この記事は2024年9月に部内向けに書いたブログを外部公開向けに書き直したものです。
そのため古い情報があるかもしれませんがご了承ください。
はじめに
こんにちは。koukawa_ppです。
まもなく後学期が始まりますね。
また、東京科学大になって初めての授業とも言えます。
初めてと言えば、プログラミングをしている皆さんが、初めてプログラミングを触れるきっかけになったものは何ですか?
今となってはPythonとか、ひょっとするとガチな方はC言語から始めたという硬派な方もいらっしゃるかもしれません。
僕がプログラミングというのを始めたきっかけは、小学生の時親が紹介した「Scratch」でした。
今でこそ超メジャーで、バージョンも確か3までなってますが、その当時はまだバージョン1とかで、できることも数少なく、とは言えその当時はそれはそれで面白いと思えるものを作ってきました。
皆さんは「なでしこ」というプログラミング言語をご存じでしょうか。
多分ご存じの方が多いと思います。
日本語でプログラムできるという面白いものですね。
今回はこの「なでしこ」を使って、機械学習をやってみましょう。
事前準備
ではまず、なでしこについて少々ご説明します。
こちらがなでしこのトップページです。
なでしこには、実はいくつかの種類があります。
まずバージョンの違いですね。v1とv3があります。
今回はv3を使います。v1はいろいろ機能が豊富なようですが、macOSでは使えないみたいなので今回はv3を使います。
v3のマニュアルはこちらのページになります。
v3の中では、ランタイムの違いがあります。
ランタイムの中では、主にwnakoとcnakoがメジャーのようです。
まずwnakoとは、Web版で動かすためのランタイムです。
その名の通り、Web上で完結する、非常に簡潔なランタイムです。
Web版で動かすには、
https://nadesi.com/doc3/index.php?なでしこ3簡易エディタ
こちらの「簡易エディタ」を使うのが最も簡便な方法でしょう。
多分ちょっとしたものを動かすには何かと便利です。
ただこちらのランタイムは今回使いません。
理由は、今回の機械学習を行うためのプラグインが、wnakoには含まれていないためです。
cnakoなら利用できるみたいなので、今回はcnakoを利用します。
cnakoは、コンピュータ上で動かすためのランタイムです。
なでしこを自動処理のためなどで使用する場合はこちらのランタイムを使うのが良いでしょう。
というわけで、ここからはローカルにcnakoの開発環境を作っていきます。
https://nadesi.com/v3/doc/index.php?FAQ%2Fなでしこ3をインストールして使うには?&show#h9d970a9c
こちらの方法に従っていきます。
こちらの環境はWindowsなので、Windowsで使う方法に従います。
macOSの方はmacOSの方法に従ってください。
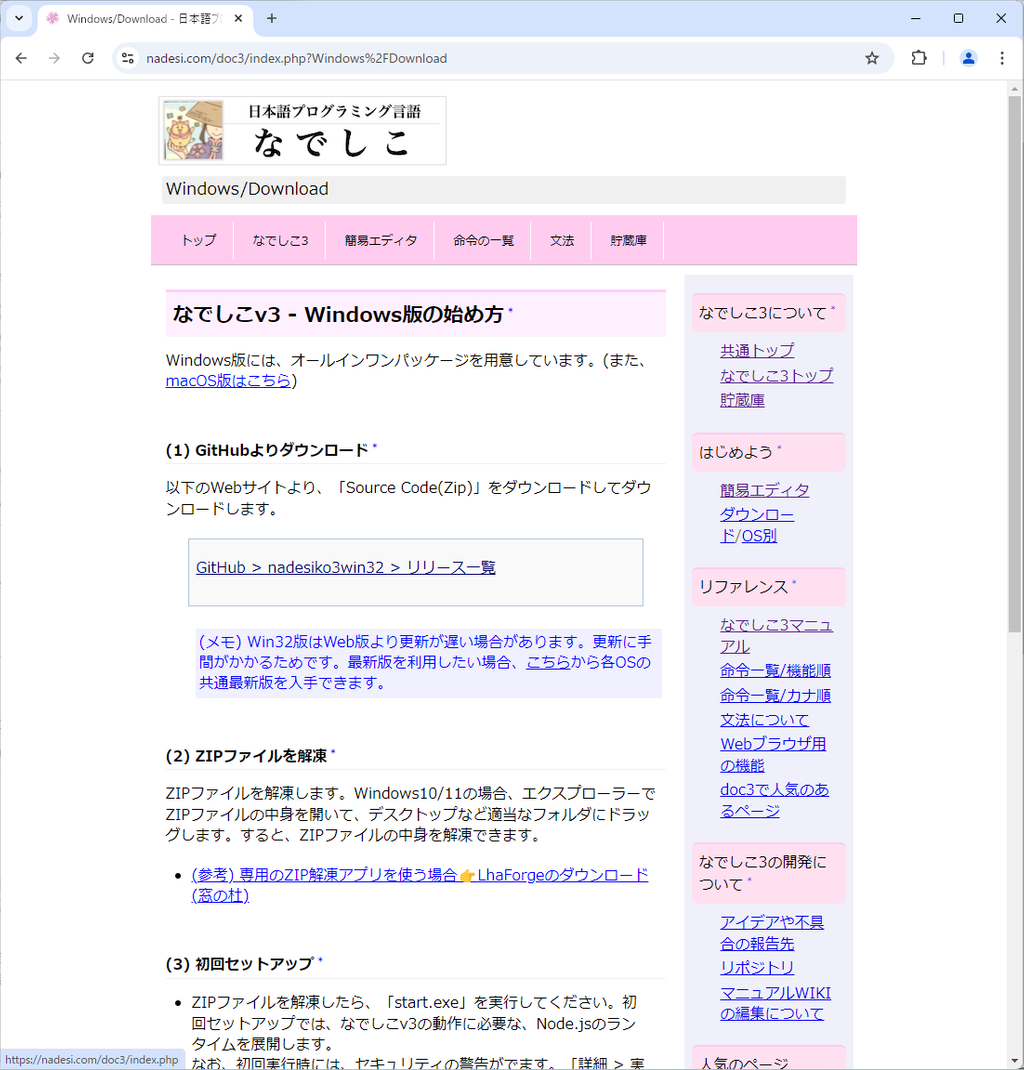
ここによれば、かなり簡便です。
- GitHubよりzipファイルをダウンロード
- ダウンロードしたzipファイルを解凍
- start.exeを実行する
Node.jsがひょっとすると必要かもしれません。
僕はすでにインストールしていたのでその周りは必要ありませんでしたが、必要に応じてインストールしてください。
あと解凍先は、場合によってはProgram filesとかにしといた方が良いかもしれません。
このフォルダが今後node_modulesをダウンロードする先になるためです。
あと、今後なでしこを使う場合は、start.exeを実行するだけでいつでも実行できます。
次に、機械学習を行うためのプラグインをインストールします。
Node.jsをベースに作られているので、npmでも一応用意されているのですが、
なぜかここで必要な「iris.js」というファイルが現時点(2024年9月25日)で存在しないので、GitHubのコードをクローンすることにします。
コマンドプロンプトで、node-modulesのフォルダを開きます。
そして、そのパスで次のコマンドを実行してください。
git clone https://github.com/kujirahand/nadesiko3-ml
kujirahandさんは、この「なでしこ」の開発者です。
このコマンドを実行すれば、このリポジトリのファイルがダウンロードできるので、機械学習周りが使えるようになります。
謝辞
今回なでしこのコードをこの記事に載せるにあたり、
TKIさんのなでしこスクリプトをhtmlに変換に非常にお世話になりました。
この場を借りてお礼申し上げます。
この下の埋め込みから使えます。
これすごいんですが、実はこれなでしこで作成された作品のライブラリ「貯蔵庫」にあるもので、実はそのページに行くとソースコードをすべて見られます。
もちろんなでしこ製です。
なでしこを使ってみる
では、実際になでしこを使ってみましょう。
start.exeを実行すると、次のようなウィンドウが出てくるはずです。
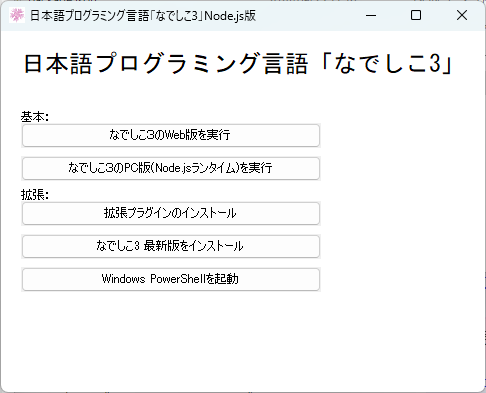
ここでは、「なでしこ3のPC版(Node.jsランタイム)を実行」を選択してください。
これを押すと、どうもローカルサーバが立ち上がり、その上で動くみたいです。
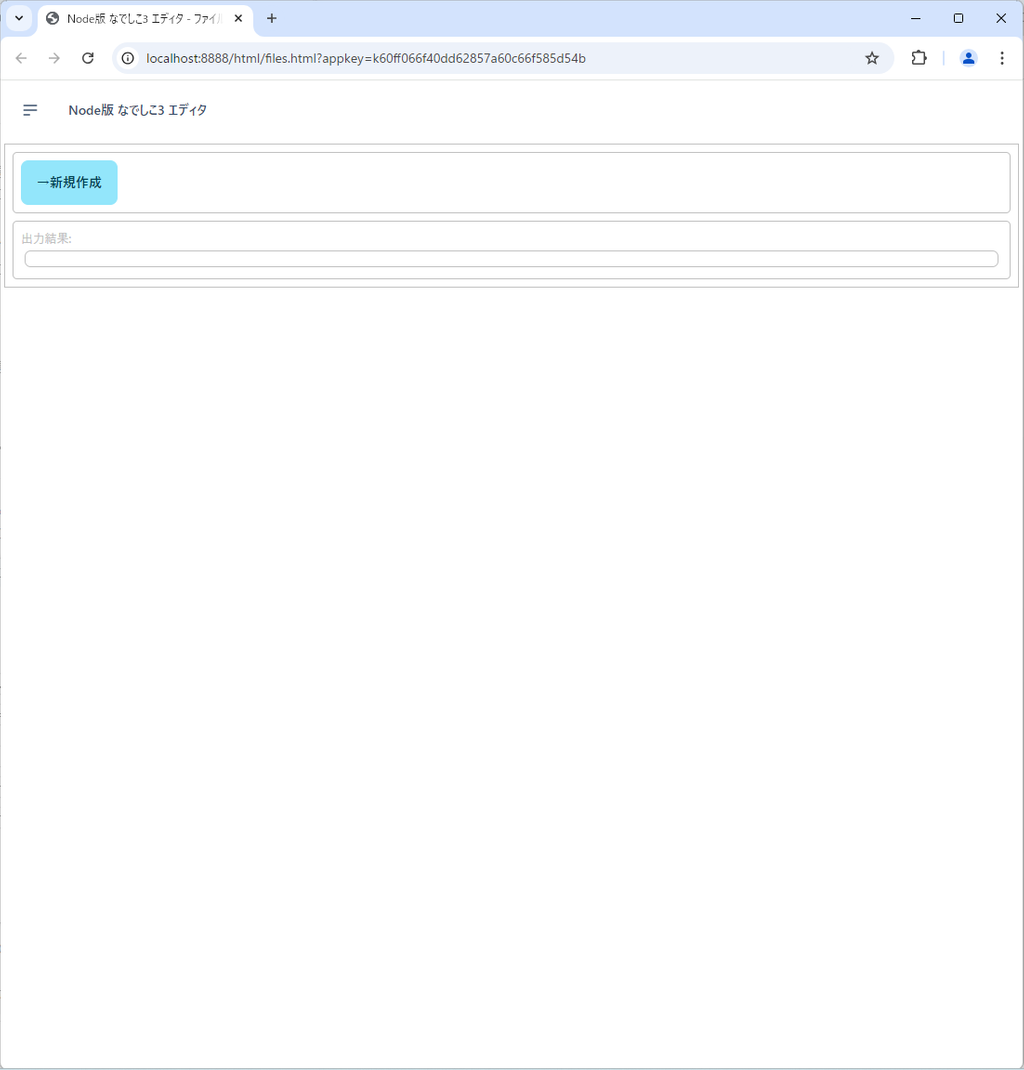
こんな感じのウィンドウが出てきます。
終了する場合は、このウィンドウを閉じるだけでなく、同時に起動したコマンドプロンプトも同時に終了する必要があります。
このウィンドウを閉じて、残っていたコマンドプロンプトもctrl+cなど押して終了してから閉じるのがよさそうです。
ちなみにこれを閉じずに新しいなでしこを実行することはできません。
エラーでサーバが立てられないときは大体これを閉じるのを忘れています。
これに気づくまで、ウィンドウだけ閉じて再び実行しようとしたら開かないというのをずっと繰り返していました。
さて、では早速プログラムをしてみましょう。
「新規作成」ボタンを押してください。
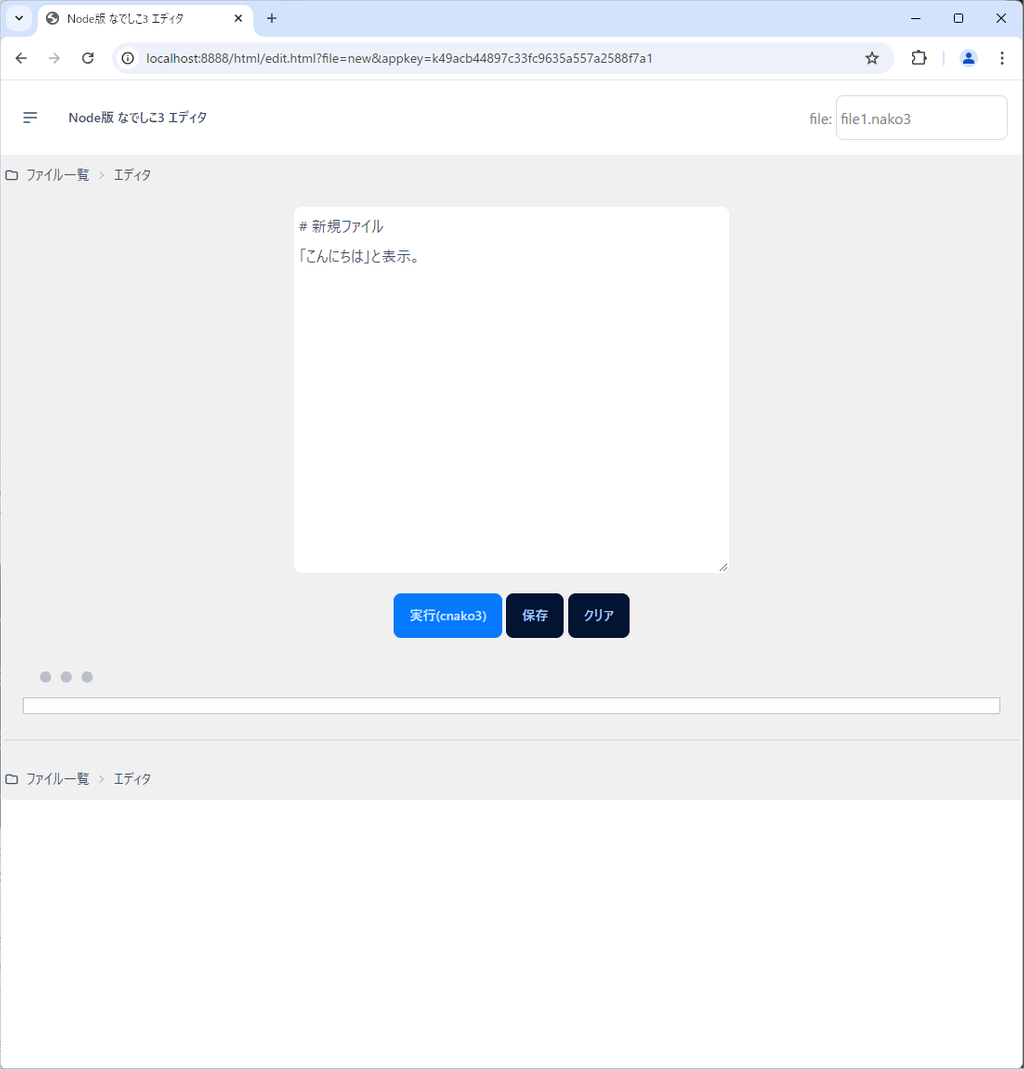
そうすると、上記のようになります。
試しに実行してみましょう。「実行(cnako3)」ボタンを押してください。
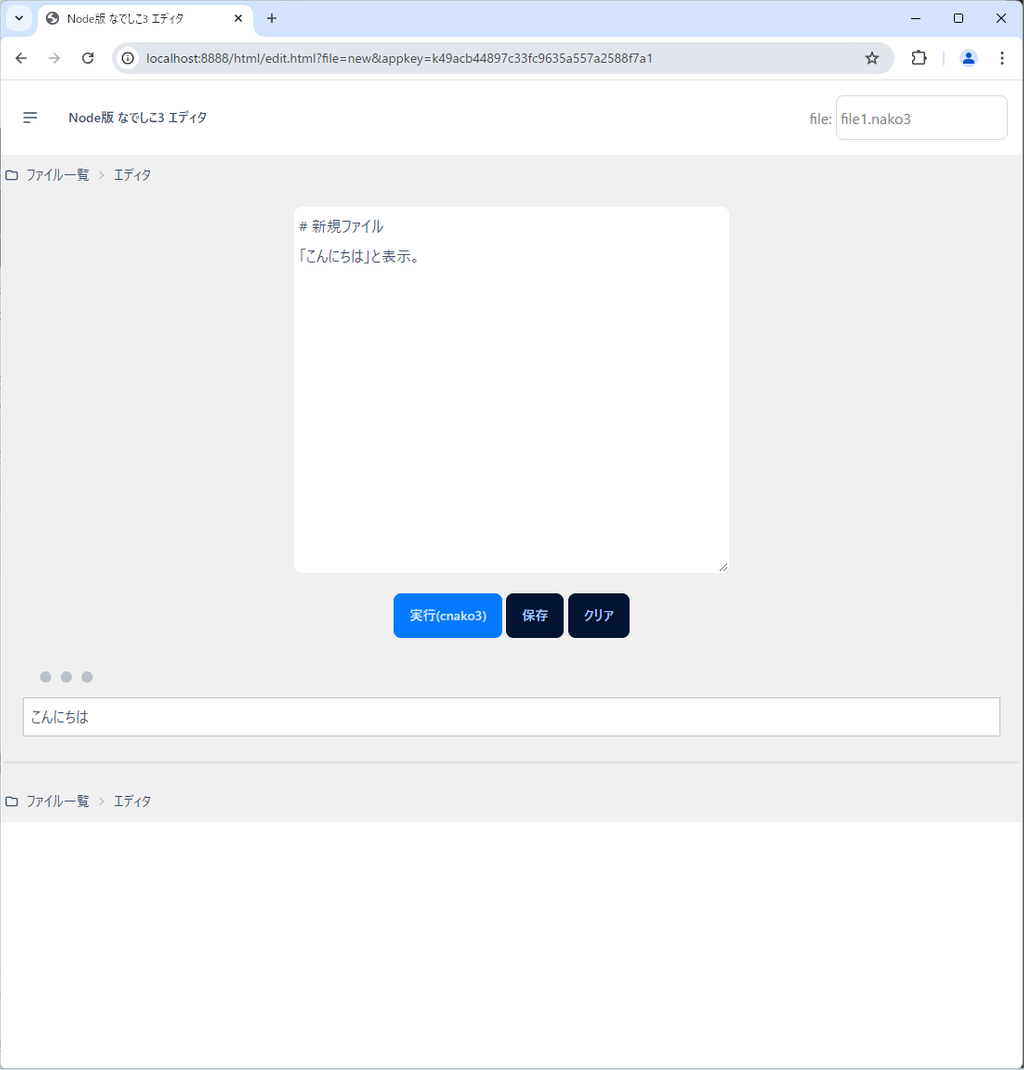
下のテキストボックスに「こんにちは」と表示されるはずです。
文法に関しては、日本語の自由度が高いため相当こちらも自由度が高いですが、まあ大体動きます。
では、機械学習をなでしこで行うにあたって、事前に必要な知識をご紹介します。
基本的な文法
https://www.nadesi.com/v3/doc/index.php?文法%2F基本&show
こちらが基本的な文法のドキュメントページです。
基本的に助詞で区切られると思っていただければよいかと思います。
コメント
https://www.nadesi.com/v3/doc/index.php?文法%2Fコメント&show
こちらがコメントのドキュメントページです。
今回は基本的に#を使います。
代入
https://www.nadesi.com/v3/doc/index.php?文法%2F代入文&show
こちらが代入文のドキュメントページです。
変数の定義や代入はある意味Pythonライクです。
例えば一番簡潔な方法はこんな感じでしょう。
リンゴ値段は200
リンゴ値段を表示こうすると、変数「リンゴ値段」が定義され、そこに200が代入されます。
二つ目の文で変数「リンゴ値段」の値が出力されるので、これを実行すると「200」が出力されます。
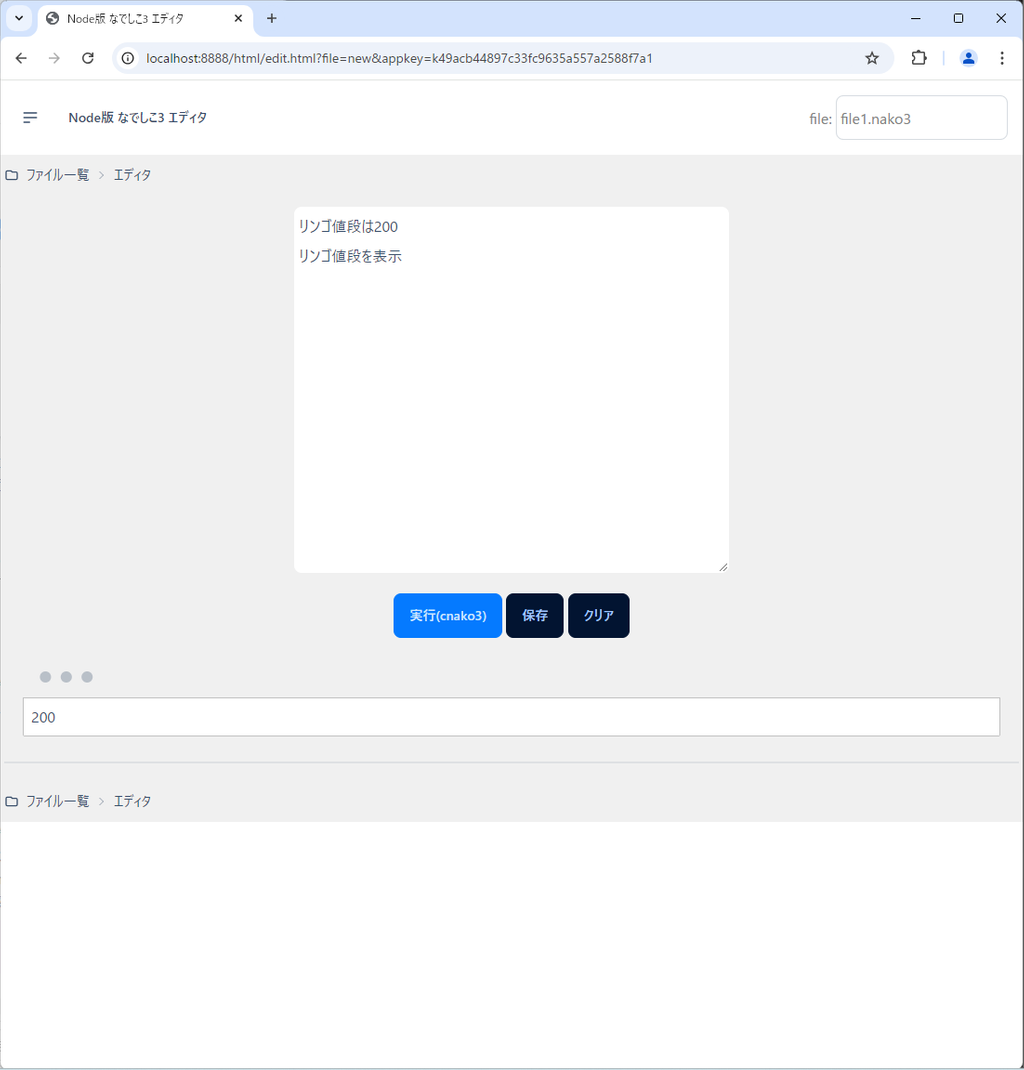
はい、ごくごく自然ですね。
特殊な変数「それ」
https://www.nadesi.com/v3/doc/index.php?文法%2Fそれ&show
こちらが「それ」のドキュメントページです。
「それ」はある意味ではなでしこらしい文法と言えます。
日本語は割と目的語や主語を省略しがちですが、このなでしこで省略を行うと、その対象はすべて「それ」になります。
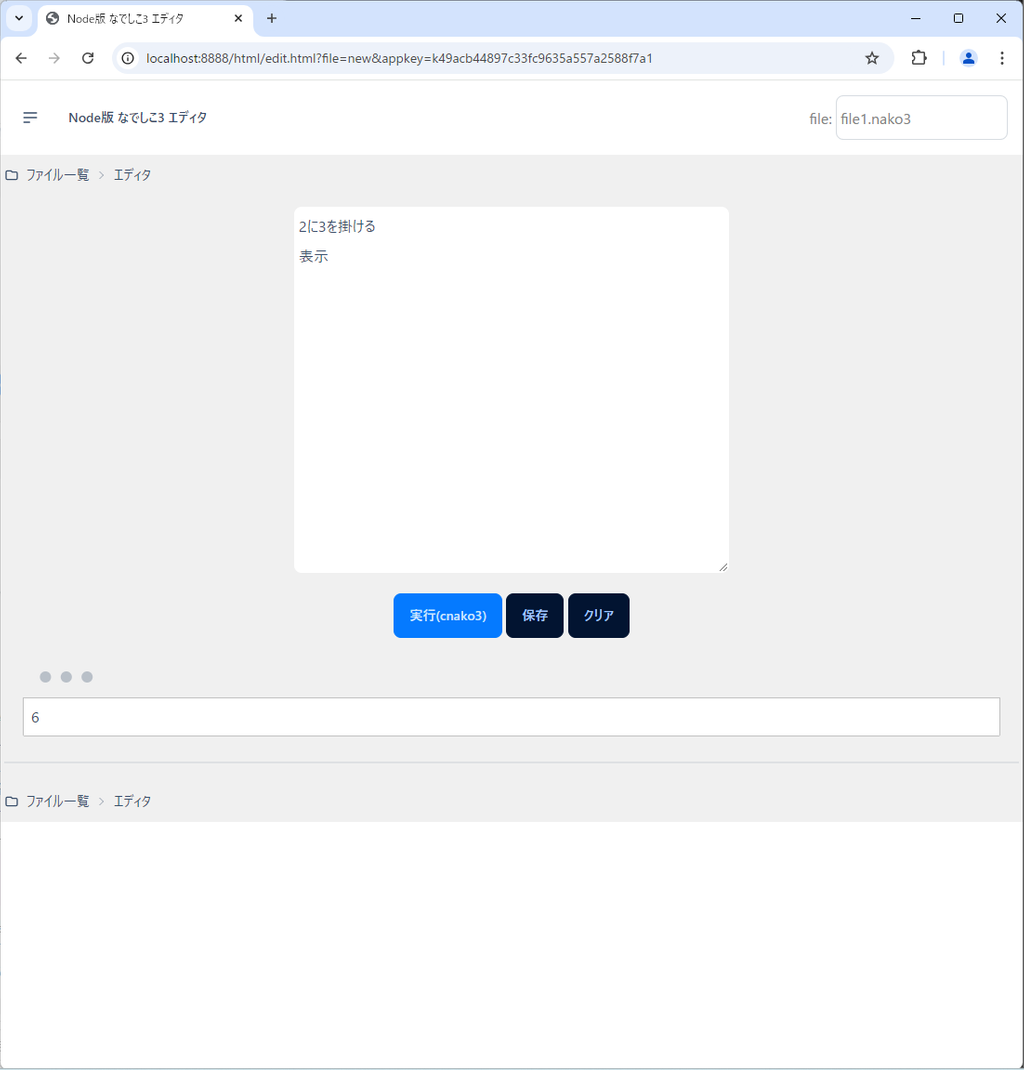
例えば、次のようなコードが考えられるでしょう。
2に3を掛ける
表示例えばこのコードにおいては、最初に2に3を掛けています。
これは代入する対象が指定されていないので、「それ」に代入されます。
そして、次の「表示」においても、対象が示されていないので、「それ」が表示されます。
結果的に、これを実行すると「6」が出力されます。
連文
https://www.nadesi.com/v3/doc/index.php?文法%2F連文&show
これが連文のドキュメントページです。
日本語もそうですが、「~して~する」のように、複数の動作を連ねて記述する書き方があります。
連文はそれを実現するための仕組みです。
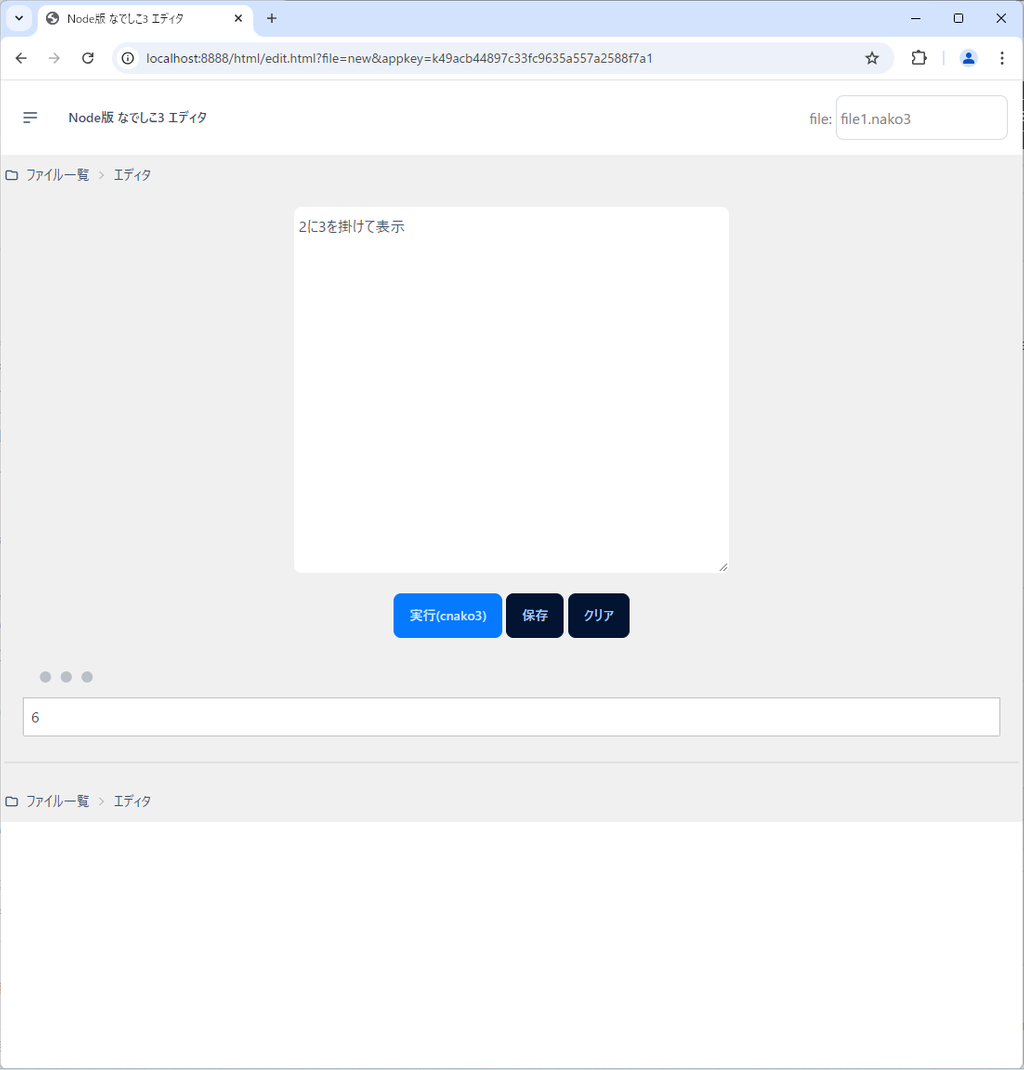
例えば、次のようなコードが考えられるでしょう。
2に3を掛けて表示もちろん出力は先ほどと同様6です。
さて、これで一通り今回のプログラムでやりたいことができます。
次は、いよいよ機械学習をしていきます。
あと、このnadesiko3-mlまわりのドキュメントページは次のリンクにあります。
https://www.nadesi.com/v3/doc/index.php?nadesiko3-ml&show
機械学習をする
では、いよいよ機械学習をしていきます。
ベースとしては次のページに則っています。
https://nadesi.com/doc3/index.php?機械学習
ただし、変数はある程度詳しく書いていきます。
このコードを詳しく書いてみると、実は機械学習のことがより詳しくなれる気がするのはまた後で。
先述のリンクでは、Irisデータを用いたアヤメの分類問題を解いています。
ここでもそれを使ってみましょう。
データを読み込む
機械学習たるもの、まずはデータがないと始まりません。
なので、データを読み込みましょう。
「アヤメデータ取得」という関数を用いて読み込むことができます。
変数「全体」に代入していきましょう。
!『nadesiko3-ml』を取り込む
# データの読み込み
全体はアヤメデータ取得
全体を表示最初の!『nadesiko3-ml』を取り込むについてですが、これはPythonにおけるimport文と思っていただければよいと思います。
拡張プラグインを使う際のおまじないと言ったところですね。
そしてその次に、データを読み込んでいます。
変数「全体」に関数「アヤメデータ取得」の結果を代入し、変数「全体」の値を表示しています。
これの結果は次のようになります。
[object Object]
……まあそんなもんです。
https://www.nadesi.com/v3/doc/index.php?nadesiko3-ml%2Fアヤメデータ取得&show
ここの通りなわけですが、jsonで返ってくるんですね。
なので、
https://www.nadesi.com/v3/doc/index.php?plugin_system%2FJSONエンコード&show
こちらの関数を使い、jsonエンコードして表示しましょう。
つまり、次のようなコードです。
!『nadesiko3-ml』を取り込む
# データの読み込み
全体はアヤメデータ取得
全体をJSONエンコードして表示これを実行すると、次のようになります。
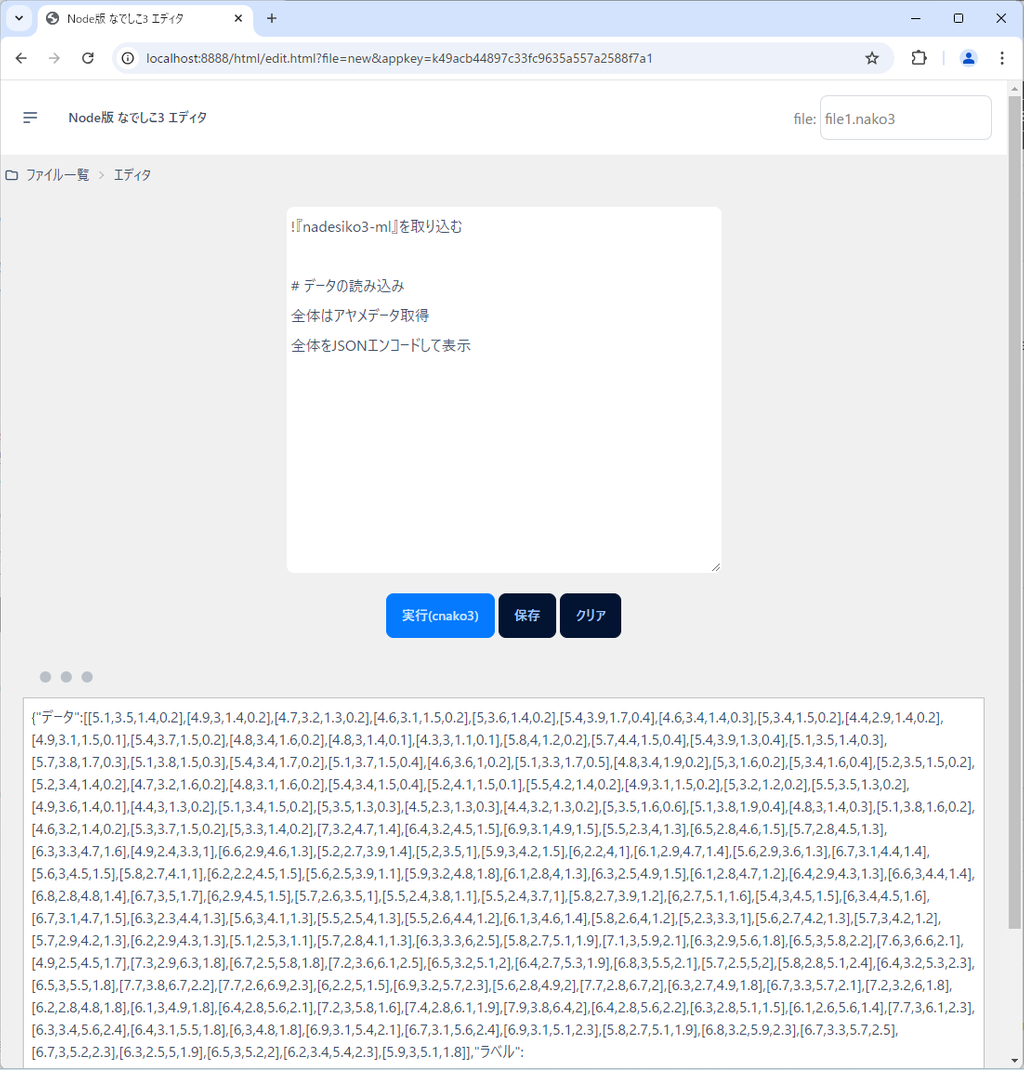
何やらカオスなことになっていますが、まあ間違ってないだろうと思うのでOKです。
データを分割する
機械学習においては、検証用データはさておき、学習用データとテスト用データは少なくとも必要です。
ただこのデータはそういった形に分かれているわけではないので、ここで分割する必要がありますね。
そういった場合において、なでしこは次のような関数を用意してくれています。
https://www.nadesi.com/v3/doc/index.php?nadesiko3-ml%2Fデータランダム分割&show
その名も、「データランダム分割」です。
データとラベルを渡して、どれくらいの割合を学習用データにするかを指定するだけで、ランダムに分割してくれるという優れもの関数です。
これを使いましょう。次のようにコードを変更します。
!『nadesiko3-ml』を取り込む
# データの読み込み
全体はアヤメデータ取得
# データの分割
全体データは全体['データ']
全体ラベルは全体['ラベル']
分割は全体データと全体ラベルを0.8でデータランダム分割
分割をJSONエンコードして表示言い忘れていましたが、jsonオブジェクトから値を取得するには、上記のように['keyの名前']で取得できます。
まあ一般的なjsonと同じです。
これを実行すると、次のようになります。
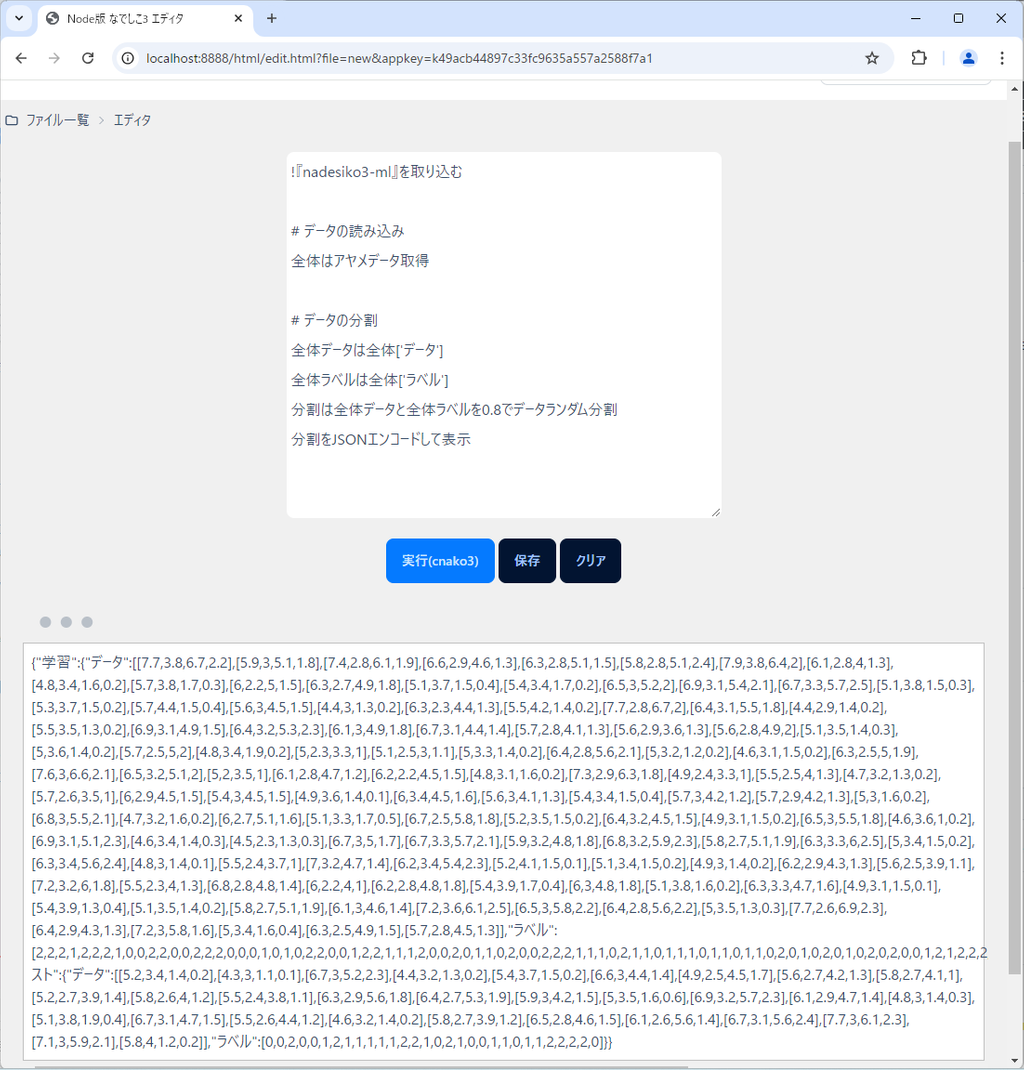
カオスなことになっていますが、まあ間違ってなさそうなのでOKです。
これ以降は、「データランダム分割」関数のため結果が毎回異なりますが、異常ありません。
データを分かりやすくまとめる
次に、データを分かりやすくまとめておきましょう。
僕は積極的に名前を付けていきたい人種なんです。
なので、次のようにコードを変更してください。
!『nadesiko3-ml』を取り込む
# データの読み込み
全体はアヤメデータ取得
# データの分割
全体データは全体['データ']
全体ラベルは全体['ラベル']
分割は全体データと全体ラベルを0.8でデータランダム分割
# データを分かりやすくまとめる
学習用データは分割['学習']['データ']
学習用ラベルは分割['学習']['ラベル']
テスト用データは分割['テスト']['データ']
テスト用ラベルは分割['テスト']['ラベル']
学習用データを表示
学習用ラベルを表示
テスト用データを表示
テスト用ラベルを表示ずいぶん見通しが良い気がしませんか?
実行すると次のようになります。
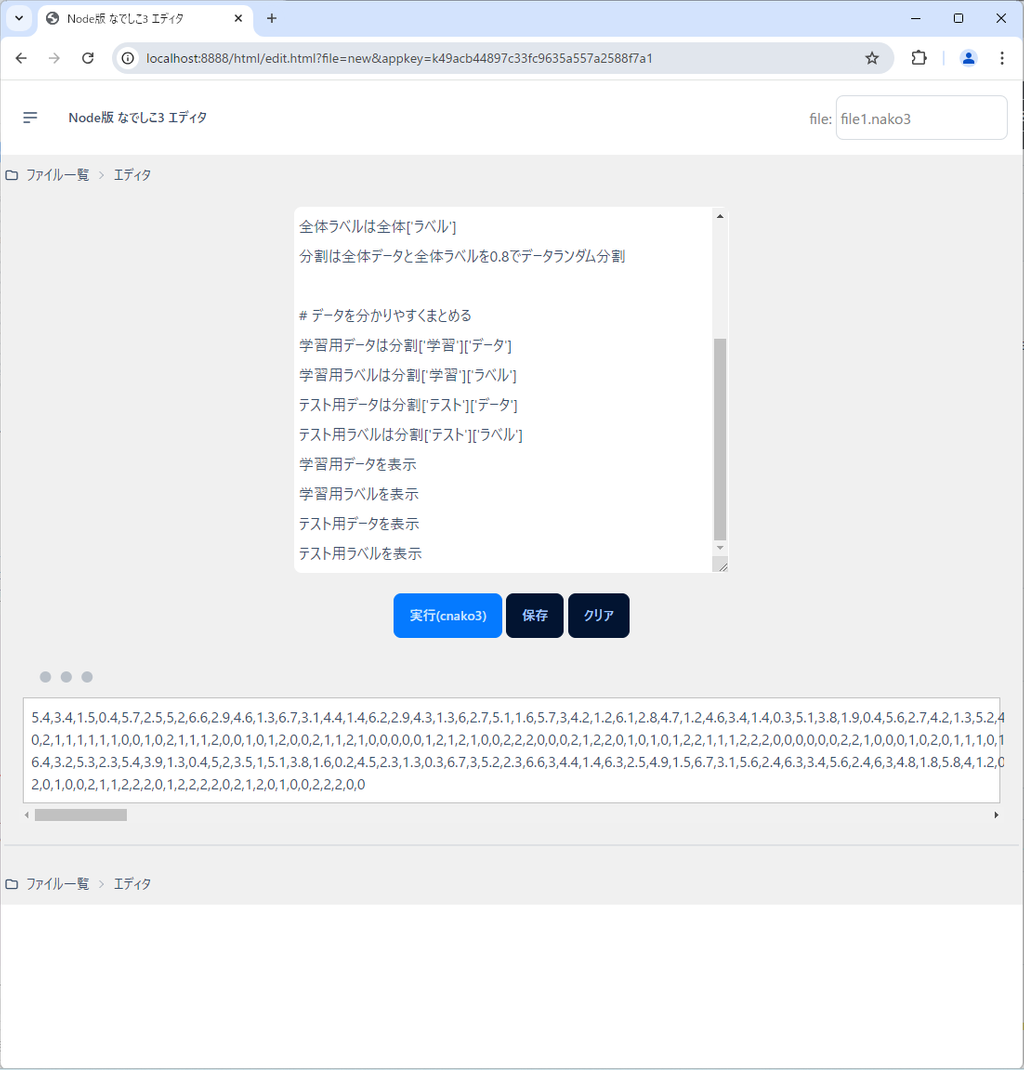
モデルを定義する
次にモデルを定義しましょう。
ここでは、SVM(サポートベクターマシン)を使用します。
https://qiita.com/c60evaporator/items/8864f7c1384a3c6e9bd9
こちらのページが分かりやすいかと思いますが、「そんなアルゴリズムもあるんだ」くらいに思ってもらえればOKです。
なでしこでSVMのモデルを定義するには、SVM開関数を使用します。
https://www.nadesi.com/v3/doc/index.php?nadesiko3-ml%2FSVM開&show
こちらがドキュメントページです。
基本の文法によれば送り仮名はかなり自由なので、こちらでは「SVM開く」として利用しています。
では、コードを次のように変更してください。
!『nadesiko3-ml』を取り込む
# データの読み込み
全体はアヤメデータ取得
# データの分割
全体データは全体['データ']
全体ラベルは全体['ラベル']
分割は全体データと全体ラベルを0.8でデータランダム分割
# データを分かりやすくまとめる
学習用データは分割['学習']['データ']
学習用ラベルは分割['学習']['ラベル']
テスト用データは分割['テスト']['データ']
テスト用ラベルは分割['テスト']['ラベル']
# モデルを定義する
{}でSVM開く
JSONエンコードして表示{}でSVM開くの{}は、SVMのオプションを指定できます。
先述のドキュメントでは指定されていたように見えましたが、デフォルトの値をそのまま入力していただけっぽかったので、ここでは省略しました。省略してもうまく動きます。
実行結果は次のようになります。
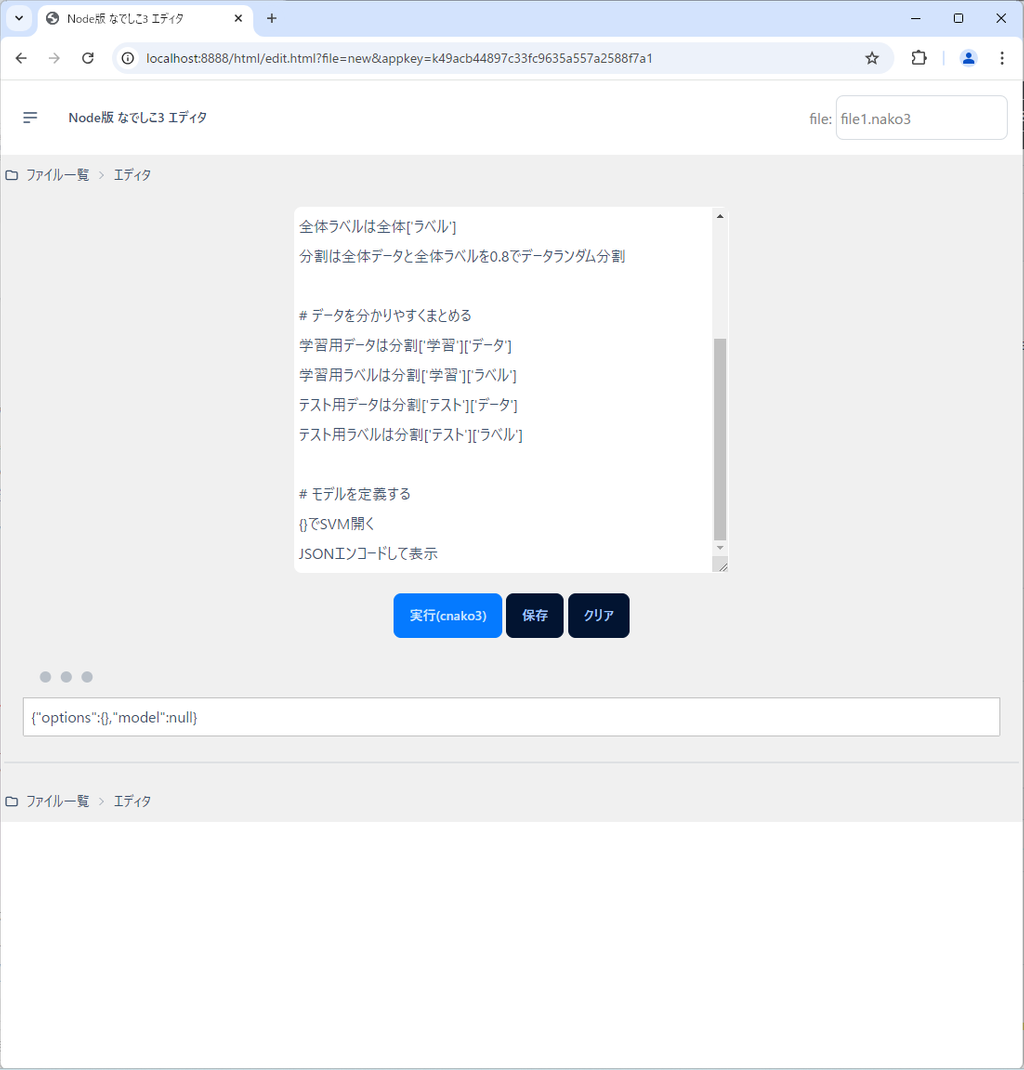
ここでは、関数「SVM開く」の出力を代入する先が明示されていないので、「それ」に代入されているはずです。
そのため、対象が明示されていない連文「JSONエンコードして表示」についても、「それ」の値がJSONエンコードされて表示されたもののはずです。
optionsが空でmodelがnullですね。まあ致し方ないと思います。
モデルを学習する
では、学習用データと学習用ラベルを用いてモデルを学習しましょう。
モデルの学習には、関数「学習」を使用できます。
https://www.nadesi.com/v3/doc/index.php?nadesiko3-ml%2F学習&show
こちらがドキュメントページです。
データとラベルを与えると学習してくれます。なので、次のようにコードを変更できます。
!『nadesiko3-ml』を取り込む
# データの読み込み
全体はアヤメデータ取得
# データの分割
全体データは全体['データ']
全体ラベルは全体['ラベル']
分割は全体データと全体ラベルを0.8でデータランダム分割
# データを分かりやすくまとめる
学習用データは分割['学習']['データ']
学習用ラベルは分割['学習']['ラベル']
テスト用データは分割['テスト']['データ']
テスト用ラベルは分割['テスト']['ラベル']
# モデルを定義する
{}でSVM開く
# モデルを学習する
学習用データと学習用ラベルで学習
JSONエンコードして表示関数「学習」の対象は明示されていないので、「それ」に代入されているSVMが学習されるわけですが、これ学習対象ってどうやって明示すればよいのか、未だに分かっておりません。
さて、これの実行結果は次のようになります。
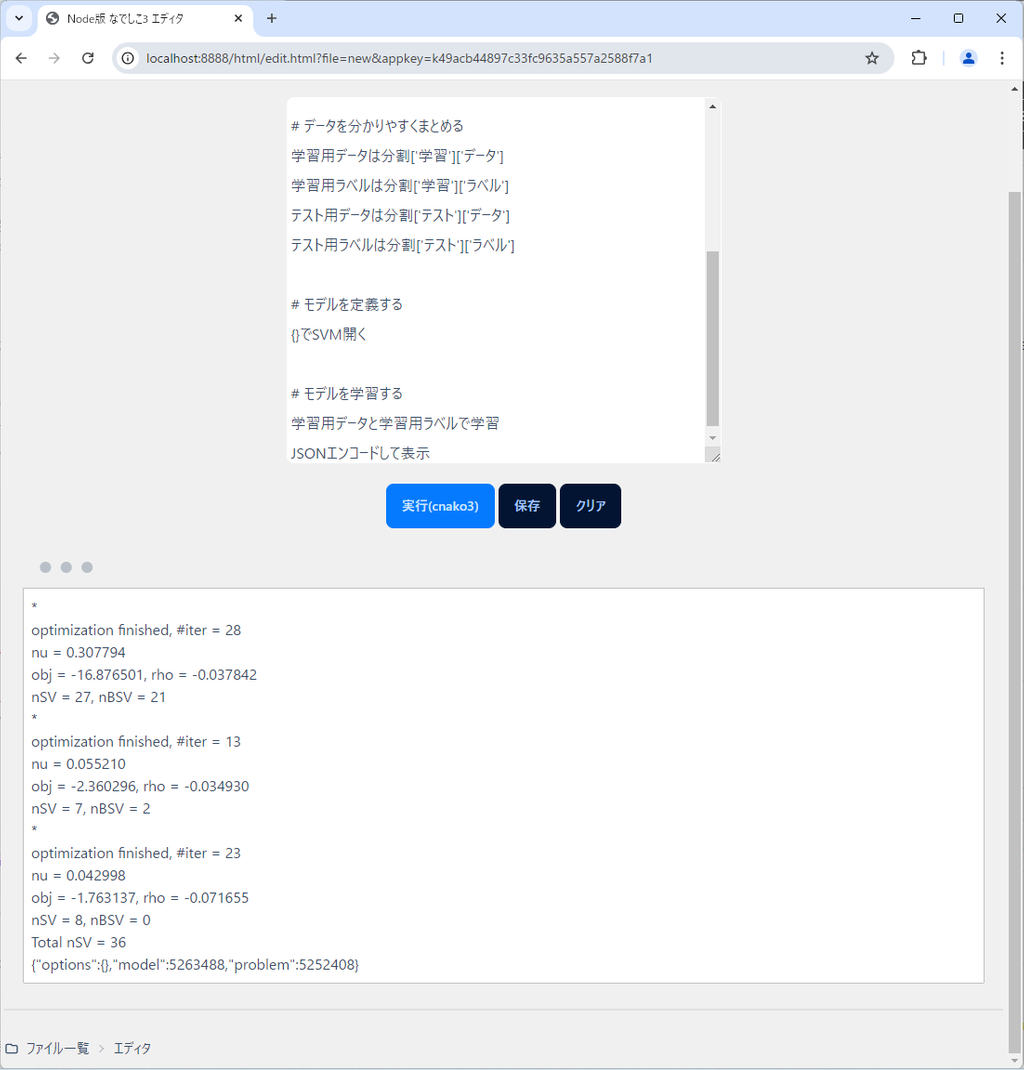
学習結果と学習後のモデルが出力できました。
これがどれくらい精度がいいのか、次のところで確かめましょう。
モデルを用いて予測する
では、モデルを用いて、与えられたデータからラベルを予測してもらいましょう。
予測をするには、関数「予測」を使います。
https://www.nadesi.com/v3/doc/index.php?nadesiko3-ml%2F予測&show
こちらがドキュメントページです。
次のようにコードを変更してください。
!『nadesiko3-ml』を取り込む
# データの読み込み
全体はアヤメデータ取得
# データの分割
全体データは全体['データ']
全体ラベルは全体['ラベル']
分割は全体データと全体ラベルを0.8でデータランダム分割
# データを分かりやすくまとめる
学習用データは分割['学習']['データ']
学習用ラベルは分割['学習']['ラベル']
テスト用データは分割['テスト']['データ']
テスト用ラベルは分割['テスト']['ラベル']
# モデルを定義する
{}でSVM開く
# モデルを学習する
学習用データと学習用ラベルで学習
# モデルを用いて予測する
予測値はテスト用データで予測
予測値を表示
テスト用ラベルを表示変数「予測値」に予測された結果が代入されています。
変数「予測値」と変数「テスト用ラベル」を比較することで、このモデルがどのくらい精度がいいのか確かめることができますね。
これを実行すると次のようになります。
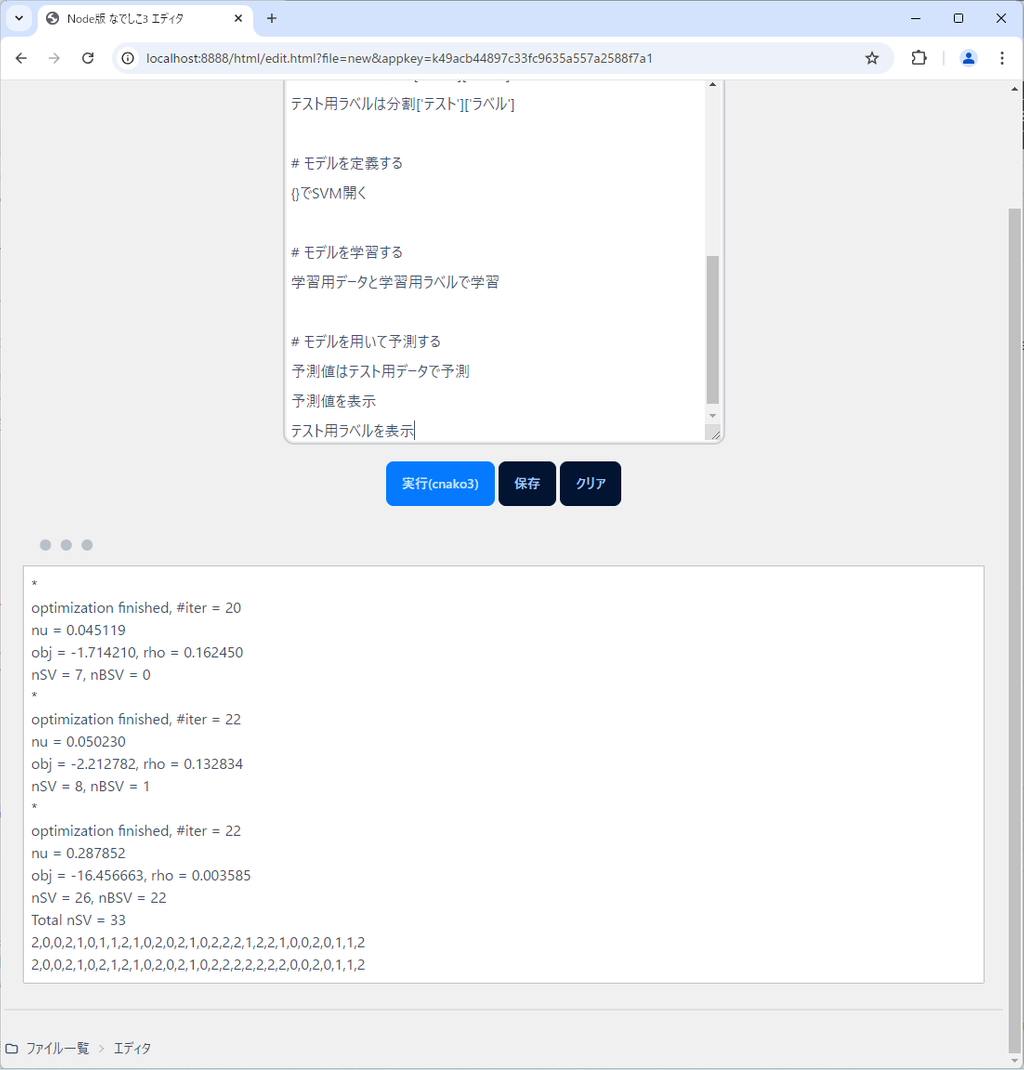
かなりよさそうです。
一部テスト用ラベルで「2」となっているところが「1」であるくらいでしょうか。
このように比較してもよいですが、テスト用データが膨大になったら、それこそ一つ一つ確認するのは相当困難です。
なので、正解率を求めてみましょう。
正解率を求める
では、正解率を求めてみましょう。
正解率を計算するには、関数「正解率計算」を用います。
https://www.nadesi.com/v3/doc/index.php?nadesiko3-ml%2F正解率計算&show
こちらがドキュメントページです。
では、次のように変更してください。
!『nadesiko3-ml』を取り込む
# データの読み込み
全体はアヤメデータ取得
# データの分割
全体データは全体['データ']
全体ラベルは全体['ラベル']
分割は全体データと全体ラベルを0.8でデータランダム分割
# データを分かりやすくまとめる
学習用データは分割['学習']['データ']
学習用ラベルは分割['学習']['ラベル']
テスト用データは分割['テスト']['データ']
テスト用ラベルは分割['テスト']['ラベル']
# モデルを定義する
{}でSVM開く
# モデルを学習する
学習用データと学習用ラベルで学習
# モデルを用いて予測する
予測値はテスト用データで予測
# 正解率を求める
正解率はテスト用ラベルと予測値の正解率計算
正解率を表示する良さげですね。
では、これを実行してみましょう。
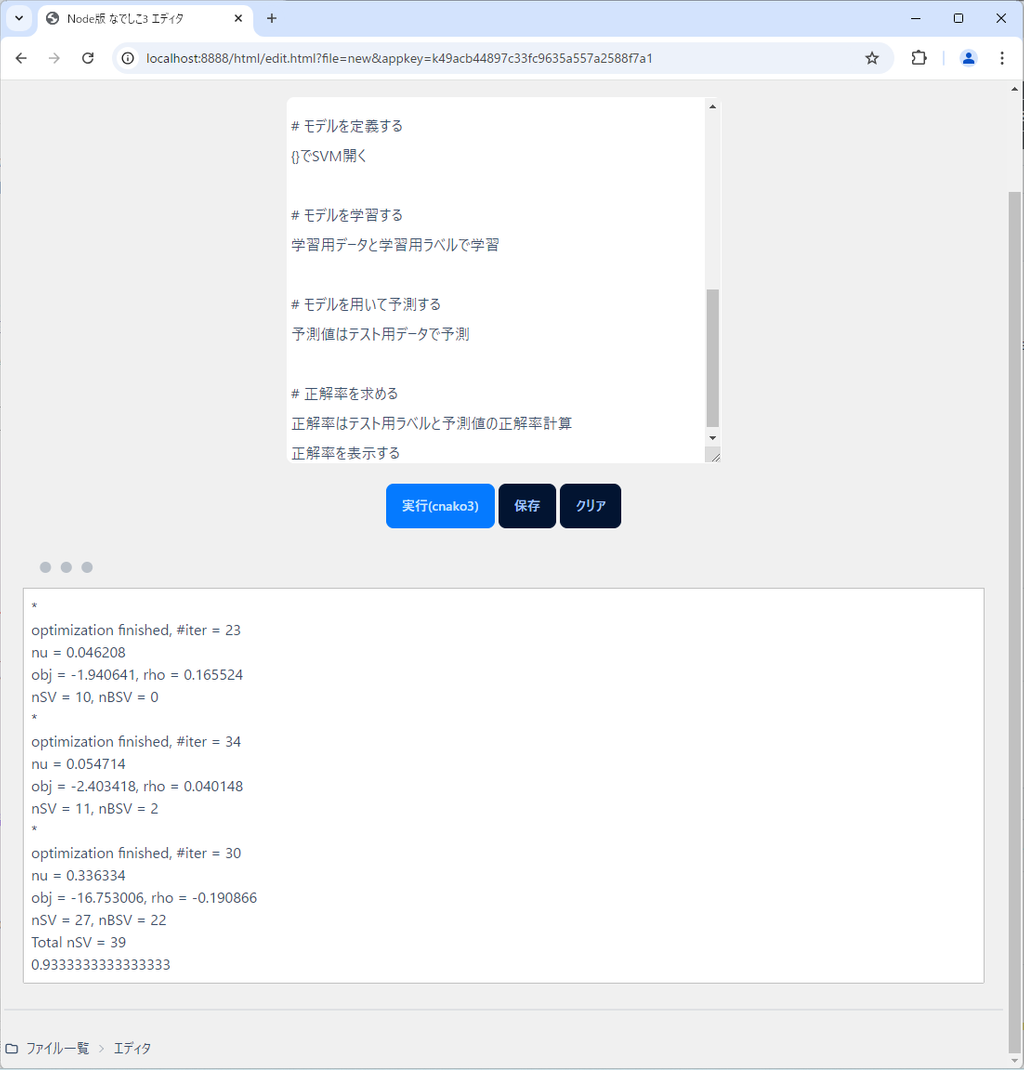
結果はこのようになりました。
正解率がおよそ93%ですから、まあまあ精度はよさそうです。
まとめ
最終的なコードは次のようになりました。
!『nadesiko3-ml』を取り込む
# データの読み込み
全体はアヤメデータ取得
# データの分割
全体データは全体['データ']
全体ラベルは全体['ラベル']
分割は全体データと全体ラベルを0.8でデータランダム分割
# データを分かりやすくまとめる
学習用データは分割['学習']['データ']
学習用ラベルは分割['学習']['ラベル']
テスト用データは分割['テスト']['データ']
テスト用ラベルは分割['テスト']['ラベル']
# モデルを定義する
{}でSVM開く
# モデルを学習する
学習用データと学習用ラベルで学習
# モデルを用いて予測する
予測値はテスト用データで予測
# 正解率を求める
正解率はテスト用ラベルと予測値の正解率計算
正解率を表示するこのコードを見てみてください。すごくないですか?
なぜなら、機械学習でやるべきことが、日本語で全て明示されているうえに、これがコードとしてそのまま動くからです。
しかも、日本語が分かれば改造も容易です。
変数「全体」に、データとラベルを持つjsonを代入して、関数「SVM開く」の部分を好みのモデルを開くコードに差し替えるだけだからです。
まあ現状はSVMかランダムフォレストしか確認していませんが、それでも十分機械学習としてやりたいことができているような気がします。
plugin_nodeというのを使えば、PC上のファイルを読み込めますし、csvを扱うためのプラグインも存在しています。
自分のオリジナルのデータについて機械学習を行うこともできそうです。
おわりに
本日は日本語プログラミング言語「なでしこ」を用いて、機械学習をしてきました。
いつか触りたいと思っていたので、ふと思い立って今回やってみました。
最後までお読みいただき、ありがとうございました。