
この記事は 新歓ブログリレー2026 29日目の記事です。
はじめに
皆さんこんにちは。24Bの @zoi_dayo です。traPの代表をしたり、最近は競技プログラミングに復帰しかけたりもしています。
本題
競技プログラミングというものをご存知でしょうか。数学とか算数パズルっぽい問題が出題され、それの答えを計算するプログラムを書いて提出すると点数がもらえるというゲームです。
さて突然ですが、次のような問題 があります。

足し算をするだけのようです。簡単ですね。プログラムを書かなくてもいいなら小学生でも解けるでしょう。
プログラムに起こすと次のようになります。
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
int main() {
int t;
cin >> t;
for (int i = 0; i < t; i++) {
ll a, b;
cin >> a >> b;
cout << a + b << '\n';
}
}
ところが、これを実行してみると思ったより時間がかかってしまいます。

一体何が悪いのでしょうか。
制約をよく読むと、足し算は最大 回要求されることが分かります。とはいえ、競プロ界隈では「1秒におよそ 回くらいの計算ができる」とされています。単なる足し算なのに、予想より20倍くらい遅くなっていますね。
では足し算が遅い処理なのかというとそんなことは無さそうです。CPU内部のALUには加算専用の回路があると思われますし、うまくやれば CPU 1clock 程度で終わらせられそうですね。
では足し算以外のところが問題になっているはずです。足し算以外のところ...
cin >> a >> b;
cout << a + b << '\n';
ここですね。
入出力は、遅い
入出力というのは非常に遅いです。まず、競プロの実行方式であれば、おそらくディスクからの文字列の読み取りが発生します。仮にファイルがHDDに配置されていた場合、この時点でディスクをくるくる回してデータを読み取る必要があります。
また、文字列を読み取るだけではなく、それを10進数文字列から2進数の値に変換し、数値型に収める必要があります。
今回の制約の場合、値は20桁弱くらいになります。と考えると、数値が2 x 10^6 個とはいえ、文字としては 文字程度です。時間がかかるのも納得ですね。
というわけで、今回はこれをどうにかしようというお話です。
cin/coutは、遅い
まず、デフォルト状態では cin/cout は遅いです。次のような場合に対処するためです。
cout << "名前を入力してください>";
string name;
cin >> name;
coutなど、「画面表示」というのは重いのでできるだけサボりたいです。ので、coutは「値を入力したらすぐ更新するのではなく、すぐまた更新され直すかもなのでしばらく放置しておく」といった工夫が行われています。
しかしこの場合、cinで入力待ちを始める前に、coutの文章が表示されている必要があります。ので、cinの待機の前には、必ず「coutがサボっているデータがあればちゃんと出力する」という工程が挟まります。
でも、競プロではこんな親切な機能は要りません。無効化しましょう。
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
int main() {
ios::sync_with_stdio(false); // 追加行その1
cin.tie(nullptr); // 追加行その2
int t;
cin >> t;
for (int i = 0; i < t; i++) {
ll a, b;
cin >> a >> b;
cout << a + b << '\n';
}
}
ついでに、( cin/cout 以外の入出力方法である) printf scanf との連携も解除しました。使わないですからね。
これで速度はどうなるでしょうか。

10倍になりました。めでたし、めでたし。
もっと
早くなって喜んでいる場合ではありません。最速の人はどのくらいの速度なのか見てみましょう。
投稿時点での最速は この提出 です。

どうやら、もっと早くできるようです。やりましょう。
自前バッファリング
先ほど、「画面表示は遅い」「ので、何文字か溜まってから出力する機能がある」と言いました。
でもここは競技プログラミングです。「何文字か」ではなく、「全部貯めておいて最後に全部出力する」でも良いでしょう。
また、入力もちまちまと読んでいたら大変です。全部を一気に一回で読んでしまいましょう。
まず入力です。cinを使わずに入力を受け取る方法はいくつかあるのですが、Linuxのmmapという機能を使うとかなり速いです。 (Codeforcesでは動かなかった気がするので気をつけましょう)
#include <sys/mman.h>
#include <sys/stat.h>
struct FastIn {
char* buf;
char* pos = buf;
FastIn() {
struct stat st;
fstat(0, &st);
buf = (char*)mmap(nullptr, st.st_size, PROT_READ, MAP_PRIVATE, 0, 0);
pos = buf;
}
ll nextNum() {
ll ret = 0;
while (*pos < '0' || *pos > '9') pos++;
while ('0' <= *pos && *pos <= '9') {
ret = ret * 10 + (*pos - '0');
pos++;
}
return ret;
}
} fin;
出力も、巨大な配列に書き溜めておき、プログラムの終了時に全部を吐き出すようにします。
struct FastOut {
char buf[1 << 26]; // 64MB
char* pos = buf;
~FastOut() {
fwrite(buf, 1, pos - buf, stdout);
}
void printNum(ll x) {
if (x == 0) {
*pos++ = '0';
return;
}
char rev[20];
int len = 0;
while (x > 0) {
rev[len++] = ('0' + (x % 10));
x /= 10;
}
for (int i = len - 1; i >= 0; i--) {
*pos++ = rev[i];
}
}
} fout;
ではこれでやってみます。
#include <bits/stdc++.h>
#include <sys/mman.h>
#include <sys/stat.h>
using namespace std;
using ll = long long;
struct FastIn { /* 省略 */ } fin;
struct FastOut { /* 省略 */ } fout;
int main() {
int t = fin.nextNum();
for (int i = 0; i < t; i++) {
ll a = fin.nextNum();
ll b = fin.nextNum();
fout.printNum(a + b);
*fout.pos++ = '\n';
}
}
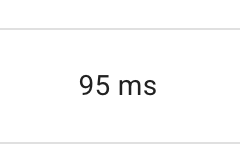
すでに半分になりました! やった〜
無駄を探そう
先程のコードの中で、無駄っぽいところを探してみましょう。
struct FastOut {
void printNum(ll x) {
// ...
char rev[20];
// ...
for (int i = len - 1; i >= 0; i--) {
*pos++ = rev[i];
}
}
} fout;
わざわざ rev に配置して、あとで逆順にしています。ちょっと面倒ですね。
なんでこんな事になっているかと言うと、はじめ桁数がわからないからです。桁数を求める関数があればいいですね。かといってlog関数とかは怖いし...
struct FastOut {
int getLen(ll x) {
if (x < 10'000) {
if (x < 100) return x < 10 ? 1 : 2;
return x < 1'000 ? 3 : 4;
}
if (x < 100'000'000) {
if (x < 1'000'000) return x < 100'000 ? 5 : 6;
return x < 10'000'000 ? 7 : 8;
}
if (x < 1'000'000'000'000LL) {
if (x < 10'000'000'000LL) return x < 1'000'000'000LL ? 9 : 10;
return x < 100'000'000'000LL ? 11 : 12;
}
if (x < 10'000'000'000'000'000LL) {
if (x < 100'000'000'000'000LL) return x < 10'000'000'000'000LL ? 13 : 14;
return x < 1'000'000'000'000'000LL ? 15 : 16;
}
if (x < 1'000'000'000'000'000'000LL) return x < 100'000'000'000'000'000LL ? 17 : 18;
return 19;
}
} fout;
これが一番でしょう。
また、四則演算の中では「割り算」だけ特に遅いことが知られています。ので回避しましょう。
割り算をどこで使っているかと言うと...
// FastOut内
while (x > 0) {
rev[len++] = "0123456789"[x % 10];
x /= 10;
}
この部分ですね。ここを、0000 ~ 9999 の文字列を事前に準備しておくようにすれば、割り算の回数が1/4になります。
ので、コンパイル時に文字列を埋め込み...
static constexpr auto LUT = [] {
array<char, 40000> res;
char *p = res.data();
char a = '0', b = '0', c = '0', d = '0';
do {
*p++ = a, *p++ = b, *p++ = c, *p++ = d;
} while (
d++ < '9' || (d = '0',
c++ < '9' || (c = '0',
b++ < '9' || (b = '0', a++ < '9')
)
)
);
return res;
}();
...それを使ってあげましょう。
void printNum(ll x) {
if (x == 0) { *pos++ = '0'; return; }
int len = getLen(x);
char* p = pos + len;
pos = p;
while (x >= 10000) {
int rem = x % 10000;
x /= 10000;
p -= 4;
memcpy(p, &LUT[rem * 4], 4);
}
while (x >= 10) {
*--p = (x % 10) + '0';
x /= 10;
}
*--p = x + '0';
}
これで早くなったのでしょうか。
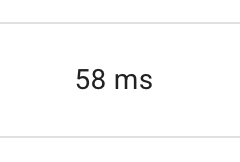
95ms → 58msです。(コードの見た目を無視してあげると) 大幅な改善ですね。
もっと..?
入力の読み取り、出力の書き込み、int→stringの変換を改善しました。あと残っているところといえば...?
string→intの変換ですね。
こうします。
ll nextNum() {
ll ret = 0;
while (*pos < '0' || *pos > '9') pos++;
ll tmp; // ここから追加
while (1) {
memcpy(&tmp, pos, 8);
if ((tmp -= 0x3030303030303030) & 0x8080808080808080)
break;
tmp = (tmp * 10 + (tmp >> 8)) & 0xff00ff00ff00ff;
tmp = (tmp * 100 + (tmp >> 16)) & 0xffff0000ffff;
tmp = (tmp * 10000 + (tmp >> 32)) & 0xffffffff;
ret = 1'0000'0000 * ret + tmp;
pos += 8;
} // ここまで追加
// (略)
}
これは何
急にマジックナンバーが出てきてしまいました。丁寧に考えます。
まず、文字列というのは char[] です。char は1byteです。
また、'0' という char は、2進数として解釈すると 48 = 0x30 と同じです。
ここで、次の処理を考えます。
char c = ?; // なにか適当に設定する
if((c - 0x30) & 0x80) cout << "No" << endl;
else cout << "Yes" << endl;
これが No となるのはどういう時かと言うと、「cが0x30未満であったとき」または「cが0xB0以上であったとき」のどちらかです。なるほど...?
ここは競技プログラミングの世界なので、cは '0' ~ '9', '-', '\n', '\0' のどれかであると仮定します。するとびっくり、これらのうち '0' ~ '9' 以外は No 判定となります。
すなわち、この処理は「それが数字であるかどうか」を判定している、とみなせます。
この視点でさっきのコードを見てみましょう。
if ((tmp -= 0x3030303030303030) & 0x8080808080808080)
break;
この部分は、「8文字すべてが数値かどうか」を判定していることになります。
これは何 (後半)
さてその続きです。次は0とFが多いですね。
先ほど tmp -= 0x3030303030303030 をしました。- ではなく -= です。
さて、現在 tmp はどうなっているでしょう。0x30 は '0' 、0x31 は '1' ...となっているので、「8bitごとに区切ってあげればそれぞれの桁の値になっている」わけです。
さて、この「8桁・桁ごとに0〜9まで」を「4桁・桁ごとに0〜99まで」にしましょう。隣同士の桁をくっつければいいですね。
tmp = (tmp * 10 + (tmp >> 8)) & 0xff00ff00ff00ff;
10倍したものと、8bitずらしたものを足し、いらないところを (0でANDを取って) 消すとよいですね。
あとは同様に、「2桁・桁ごとに0〜9999まで」「1桁・桁ごとに0〜99999999まで」と変換していけばいいですね。
...とすることで、string→int変換も高速化することが出来ました。

最速の2倍圏内まで来ることが出来ました。
おわりに
普通に競技プログラミングをしている場合、こんな工夫が必要になることはないです。このままだと負の数のデコードも出来ないし。でも楽しいのでOKです。
明日は @Charararu さん、@ramdos さんの記事が出るらしいです。楽しみ〜