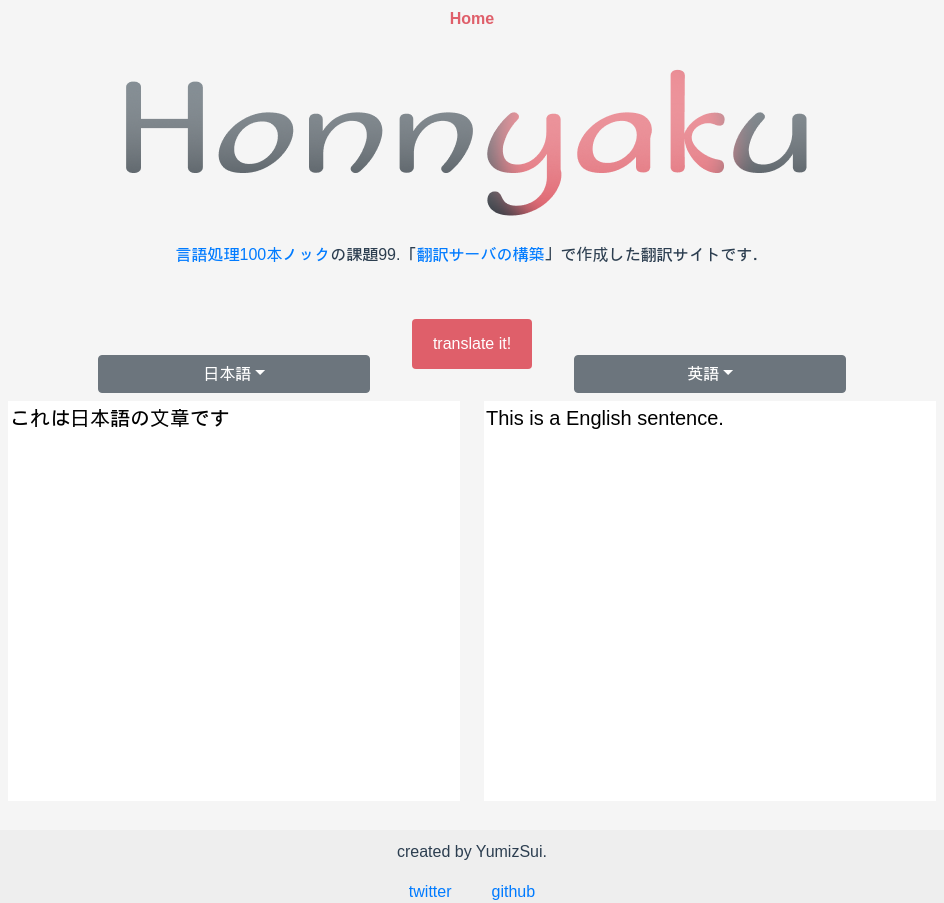
初めてにしてはという感じ.ちなみにロゴはfigmaで適当に作りました.
当初は公開する予定でしたが,モデルが大きすぎてこれをアップロードするのが流石に憚られるのでキャプチャするだけに留めておきます.
一応ハリボテのHonnyakuが立っています.APIを叩くと,翻訳はしないで決まった文章をレスポンスとして返します.
で,翻訳機能の方はどうなんですか?



…以上です.
完走した感想
言語処理100本ノックに挑戦する前の自分のスキルはおおよそ,
- 自然言語処理:かかり受け解析,構文解析などが存在するというのを知っている程度(実際にどうやってるのかは知らなかった)
- 機械学習:scikit-learnの範囲でできるようなデータ分析は結構やっていたが,深層学習は本の知識だけ.
- Python:基本的な処理はできる.前述のようにニューラルネットを扱うようなライブラリを実際に使ったことはない.
- web:やるようになったのは今年入部してから.自分で1から作ったことはない
といった感じでした.これが,言語処理100本ノックを通じて,
- 自然言語処理:原理についてはあまり知識は深まらなかったが,実際に手を動かして云々するときの作法が分かった.
- 機械学習:かなり色々なことができるようになった.pytorchを使って一から整形されたデータや学習モデルを組み上げられるようになった.深層学習に限らずkaggle(やったことないけど)のように実践的なテクニックが求められても対応できるようになったはず.
- python:前処理で散々苦しめられた.
- web:簡単かつまともに使えるものではないが,独力で完成物を作ったという経験が得られた.
こうなった.
手を動かしてゴニョゴニョするという方面で圧倒的成長!が感じられました.
もともとインプット過多アウトプット皆無型の人間だったので,このようにタスク型で進めていくスタイルが合っていたと思います.
一方で形態素解析やかかり受け解析,自然言語処理そのものの理論や,最終章の機械翻訳などはあまり理論が抑えられなかったので,あとで勉強したい.
機械学習に関しては副読本としてゼロから作るDeepLearning2を読んだのが結構良かった(7〜9章の理論的背景の基礎が手っ取り早く固められた).以前にDEEP LEARNING BOOKを輪講したことがありましたが,100本ノックを通して知識と実際の結びつけに成功したように思います.
言語処理100本ノックは各々の粒度に合わせて進めていけるのが良き!と思いました.調べてみるとpythonやったことないという人でも,自然言語処理を既に研究している,実務で使ってるという人でも楽しめる幅の広さがあるように思います.
おわりに
いかがでしたか?????
今年はイレギュラーが過ぎて,この状況が良いのか悪いのかもさっぱりしない様相ですが,それはそれとして今できることに手を付けてみるのも良いかと思います.
また,traPに入ってなければ,特に最終課題は完成させられなかったし(モチベ的な意味も含め),記事にすることもなかったと思うので,入部してよかったなと思いました.
明日はMochoさんのflashの希望と未来についてらしいです.お楽しみに!