この記事は、2026年2月に部内向けに書いたものを外部公開向けに書き直したものです。
はじめに
こんにちは。koukawa_pp です。
最近では ChatGPT や Gemini に代表されるように、言語生成AIがかなり流行していますね。
こういったものは大まかには機械学習という分野にくくられますが、中でもニューラルネットワークというものが超進化した結果生まれた産物といった方が肌感に近いように感じます。
ただこの言語や他には音楽や動画もそうですが、こういった可変長・時間方向にデータが存在するタイプのものを扱える技術については、お話を始めてしまうとかなり長くなってしまいますので、今回は固定長のもの、とくに画像処理というところに焦点を置いていこうと思います。
画像処理については相当昔からいろいろ試行錯誤されてきたもので、ライブラリもかなり充実してきまして、未だに機械学習を勉強するには良い題材であり続けています。
しかし、機械学習をやってみようとすると、Pythonでなんかコードを書かなければならないらしい?というのが一つ壁として立ちはだかります。
Python は今となっては Google Colaboratory などのサービスも登場してきて、ローカルにその環境を構築しなくてもまあOK, みたいになってきていますが、とりあえずあのおまじないみたいなコードは書かないといけない、というのはあるかなと感じています。
あといろいろ試してみるのはハードルが高い、というところはあるかもと思いましたので、今回は .NET という Microsoft が出しているフレームワークの中でも、クロスプラットフォーム対応されている MAUI というものを使って、機械学習を体験できるアプリを作ってみました。
そのコードについては こちらの GitHub リポジトリ の中にありますので、よろしければ使っていただけましたら幸いです。
開発環境
- Windows 11 Home
- Visual Studio 2026
また、今回のプログラムは一部 ChatGPT によるコーディング支援を受けています。
生成AIによる実装をほぼそのまま使用しているのは、
- ChooseImage メソッド (MLViewModel.cs)
- OnPaintSurface メソッド (MainPage.xaml.cs)
- DialogueService, IDialogueService クラス、インターフェース
それ以外の部分については、公式ドキュメントやサンプルプログラムをベースに、必要に応じてAIの支援を受ける形で実装しております。
公式ドキュメントやサンプルプログラムがある場合はリファレンスを示しますのでご利用ください。
機械学習について
まずこのアプリを使ってみるにあたり、機械学習についてちょっと説明いたします。
そもそも機械学習とは
そもそも機械学習とは、データが与えられたとき、それを元に機械が自動で分析や予測を行うよう学習することを言います。
今回取り組むタスクはその中でも分類タスクというものに当たります。
つまり画像が与えられて、それを適切に分類するというものです。
よく取り上げられるデータセットとして、MNIST という、0-9 が手書きされた画像のデータセットが
あります。
このデータセットがあれば、そのデータと画像に付与された0-9という正解(ラベル)を当てるように自動的に学習を行えばそれは機械学習になります。
ではどういうふうに自動で学習するのかということですが、方法としては人間の勉強の仕方と割合近いです。
- まずある問題について正解を予測する。
- 予測値と正解ラベルを比較して予測器(モデル)のパラメータを更新する。
- 上記の繰り返し。
です。人の勉強と対応付ければ、
- まずある問題を解いてみる。
- 答え合わせをしてみて、自分の考え方を改めたり自信を付けたりする。
- 上記の繰り返し。
です。なお、同じデータセットについて学習を繰り返した回数を「エポック」という単位で表現します。
この手続きを機械が行うにあたって、以下に示していく仕組みを用いていきます。
(ただし、このアプリを使うにあたっての最低限の知識です。興味がありましたら他の方のサイトを参照いただければ幸いです。)
データセット
データセットは先ほども挙げましたが、とくにこういった学習(教師あり学習と言います)では、データとそれのラベルのペアをいくつも集めたものを使います。
これは多すぎても少なすぎても難しいです。人間で考えてみてください。
問題集が多ければ、たくさんの問題を学習できますが、途方もない時間がかかります。
問題集が少ない場合は、対応できないタイプの問題が出てくる場合を否定できないです。
しかしその量がどれくらいが良いのかというのは、経験則で決められているくらいで一般に言われているわけではないのも難しさに拍車をかけています。
もう一つデータセットで大事なことは、訓練に使うデータと、訓練がうまく行っているかを確かめるためのデータ(検証・テストデータ)は分けるということです。
人間でも同じです。問題集に出てきた問題がそのままテストに出てきたら、十分に勉強できている場合は簡単に正解できますよね。
それはキチンとモデルが学習できているのか、単に暗記しているだけなのかが判別できません。
そのため学習の進度を確認するにあたっては、訓練に用いるデータと検証に使うデータを分けるのが原則です。
モデル
モデルの構築は、厳密かは怪しいですが高校数学的に言えば合成関数のようにできます。
つまり、機械学習でよく使われるものをいったん関数(一般にモジュールと言います)にしておいて、それを繋げてモデルを構築します。
以下に代表的なモジュールをいくつか紹介します。
線形層
まずすべてのニューラルネットワークの基本である線形層についてです。
これはかなり単純です。
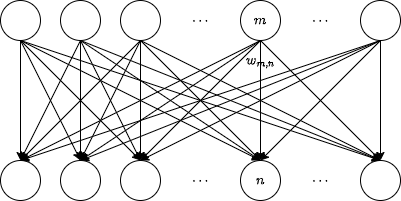
上記の○は上側と下側にあるものがそれぞれ入力、出力一つずつと考えてください。
そして上図では矢印が向いていますが、それぞれ重み付けされて値が渡されていると考えてください。
例えば 番目の入力から 番目の出力に渡される値の重みを とします。
このとき、 番目の出力は次のような式で表されます(ただし入力の数を として、 番目の入力を とします)。
ただ、これだと少し足りなくて、例えば入力の値が全て0だった場合を考えると分かります。
そうです、どのように重みの値を設定したとしても出力が必ず0に固定されてしまいます。
これを防ぐために、定数項(biasと呼ばれたりします)を足すのが一般的です。
この定数ももちろん学習して値を調整していきます。
今回のツールにおいては、追加できる線形層はすべて定数項を持ちます。
Convolution
次に、画像処理の革命児となった CNN をご紹介しますが、その前提として Convolution(畳み込み)を説明します。
ただ、Convolution の紹介をする前に、まず画像データの表現の仕方についてご説明します。
基本的に画像データというのは、二次元データに数字を並べて表現します[1]。
例えば、0-1 を取る実数を用意して、0だと黒、1だと白とすれば、あらゆるグレースケールの画像を表せます。
大きい画像を表現したければ、縦横のマスの数をそれぞれ増やせばよくなります。
しかし、カラー画像を表現したい場合もあると思います。その場合はこの二次元平面をいくつか用意すれば良いです。
例えば一つの表し方として、光の三原色の赤、緑、青を合わせる方法があります。
この三色をどれくらい混ぜ合わせるかを一つのマスあたり三つの数字を使って表現することで、あらゆる画像を表現できる、という寸法です。
この、「いくつ二次元データを用意するか」を、「チャンネル数」と言います。
それで、チャンネル数×縦×横の数だけ数字を用意すれば理屈ではどんな画像でも表現できるというわけです。
さて、ではこの画像を先ほどの線形層で扱うことを考えましょう。
チャンネル数×縦×横の数ぶんだけ入力を持つ線形層を考えればよくなります。
しかしこの方法だと、要は画像を二次元で解釈するのではなく、一次元に広げて解釈するということになりますよね。
どの程度性能が低下するかについては追々確かめていただくとして、少なくともその分の位置情報に当たる情報は捨てていることになるわけです。
なのでここで Convolution という、ある程度位置関係も意識できる層を導入していきましょう。
Convolution の計算は次のように行います。
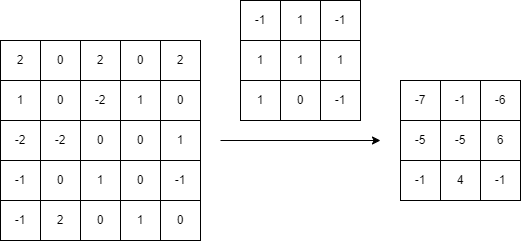
左の5×5の配列が画像だと思ってください。
そして、矢印の上にある3×3の配列をカーネルと呼びます。
まず、ターゲットの配列(5×5)の左上と、カーネルの左上のマスが重なるようにします。
そのとき、ターゲットの配列の左上3×3で、元の配列とカーネルに重なっている位置があると思います。
このとき、その重なっている要素を各々掛け合わせて、その後それをすべて足します。
結果の左上の-7の計算過程についてお示しします。ターゲットの左上3×3の要素は順番に2, 0, 2, 1, 0, -2, -2, -2, 0 ですから、それとカーネルの重み付け和を求めて、
と求められるという感じです。
一見複雑に見えますが、この畳み込みという概念は大変便利で、例えば全てのマスを1/9とかにすればその3x3の平均を取ることができますし、真ん中だけ8にして周りを-1にすれば、真ん中と周りの符号が異なる場合に値の絶対値が大きくなるのでエッジ(輪郭)検出に使えたりとなかなか使い勝手が良いです。
で、学習としてはこのカーネルの値を学習するわけですが、先ほどの平均やエッジ検出の例のようにすでに与えられたカーネルを使用する場合と違って、この学習を行う過程で、タスクを解決するにあたっては最も効果的なカーネルの値を学習できることで、より精密な画像解析を行えることが期待できるという寸法です。
追記ですが、この Convolution はパラメータがとても多いです。
今回のアプリについては、以下の4つの値を設定できます。
- Output channels
- Kernel size
- Stride
- Padding
Output channels, すなわち出力チャンネル数は、先ほどチャンネルの話をしたことそのままです。
この畳み込みで作る二次元配列の数をいくつにするか、というパラメータですね。
多ければもちろん表現力が豊かになることが期待できますが、その分学習にも時間がかかることに注意してください。
Kernel size はそのまま、カーネルの配列サイズをいくつにするかです。
Stride は、カーネルを一度にどれくらい移動するかを表します。上記の例では1です。
Padding は、ターゲットの配列の外側を、何マス分0埋めするかを表します。
これをすることによって、例えば畳み込み前と後で配列サイズを一緒にすることができるため使われています。
例えば下の例は、Padding を1にしたときの例です。
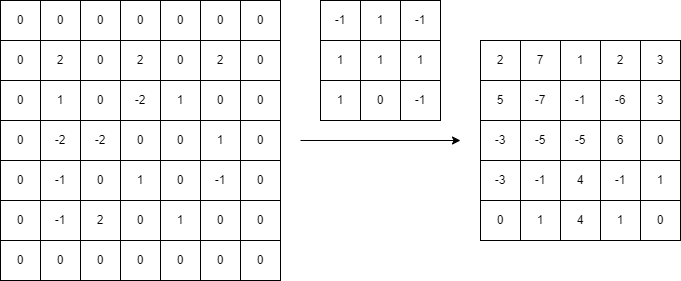
ご覧の通り、確かに Padding が1になることで、畳み込み前後で配列サイズを一緒にできています。
一応補足ですが、畳み込み前後で配列サイズを一緒にするには、Padding をカーネルサイズに合わせて調節する必要があります。
Pooling
次に Pooling 層について説明します。
ここでいう Pooling 層は、先ほどの Convolution よろしく、配列のある範囲について値を計算するなどして次元を落とす処理を言います。
当ツールでは MaxPooling を採用しています。これは非常に単純です。
あるカーネルサイズで囲まれている正方形の中の値において、最も大きいものをピックアップするだけです。
例えばカーネルサイズが2で、ストライドが2のとき、6×6の配列に適用してみましょう。
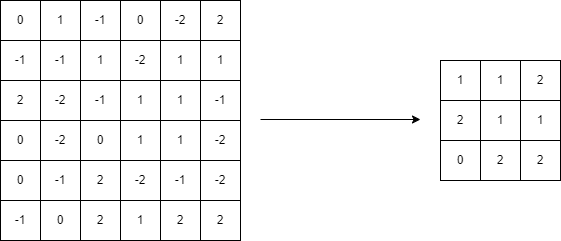
左上から2×2ごとに着目していって、その中の最大値を取りました。
これが MaxPooling です。
では平均のプーリングはあるのか、と思われるかもしれません。はい、あります。
それは平均を取ればよいです。簡単ですね。ただそれは今回実装に含めていないです。すみません。
Flatten
Flatten という操作を層の一つと捉えるか、というとひょっとすると賛否あるかもしれませんが、ここでは取っておきます。
Flatten は単純で、複数次元だったデータを一次元に並べる、というものです。
例えば6×6の配列のデータを36個の数字の並びにする、みたいな感じです。
この Convolution や Pooling は画像をそのまま扱えますが、線形層ではできないですね。
なので Flatten を使える(というより半ば強制的に挿入している)ということになります。
逆はあるのかということですが、もちろんできます。
ただもともとあった位置情報をいったん壊してまた作り変える、みたいなことをしている感じになります。
今回に関してはその実装は含めていません。
活性化関数
先ほどの線形層しかりこの Convolution しかり、これらは重み付け線形和となります。
したがってこのような層をいくつ重ねたとしても結局は線形変換となってしまい、表現力に欠けてしまうという問題がありました。
それを解決するために、層の後に挿入されたりするのが活性化関数です。今回は
- ReLU
- Sigmoid
- Tanh
の三つの関数が使えます。
詳しくは説明しませんが、これらを挿入することで線形だった変換を非線形にできるようになっています。
一般にはSigmoidやTanhを最終層以外の活性化関数にすることは少ないのですが、ここではものは試しということで使ってみてください。
CNN
説明が遅くなりましたが、CNN とはこの Convolution, Pooling, Flatten, Linear, 活性化関数を合わせてよしなにしたものと思ってよいのではないかと考えています。
今回のツールでは Conv2D や MaxPool2D を含めば基本的に CNN のようなものになっていると思っていただいてOKだと思います。
損失・最適化関数
最後に、損失と最適化関数について説明します。
最適化関数は様々なタスクを扱うにあたってもそんなに使うものを検討する必要はないので簡単な説明にとどめておくと、与えられた損失から、パラメータをより良い方向に更新するためのアルゴリズム、と思ってください。
今回は AdamW という最適化関数を用います。もっと簡単なものだと SGD と呼ばれる手法がよく見られるかなと思います。最適化関数の祖みたいなものです。
また今回スケジューラというものを用います。これは学習率という、パラメータの更新の度合いを指定する値の調整を行います。
皆さんもテスト直前にいきなり解き方を更新するというのは、よっぽど見たことのない問題を直前に勉強しない限りはしませんよね。
このように機械学習においても、学習が進むにつれてパラメータの更新度合いを小さくしていくということを行うことがあります。
損失についてもいろいろありますが、こちらはタスクによって使うものを変えたりすることが感覚として多いのと、分かると気持ちいいので少々説明します。
まず損失のお話をする前に、最終層となる線形層がどのように離散値を求めるかということについてご説明します。
例えば先ほどのように、0-9の数字を予測するタスクに取り組むとします。
このとき分類先(クラスということが主です)の数は10になります。
ではこのクラスを同定するにあたりどうするかというと、最終の線形層の出力の数を、クラスの数と一致させるのです。つまり10にします。
そうしてこのとき、各出力が、それぞれのクラスの確率であるとみなします。
各々のクラスが一体どれくらいの確率でそれらしいか、というのを表現するわけです。
しかしもちろんのことですが、この線形層の出力の和が1であるとは限りません。
それどころか線形層の出力が0より大きいことも保証されていないので、これでは確率として扱えません。
そこで、softmaxという活性化関数を用います。
この関数は、指数関数を用います。
指数関数であれば、指数にいかなる実数が与えられても0より大きいことが保証されるからです。
つまり各出力 について、 を考えます。
そうすると全てが正の値になります。
次にこれの和を1にすることを考えます。単純です。全ての和で割ればいいんです。
つまり先ほどの値から、以下の値を生起確率として求めます。
から上記の値を求める操作が softmax です(正確には、全てのデータについて上記の操作を行うのが softmax です)。
さて、話を戻しますと、今回は CrossEntropyLoss という損失を使用します。
これは平たく言ってしまえば、その正解クラスを出力する確率について対数を取り、その-1倍の値を損失にするというものです。
「損失」ですから低ければ低いほどよいです。
先ほどは正解クラスを出力する確率の対数の-1倍を損失にしたので、つまり正解クラスを出力する確率の対数は大きければ大きいほど良いです。
もちろん対数関数は増加関数ですから、正解を出力する確率が大きければ大きいほど良いことになります。
先ほど、softmax を適用することで 0-9 の各クラスの確率を求めましたね。それをここでそのまま使う感じです。
機械学習体験アプリ
では、いよいよ本題に入っていきましょう。
以下の内容は README にも載せております。
事前準備
ChatGPT によれば git clone して、Visual Studio で開くことによって、必要なライブラリがインストールされるようです。
なお MAUI ベースのため、macOS でも使用できることを想定しています。
その場合は、libtorch-cpu-win-x64 といった Windows 向けのパッケージを、macOS 向けのものに変更していただくと使えると思います(未検証です)。
使い方
アプリを開いていただくと、次のような画面が出てくると思います。
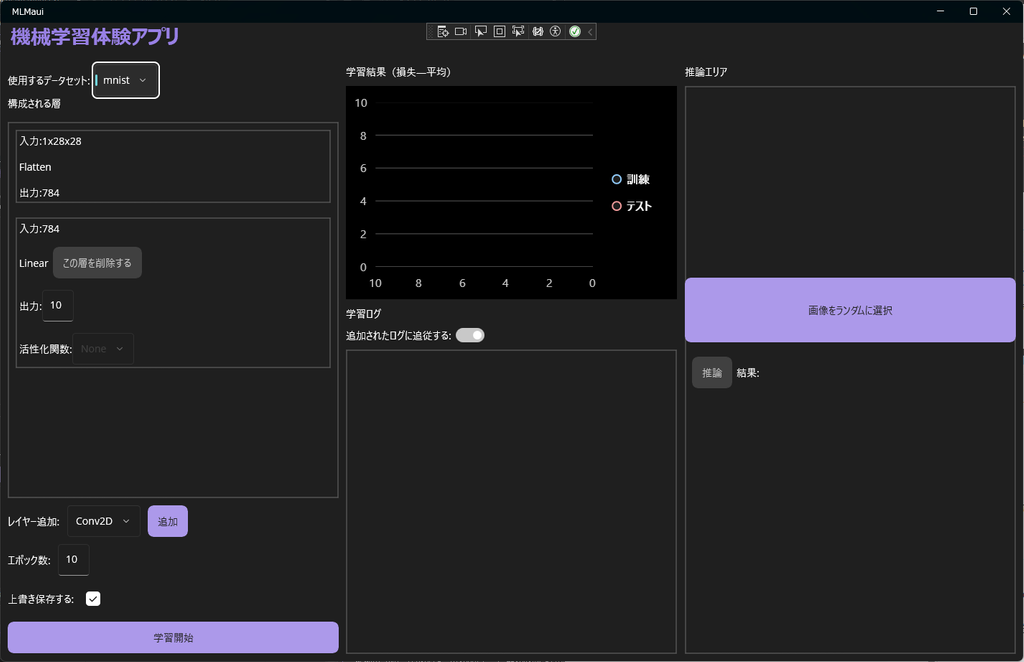
とくに下が切れている場合は、ウィンドウを大きくするなどお願いします。
以降は一般に次の手順で進めていただくとやりやすいと思います。
1. データセットの選択
「使用するデータセット」から使用するデータセットを選択してください。
現時点では
- MNIST
- CIFAR-10 (10種類のモノのうちどれであるかがラベリングされているデータセット)
- FashionMNIST(10種類のコーディネートのうちどれであるかがラベリングされているデータセット)
から選択できます。
2. 構成される層の設定
ここで、ネットワーク(モデル)を構成していきます。
まず初期時点で、Flatten と最終層の線形層がすでに追加されています。
この二つを削除することはできません。
その他の層は「レイヤー追加」で層を追加できます。
現時点では
- Conv2D(Convolution)
- MaxPool2D(MaxPooling)
- Linear(線形層)
から追加できます。
なお、Conv2D と MaxPool2D は次元が1次元になる Flatten の直前、Linear は最終層の後に追加されます。
なお、最終層を除く Conv2D, MaxPool2D, Linear の後ろには、活性化関数を設定することができます。
現時点では
- 活性化関数なし
- ReLU
- Sigmoid
- Tanh
から設定できます。
最終層は活性化関数なしで固定されます。
3. 学習開始
学習エポック数を設定して、「学習開始」ボタンを押すと学習が始まります。
「上書き保存する」チェックボックスが Off の場合、保存されるモデル名にはタイムスタンプが付与されます。
デフォルトでは <dataset名>.model.bin で保存されます。
学習ログは真ん中の列に表示されます。
上のグラフには、平均損失の推移が表示されます。
下のログエリアには、各バッチ(学習単位)における損失や評価データに対応する正答率が表示されます。
4. 推論
評価データをランダムに選択し、それについて学習済みのモデルで実際に推論できます。
「画像をランダムに選択」ボタンを押すと、画像を閲覧できます。
これは学習前でも可能です。
モデル学習後、「推論」ボタンを押すと、各カテゴリの確率と正解が表示されます。
この確率は、全てのカテゴリに対する softmax を取得したのち100倍したものです。
おわりに
今回は機械学習を体験できるアプリを開発し、ご紹介いたしました。
ぜひいろいろ遊んでみてください。
最後までお読みいただき、ありがとうございました。
資料・参考文献
Qiita 大好き人間なのでそこからいくつか
- ニューラルネットワークの超基礎的な動きを理解する -> 線形変換と非線形変換について、数式と視覚から説明されています。
- 畳み込みネットワークCNN (Convolutional neural network) -> CNN について詳しく説明されています。
- [E資格対策ノート] 活性化関数 -> 活性化関数について詳しく説明されています。
- [決定版] スーパーわかりやすい最適化アルゴリズム -損失関数からAdamとニュートン法- -> 最適化関数について、数学つよつよならほぼ完璧にマスターできると思います。
- PyTorchのCrossEntropyLossの解説 -> PyTorchとありますが、実際機械学習実装は今はまだPythonがデファクトスタンダードなので詳しくはこちらをマスターした方が良いと思います。今回はC#を書きたかっただけなんです。
大学数学では行列と言う方が一般的です。昔は高校数学でも一部扱っていたみたいですが、僕が高校生の時にはすでになくなっていて、ベクトルのみになっていました。 ↩︎