当記事は2022年7月17日に、部内向けに書いたブログを外部公開向けに、また現在の時勢に合わせて改めて書き直したものになります。
そのため画像や情報が一部古い場合、また不勉強な部分もありますがなるべく当時のものをそのまま載せています。あらかじめご了承ください。
GitHub に示しているプログラムについては現在の環境(Windows 11 Home & Visual Studio 2026)で動くことを確認しています。
はじめに
こんにちは。koukawa_pp です。
当サークルはデジタル創作同好会ということで、デジタルに関するあらゆる創作を包含する存在を目指しており、サークル内では「機械学習講習会」というものがかなり前に開催されていたようです。
ここからも分かるように、機械学習は今や「誰もが一度はやってみたいもの」となりました。
しかし生成AIがかなり広まった今となっても、機械学習というものそれ自体はかなり難しそう、という印象はまだぬぐえないですし、そのためにがっつりコーディングする必要があるのではないかと思われる方は多いと思います。
しかし例えばPythonではたくさんのライブラリが登場しており、かなりコーディング量を減らして機械学習を実現できるようになったのはもちろん、先述のとおり生成AIを使えば基本的な機械学習コードはいとも簡単に作ることができるようになりました。
その流れもあり、「機械学習と言えばPython」というのは、もはや常套句のように思えます。
ただここではあえて、C#を使って機械学習をしてみたいという方向を取ります。
「C#じゃめちゃくちゃコード書かないといけないんじゃないか」と思われるかもしれません。
ところがどっこい、C#のNuGetパッケージでも、機械学習を行えるものがオープンソースでMicrosoftから出されています。
その名前は、「ML.NET」というものです。
僕もいまいちよく分かっていないので勉強中ですが、とりあえずこの「ML.NET」というものを用いれば、様々なものの機械学習を行うことができるという触れ込みです。
そこで今回は、「夏目漱石」を機械学習してみようということです。
やることはざっくり言えば、
ある文が渡されたとき、それはどの作品に含まれる文か?
を当てるといったものです。
先行研究を探せば、多分たくさん出てくると思いますし、例えば「○○が書いたような文章」を生成するといったテーマで研究されている方もたくさんいらっしゃると思いますが、今回はごく簡単なものということでやってみます。
そういえば機械生成ではなく作家さんが書かれた文章ですが、「もし文豪たちが カップ焼きそばの作り方を書いたら」という本がかなり面白かったのを記憶しています。また読みたいなと思っています。
また、今回は以下の作品を用います。
- こころ
- 吾輩は猫である
- 三四郎
- 私の個人主義
- 草枕
- 坊っちゃん
選択した作品は適当です。
これらの文章を二つに分け、一方は学習、もう一方はテストに使います。
なお、今回使用したファイルはこちらのGitHubレポジトリで公開しています。
プログラムについてはMITライセンスで再利用いただけます。作品データについては青空文庫さまの利用規約に則ってご利用ください。
環境
- Windows 10 Home 64bit
- Visual Studio 2022 Community
- Visual Studio Code
- (メモ帳)
データを準備する
まず、今回用いるデータの準備を行います。
この文章に関しては、青空文庫さまのデータを使います。
ファイルの取り扱い方についてはこちらを参考にしています。
夏目漱石作品はすでに著作権が切れていますので、こちらで機械学習しやすいようにデータを編集できます。
ファイルをダウンロードする
こちらに夏目漱石作品の一覧があります。
これらの中から、
- こころ
- 吾輩は猫である
- 三四郎
- 私の個人主義
- 草枕
- 坊っちゃん
についてページを開き、それぞれzipファイルをダウンロードします。
もちろん、ダウンロードしたファイルは解凍してください。
ちなみに、ダウンロードしたファイルは以上のような感じです。
なお、ファイル末尾にある「記載事項」については、
青空文庫さま側は削除されないことを希望されていますが、
ここでは機械学習を行う都合上あとで削除します。
しかし、原本および変更の作業履歴を配布しますので、
そちらをご覧の上、これをまた再配布される場合は
このことを配布先にも提示いただきますようお願いします。
データを編集する
もっと簡単な編集方法があるかもしれませんが、僕は以下の方法で編集しました。
以下では「こころ」について示しますが、他のファイルも同様の編集を行ってください。
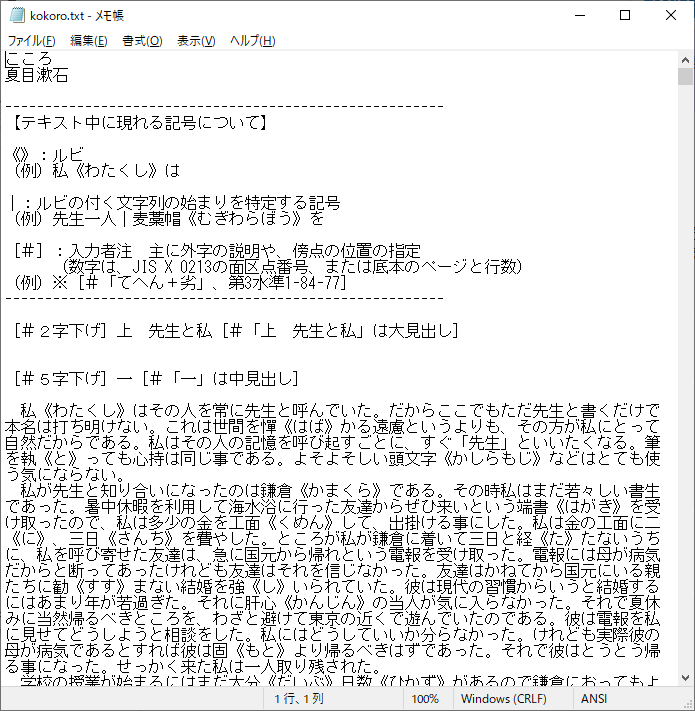
1. kokoro.txtをコピーし、kokoro_edit.txtを作成する
原本は残しておくつもりでいるので、一旦「kokoro.txt」を複製し、同じフォルダにコピーしてください。
また、複製したファイルの名称を「kokoro_edit.txt」に編集します。
2. kokoro_edit.txtをVSCodeで開く
詳細な文字の置換は、VSCodeでやるのが便利だと思っています。
開くと、以下のようになると思います。
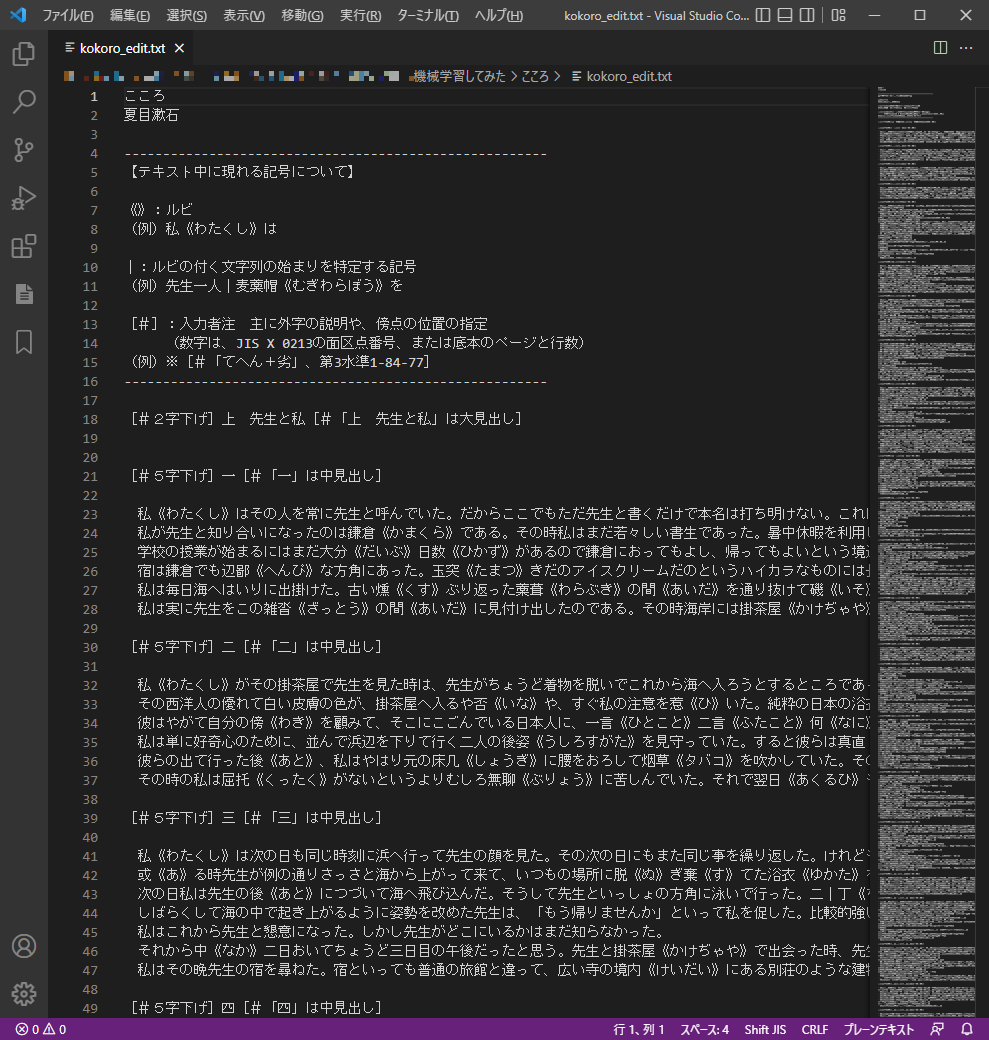
3. ルビを削除する
今回の学習においては、ルビは削除します。
ここで、VSCodeの強力な「置換」機能を使います。
「正規表現を使用する」をチェックして、以下のように「検索」ボックスに入力してください。

この正規表現は、
まず《に合致する文字を捜し出す
その後、》でない文字を任意個並べた部分を探し、
最後に》とついている文字列
を探しています。
本来なら《.*》と入力したいところですが、
これだと
《ひとこと》二言《ふたこと》
と選択されてしまうため、不都合です。
ここで、》を除外することにより、
《ひとこと》二言《ふたこと》
と選択されるようになります。
こう入力したら、「置換」のところを空欄にして、「すべて置換」を選択してください。
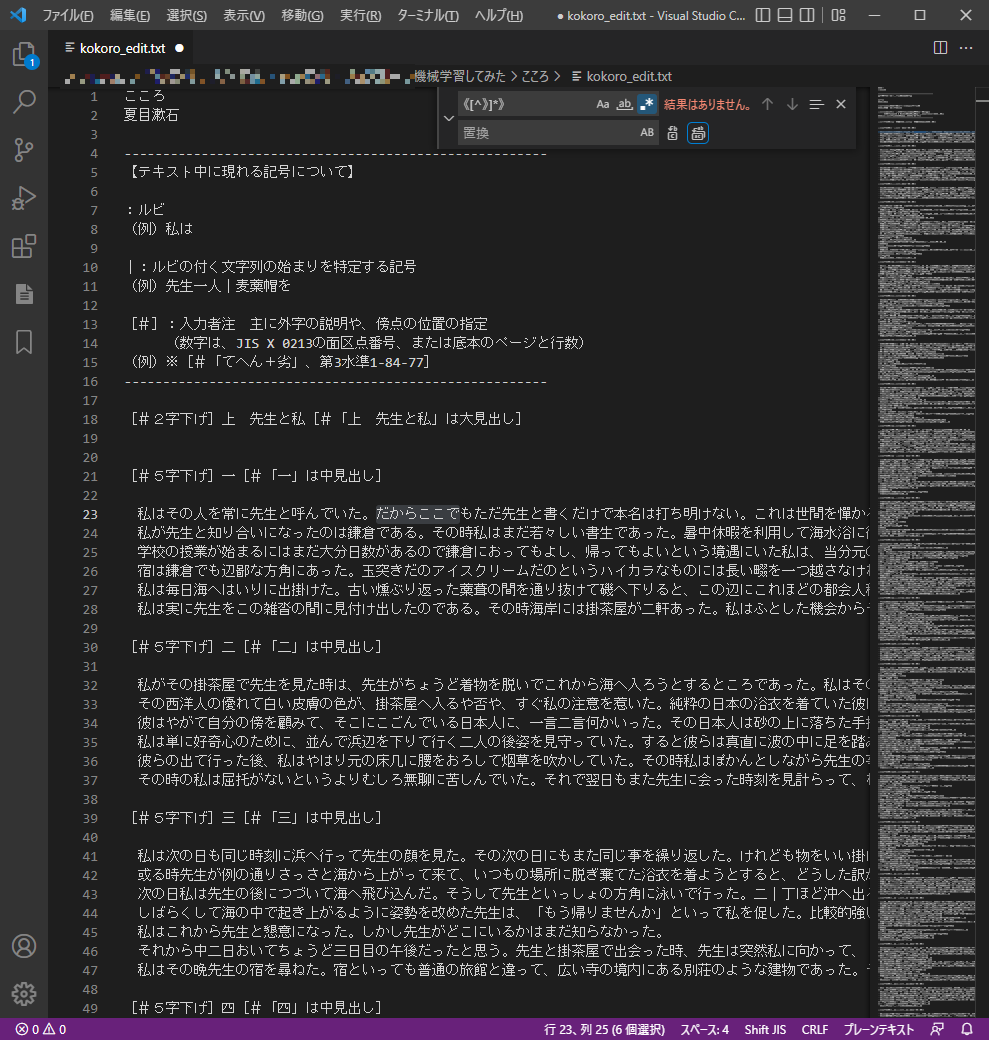
上部「テキスト中に現れる記号について」のルビのところも消えていますが、
ここはあとで削除するので特に不都合はありません。
4. 「ルビの付く文字列の始まりを特定する記号」を削除する
こちらはそこまで難しくないです。
|を検索ボックスに入力し、「置換」のところを空欄にしてから、
「すべて置換」を押してください。
5. 「入力者注」を削除する
ここが実は一番大変です。
まず、以下のようなものを削除します。
[#5字下げ]一[#「一」は中見出し]
これだけ見ると分かりづらいですが、
この[#5字下げ]一[#「一」は中見出し]の上下には
一行ずつ空行が存在している状態です。
これらの空行も削除します。
まず、検索ボックスの中に\n[.*]\n\nと入力してください。
半角と全角を間違えないでください。
そうすると、以下のようにハイライトされるはずです。
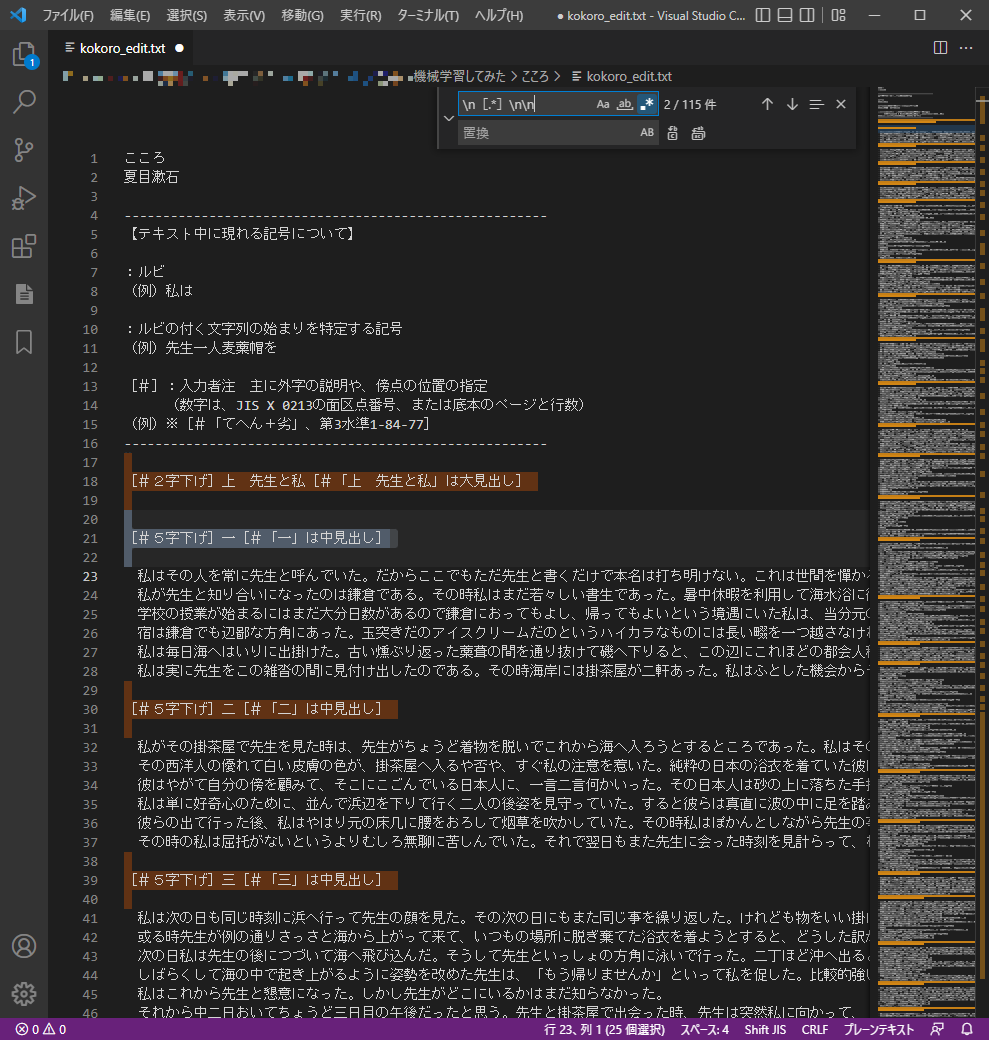
これでいったん「すべて置換」してください。
次に、検索ボックスの中に[[^]]*]と入力してください。
ブラケットは、左から全角、半角、全角、半角、全角です。
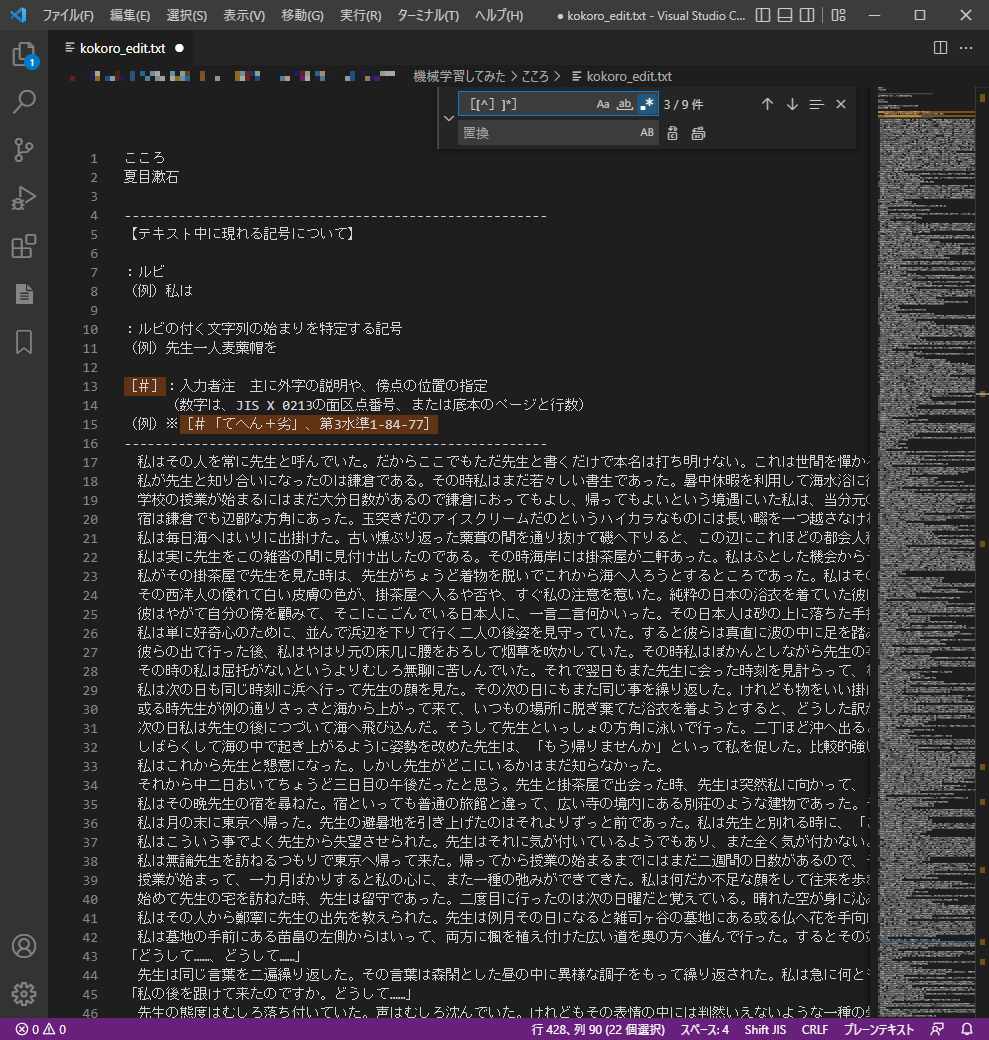
よさげですね。
これもまた「置換」のところを空欄にしてから、「すべて置換」を押してください。
6. 最初と最後を削除する
最初と最後の脚注を削除してください。
ここまで来たら、「kokoro_edit.txt」を保存してください。
また、VSCodeを閉じて大丈夫です。
7. メモ帳で「kokoro_edit.txt」を開き、文字コードを変更して保存する
そもそも初めからだと思うのですが、ファイルをダウンロードした時点ですでに文字コードが「ANSI」になっています。
これはこの後プログラムで扱うときに非常に面倒なので、メモ帳で「kokoro_edit.txt」を開いたのち、「名前を付けて保存」で文字コードを「UTF-8(BOM付き)」を選択して保存してください。
名称は僕は「kokoro_utf.txt」としました。
8. (私の個人主義のみ)一部削除
――大正三年十一月二十五日学習院輔仁会において述――
も削除してください。
データを(本格的に)作成する
ここまではデータの準備です。なので、ここからはデータを作成します。
やり方としては単純です。
- 各テキストのファイルを読み込む
- およそ10個に一つ程度の割合で、文章をテスト用データに登録し、それ以外は訓練用データに登録する
- 最後にそれらをファイルとして書き出す
これを実行してくれるコンソールプログラムを作成しましょう。
ただ繰り返しになりますが、このコードは2022年7月時点に書いたコードになります。
現在のコンソールアプリでは以下のような namespace や class, はては Main 関数の記述すらなく、トップレベルのステートメントが使用されるようになっています。
この形式のコードを記述する際には、「最上位レベルのステートメントを使用しない」チェックボックスをOnにすることによって行えます。
プロジェクト名は「MakeSosekiDatas」としました。
Program.csに、コードを以下の通り入力しました。
Program.csnamespace MakeSosekiData
{
internal class Program
{
static int seed = Environment.TickCount;
static readonly string _kokoroPath = Path.Combine(Environment.CurrentDirectory, "Data", "kokoro_utf.txt");
static readonly string _wagahaiPath = Path.Combine(Environment.CurrentDirectory, "Data", "wagahaiwa_nekodearu_utf.txt");
static readonly string _sanshiroPath = Path.Combine(Environment.CurrentDirectory, "Data", "sanshiro_utf.txt");
static readonly string _kozinPath = Path.Combine(Environment.CurrentDirectory, "Data", "watashino_kojinshugi_utf.txt");
static readonly string _kusaPath = Path.Combine(Environment.CurrentDirectory, "Data", "kusamakura_utf.txt");
static readonly string _bochanPath = Path.Combine(Environment.CurrentDirectory, "Data", "bocchan_utf.txt");
static readonly string _trainDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "traindata.csv");
static readonly string _testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "testdata.csv");
static readonly List<(string, int)> trainDatas = new();
static readonly List<(string, int)> testDatas = new();
static void Main(string[] args)
{
//こころのデータを作る
using FileStream kokoroStream = new(_kokoroPath, FileMode.Open, FileAccess.Read, FileShare.Read);
using StreamReader kokoroReader = new(kokoroStream);
ReaderToData(kokoroReader, 0);
//吾輩は猫であるのデータを作る
using FileStream wagahaiStream = new(_wagahaiPath, FileMode.Open, FileAccess.Read, FileShare.Read);
using StreamReader wagahaiReader = new(wagahaiStream);
ReaderToData(wagahaiReader, 1);
//三四郎のデータを作る
using FileStream sanshiroStream = new(_sanshiroPath, FileMode.Open, FileAccess.Read, FileShare.Read);
using StreamReader sanshiroReader = new(sanshiroStream);
ReaderToData(sanshiroReader, 2);
//私の個人主義のデータを作る
using FileStream kozinStream = new(_kozinPath, FileMode.Open, FileAccess.Read, FileShare.Read);
using StreamReader kozinReader = new(kozinStream);
ReaderToData(kozinReader, 3);
//草枕のデータを作る
using FileStream kusaStream = new(_kusaPath, FileMode.Open, FileAccess.Read, FileShare.Read);
using StreamReader kusaReader = new(kusaStream);
ReaderToData(kusaReader, 4);
//坊っちゃんのデータを作る
using FileStream bochanStream = new(_bochanPath, FileMode.Open, FileAccess.Read, FileShare.Read);
using StreamReader bochanReader = new(bochanStream);
ReaderToData(bochanReader, 5);
//trainDatasを保存する。
using FileStream trainStream = new(_trainDataPath, FileMode.Create, FileAccess.Write, FileShare.Read);
using StreamWriter trainWriter = new(trainStream, System.Text.Encoding.GetEncoding("utf-8"));
foreach (var item in trainDatas)
{
trainWriter.WriteLine(item.Item1 + "," + item.Item2.ToString());
}
//testDatasを保存する。
using FileStream testStream = new(_testDataPath, FileMode.Create, FileAccess.Write, FileShare.Read);
using StreamWriter testWriter = new(testStream, System.Text.Encoding.GetEncoding("utf-8"));
foreach (var item in testDatas)
{
testWriter.WriteLine(item.Item1 + "," + item.Item2.ToString());
}
}
static void ReaderToData(StreamReader streamReader, int sakuhinIndex)
{
while (!streamReader.EndOfStream)
{
string? str = streamReader.ReadLine();
if (str == null)
break;
if (str.Contains('。'))
{
string[] vs = str.Split('。');
for (int i = 0; i < vs.Length; i++)
{
if (vs[i] != "")
RegisterData(vs[i] + "。", sakuhinIndex);
}
}
else
RegisterData(str, sakuhinIndex);
}
}
static void RegisterData(string text, int sakuhinIndex)
{
if (text == "") return;
Random random = new(seed);
seed = random.Next();
if (text[..1] == " ")
{
if (random.Next(10) == 0)
testDatas.Add((text[1..], sakuhinIndex));
else
trainDatas.Add((text[1..], sakuhinIndex));
}
else
{
if (random.Next(10) == 0)
testDatas.Add((text, sakuhinIndex));
else
trainDatas.Add((text, sakuhinIndex));
}
}
}
}
コードはかなりごついですが、ほとんど繰り返しなのでやっていることは単純です。
Main()では最初の方で6つのテキストデータを読み込み、ReaderToData(StreamReader, int)でデータを作成しています。
その後、StreamWriterを用いて指定されたパスにデータを保存しています。
ReaderToData(StreamReader, int)では、テキストファイルの終わりまで文字列の読み込みを繰り返し、。で文章を分割して一つの文にし、それに作品のインデックスを付けることによりラベリングしています。
実際の登録はRegisterData(string, int)で行っています。
RegisterData(string, int)は、
- 10%の確率で、string + "," + intをテスト用データに追加し、
- 90%の確率で、string + "," + intを訓練用データに追加しています。
ちなみに段落明けのため、一字下げが行われているところでは、一字下げを戻すようにしています。
さて、このまま実行するとFileNotFoundExceptionを吐き出して止まるので、ファイルをきちんと登録していきましょう。
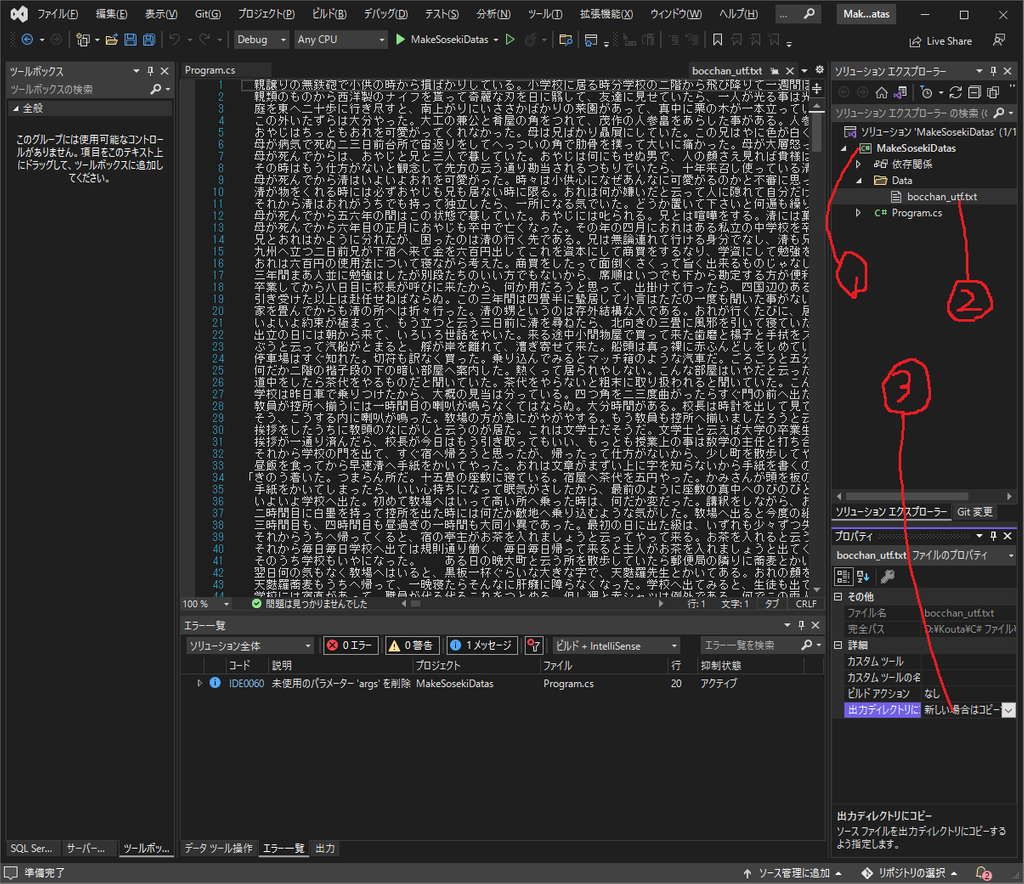
上のように行います。
- まず、「MakeSosekiDatas」を右クリックし、「追加」→「新しいフォルダ」を行い、「Data」フォルダを追加します。
- その中に、「○○_utf.txt」をコピーします。
- その後、そのファイルを選択し、「プロパティ」から「出力ディレクトリにコピー」を、「新しい場合はコピーする」に変更します。
その後、各作品について、2. および 3. を繰り返します。
それを行うことにより、データの追加は完了です。
これで準備完了です。プログラムを実行してください。
こうすると、実行ファイルと同じフォルダ(最新版なら一般に MakeSosekiDatas/bin/Debug/net10.0 です)に「Data」フォルダが追加され、その中に「traindata.csv」と「testdata.csv」が作成されます。
これが今回使うデータです。
なお、データの選択はプログラムの乱数によって適当に行っているので、人によって実行結果は異なります。
機械学習を行う
いよいよ本題です。機械学習していきましょう。
とはいえ僕もきちんと分かっているわけではないので、予防線としてML.NETのチュートリアルのページを貼っておきます。
今回は「どの作品か」を当てるものなので、この中でも「多クラス分類」が一番望ましいと考えられます。
したがってここでは、「多クラス分類」のチュートリアルに則って、プログラムを作成していきましょう。
ほとんどチュートリアルのコードそのままなので、分かりづらいところはドキュメントページをご覧ください。
プロジェクトの準備を行う
まず、プロジェクトの準備を行います。
まず、NuGetパッケージから、「Microsoft.ML」をインストールしてください。
これがないと機械学習できません。
ここで一つ重要なことです。
2026年2月現在においては、.NET 8 と .NET 10 がありますが、.NET 8 を選択してください。
なぜか .NET 10 だと同じコードベースでも性能が出ません。
原因が不明なので、もし分かる方いらっしゃったら GitHub の issue に投げていただけると助かります。
次に、データを登録します。
先ほどと同様に、以下のようにデータを登録します。
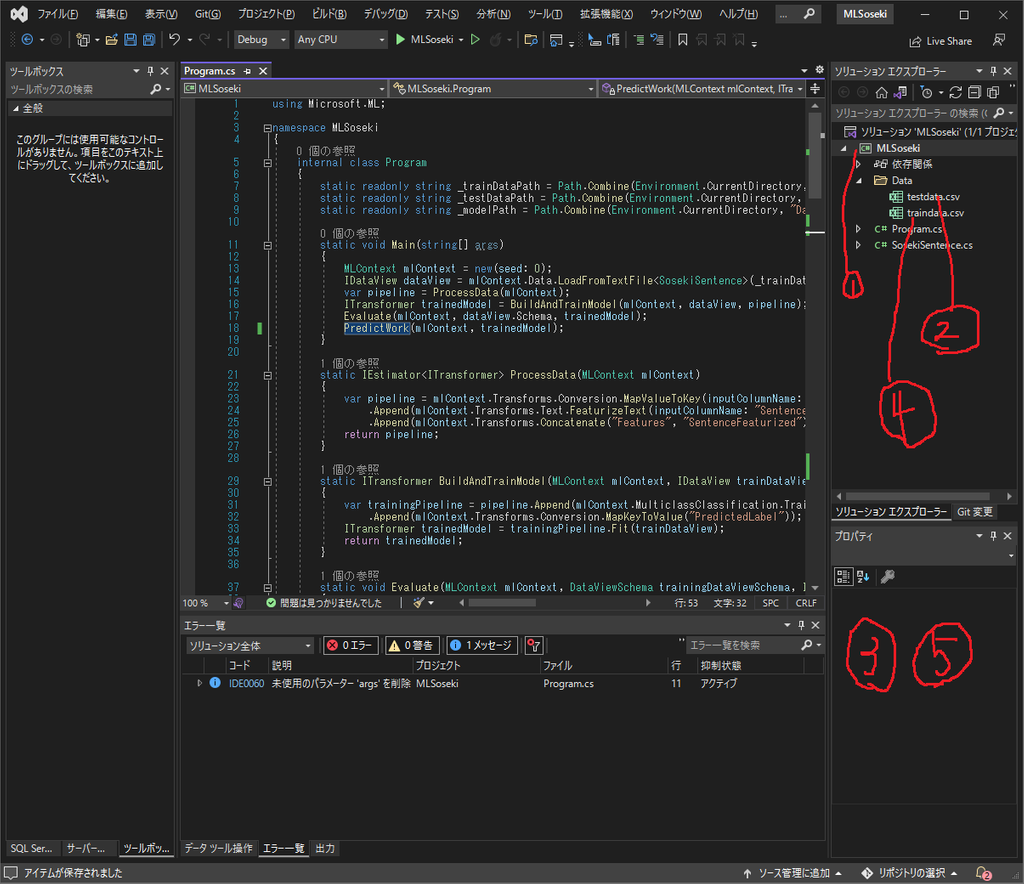
上記ではコードをすでに入力していますが、無視してください。
- 「MLSoseki」を右クリックし、「追加」→「新しいフォルダ」で、「Data」フォルダを作成します。
- testdata.csvを追加します。
- testdata.csvのプロパティにおいて、「出力ディレクトリにコピー」を、「新しい場合はコピーする」に変更します。
- traindata.csvを追加します。
- traindata.csvのプロパティにおいて、「出力ディレクトリにコピー」を、「新しい場合はコピーする」に変更します。
なお、もちろん2~3と4~5は逆でも問題ありません。
必要なクラスを作成する
次にコードを入力します。
まず、必要なクラスを作成します。
先ほどと同様に「MLSoseki」を右クリックし、「追加」→「クラス」として、ファイル名を「SosekiSentence.cs」に変更してください。
コードは以下のようにしてください。
SosekiSentence.csusing Microsoft.ML.Data;
namespace MLSoseki
{
public class SosekiSentence
{
[LoadColumn(0)]
public string Sentence { get; set; }
[LoadColumn(1)]
public float StoryID { get; set; }
}
public class SosekiPrediction
{
[ColumnName("PredictedLabel")]
public float StoryID;
}
}
Microsoft.ML.Dataを先頭に追加するのを忘れないでください。
LoadColumn()属性を付与することにより、読み込んだデータをここに登録することが出来るようです。
また、ColumnName()属性を付与し、その引数に"PredictedLabel"を与えることにより、推測を行う対象を明示することが出来るそうです。
これらについては後で使います。
なお、StoryIDのところにおいて、作品を表すインデックスを登録し、それを推測するような機械学習を行うこととします。
必要なクラス変数を定義する
では次に、Program.cs に戻り、必要な変数を定義します。
クラスのトップレベルに以下の三つの変数を定義してください。
Program.csstatic readonly string _trainDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "traindata.csv");
static readonly string _testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "testdata.csv");
static readonly string _modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "model.zip");
これで、訓練データ、テストデータとモデルのパスを定義できました。
ProcessData(MLContext) を作成する
次に、ProcessData(MLContext) という静的関数を作成します。
Program.csに戻り、以下のような関数を追加します。
Program.csusing Microsoft.ML;
namespace MLSoseki
{
internal class Program
{
static IEstimator<ITransformer> ProcessData(MLContext mlContext)
{
var pipeline = mlContext.Transforms.Conversion.MapValueToKey(inputColumnName: "StoryID", outputColumnName: "Label")
.Append(mlContext.Transforms.Text.FeaturizeText(inputColumnName: "Sentence", outputColumnName: "SentenceFeaturized"))
.Append(mlContext.Transforms.Concatenate("Features", "SentenceFeaturized"));
return pipeline;
}
}
}
一行目では、inputColumnNameのところに、予測したい値の変数名を指定し、outputColumnNameのところには"Label"を指定します。
二行目Append...のところについては、様々なオプションを付与しています。
例えばML.NETにおける機械学習においては、文字列型のデータを読み込むことは不可能とのことなので、文字列型のデータであるSentenceを数値データに変換するため、mlContext.Transforms.Text.FeaturizeText()を用いて変換しています。
これにより、Sentenceが、数値データであるSentenceFeaturizedに変換されます。
三行目Append...のところでは、
どの要素を機械学習の要素として指定するかといったところを指定します。
今回の場合、例えば読み込んだデータの中に「筆者」データがあった場合、今回は全て筆者は夏目漱石なので、機械学習の結果には影響はありませんね。
筆者だけならまだよいですが、それ以外に推測するもの(今回はどの作品であるか)と相関関係のないもの(例えばこの文の文字数など)を指定してしまった場合、モデルが関係のない値ももとに学習・推論してしまうことになる可能性があり、性能を残念なものにしてしまう可能性も考えられ面倒です。
そのため、ここでは機械学習に用いるデータ系列を指定しているわけです。
なお、第一引数には"Features"を指定することがほぼ暗黙的に決定しているようです。
第二引数以降に、必要なデータ系列を必要なだけ指定します。
ここでは数値データ"SentenceFeaturized"のみを指定します。
必要に応じて任意個指定することが出来ます。
これにより、IEstimator<ITransformer>型の変数pipelineが代入されます。
BuildAndTrainModel(MLContext, IDataView, IEstimator<ITransformer>)を作成する
次は、いよいよ与えられたデータを用いて学習する部分です。
Program.csstatic ITransformer BuildAndTrainModel(MLContext mlContext, IDataView trainDataView, IEstimator<ITransformer> pipeline)
{
var trainingPipeline = pipeline.Append(mlContext.MulticlassClassification.Trainers.SdcaMaximumEntropy("Label", "Features"))
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
ITransformer trainedModel = trainingPipeline.Fit(trainDataView);
return trainedModel;
}
基本的に先ほどのチュートリアル記事の内容に則っています。
Evaluate(MLContext, DataViewSchema, ITransformer) を作成する
ここではモデルの評価を行います。
また最後の行でモデルを保存しています。
Program.csstatic void Evaluate(MLContext mlContext, DataViewSchema trainingDataViewSchema, ITransformer trainedModel)
{
IDataView testDataView = mlContext.Data.LoadFromTextFile<SosekiSentence>(_testDataPath, hasHeader: false, separatorChar: ',');
var testMetrics = mlContext.MulticlassClassification.Evaluate(trainedModel.Transform(testDataView));
Console.WriteLine($"*************************************************************************************************************");
Console.WriteLine($"* Metrics for Multi-class Classification model - Test Data ");
Console.WriteLine($"*------------------------------------------------------------------------------------------------------------");
Console.WriteLine($"* MicroAccuracy: {testMetrics.MicroAccuracy:0.###}");
Console.WriteLine($"* MacroAccuracy: {testMetrics.MacroAccuracy:0.###}");
Console.WriteLine($"* LogLoss: {testMetrics.LogLoss:#.###}");
Console.WriteLine($"* LogLossReduction: {testMetrics.LogLossReduction:#.###}");
Console.WriteLine($"*************************************************************************************************************");
mlContext.Model.Save(trainedModel, trainingDataViewSchema, _modelPath);
}
Main() を作成する
いよいよ最後に Main() 関数を作成します。
Program.csstatic void Main(string[] args)
{
MLContext mlContext = new(seed: 0);
IDataView dataView = mlContext.Data.LoadFromTextFile<SosekiSentence>(_trainDataPath, hasHeader: false, separatorChar: ',');
var pipeline = ProcessData(mlContext);
ITransformer trainedModel = BuildAndTrainModel(mlContext, dataView, pipeline);
Evaluate(mlContext, dataView.Schema, trainedModel);
}
とはいってもこれまで書いてきた処理を最初から呼び出すだけです。
ちなみに
Program.csIDataView dataView = mlContext.Data.LoadFromTextFile<SosekiSentence>(_trainDataPath, hasHeader: false, separatorChar: ',');
はデータを読み込んでいるだけです。
Microsoft.MLに存在するIDataViewというインターフェースが、ML.NETにおけるデータの取り扱いで非常に便利なようです。
工夫すれば、ここに全てのデータを読み込ませて、訓練用とテスト用に分けることもできるようなのですが、僕はちょっと分かっていないのでドキュメントに任せることにします。
引数もそこまで面倒ではないですよね。
しかし引数の設定忘れは面倒なのでお気を付けください。
(特にseparatorCharを指定するのを忘れないでください)
実行する
この状態で、プログラムを実行してみてください。
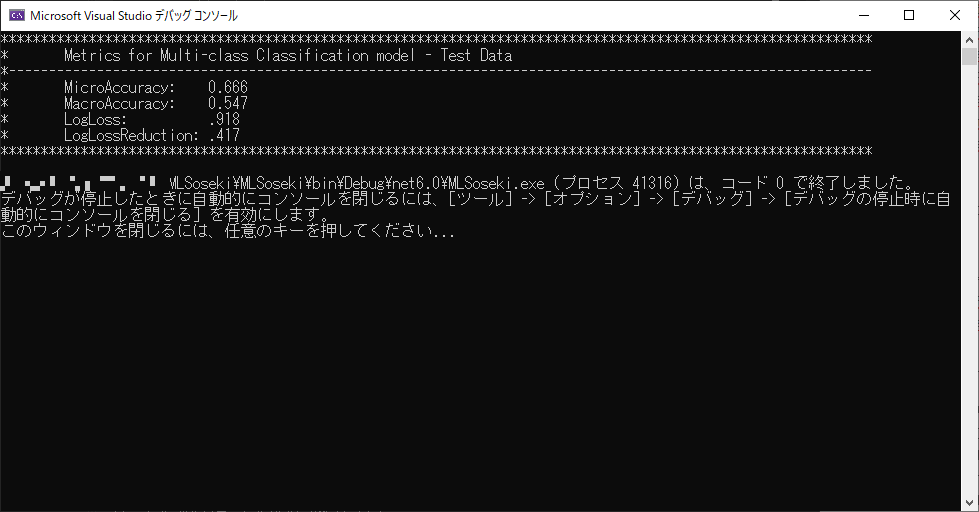
これが結果ですが、実は精度はあまり悪くありません。
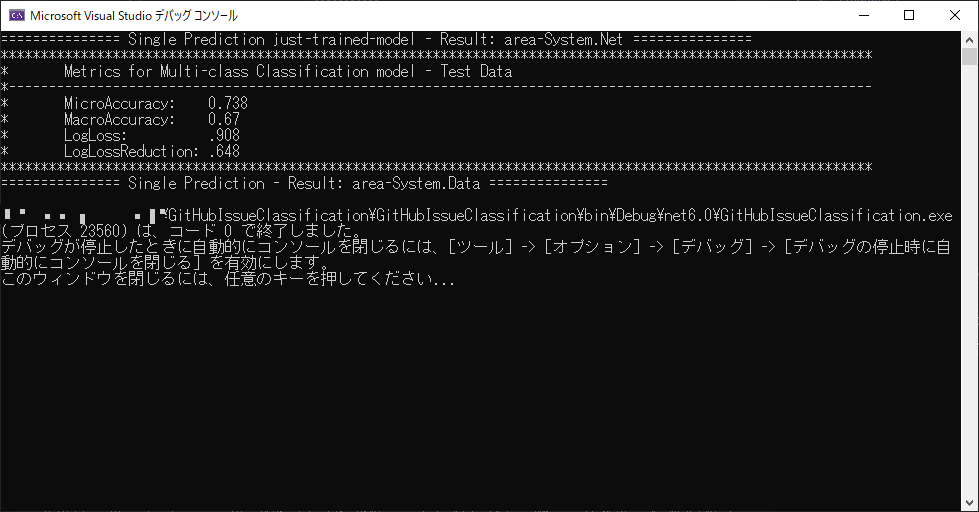
こちらがチュートリアルをそのまま実行した結果なのですが、
| 項目 | 今回 | チュートリアル |
|---|---|---|
| MicroAccuracy | 0.666 | 0.738 |
| MacroAccuracy | 0.547 | 0.67 |
| LogLoss | 0.918 | 0.908 |
| LogLossReduction | 0.417 | 0.648 |
こうやって比較してみると、割と悪くない結果を出してくれているように思うわけです。
実際に予測してもらう
ではここで、試しにいくつかの例について、実際にどの作品なのかを予測してもらいましょう。
僕が実際に生成したデータに基づくことにしますが、僕が実際に生成したtestdata.csvの中から、いくつかピックアップして実際にやってみます。
各々の作品から4つずつ文をピックアップしています。
こころ
- 先生はそれでなくても、冷たい眼で研究されるのを絶えず恐れていたのである。
- その感じが私をKの墓へ毎月行かせます。
- 私は彼の生前に雑司ヶ谷近辺をよくいっしょに散歩した事があります。
- 彼の血潮の大部分は、幸い彼の蒲団に吸収されてしまったので、畳はそれほど汚れないで済みましたから、後始末はまだ楽でした。
吾輩は猫である
- 妻君が袋戸の奥からタカジヤスターゼを出して卓の上に置くと、主人は「それは利かないから飲まん」という。
- A君は是非固形体を食うなという。
- 下女は国事の秘密でも語る時のように大得意である。
- 神楽坂の方から汽車がヒューと鳴って土手下を通り過ぎる。
三四郎
- 三四郎は富士山の事をまるで忘れていた。
- ところが広田さんはそれでやめてしまった。
- 麹町からあれを千駄木まで引いてくるのに、手間が五円ほどかかったなどと言う。
- 図書館へもはいったがやっぱり見当らなかった。
私の個人主義
- 私は今日初めてこの学習院というものの中に這入りました。
- 私は高等学校へ周旋してくれた先輩に半分承諾を与えながら、高等師範の方へも好い加減な挨拶をしてしまったので、事が変な具合にもつれてしまいました。
- その苦痛は無論鈍痛ではありましたが、年々歳々感ずる痛には相違なかったのであります。
- 世界の大勢に幾分か関係していないとも限らない。
草枕
- 越す事のならぬ世が住みにくければ、住みにくい所をどれほどか、寛容て、束の間の命を、束の間でも住みよくせねばならぬ。
- 雲雀の声を聞いたときに魂のありかが判然する。
- はっと思う間に、小女郎が、またはたと襖を立て切った。
- 「和尚さん、あなたには、御目に懸けた事があったかな」
坊っちゃん
- すると清は澄したものでお兄様はお父様が買ってお上げなさるから構いませんと云う。
- 卒業してから八日目に校長が呼びに来たから、何か用だろうと思って、出掛けて行ったら、四国辺のある中学校で数学の教師が入る。
- これも親譲りの無鉄砲が祟ったのである。
- おれは江戸っ子で華奢に小作りに出来ているから、どうも高い所へ上がっても押しが利かない。
さて、適当に選んだと見せかけて、かなりいろいろ考えました。
いくつかの基準を設けています。
- 登場人物の名称を入れてみる
- 地名を入れてみる
- あらすじによって推測できそうなものを入れる
- 逆に全く関係のなさそうなものも入れる
まず最初の「登場人物」は、かなり重要な要素ですよね。
ある登場人物がほかの作品に出てくるといえば、ダイパに出ていたポケモンがベストウィッシュの後半でも出てくるとかない限りはほぼないはずです。
次に地名ですが、夏目漱石は物語の舞台を、詳細な地名も入れながら書いている気がします。
例えば愛媛県では「坊っちゃん列車」といったものなどがあるくらいです。
次にあらすじに関係するもの、または全く関係しないものですが、僕はこの中でも「こころ」と「私の個人主義」は読んだことがあるような気がしており、「こころ」はそういう意味ではかなりきちんと選んでいます。
「私の個人主義」を選んだ理由ですが、これは他の作品と違い、どちらかと言えば評論文に近いものがあります。
そういった部分も推測できるかが見ものです。
さて、お待たせしました。コードを追加しましょう。
Program.csstatic void PredictWork(MLContext mlContext, ITransformer trainedModel)
{
SosekiSentence ss00 = new() { Sentence = "先生はそれでなくても、冷たい眼で研究されるのを絶えず恐れていたのである。" };
SosekiSentence ss01 = new() { Sentence = "その感じが私をKの墓へ毎月行かせます。" };
SosekiSentence ss02 = new() { Sentence = "私は彼の生前に雑司ヶ谷近辺をよくいっしょに散歩した事があります。" };
SosekiSentence ss03 = new() { Sentence = "彼の血潮の大部分は、幸い彼の蒲団に吸収されてしまったので、畳はそれほど汚れないで済みましたから、後始末はまだ楽でした。" };
SosekiSentence ss10 = new() { Sentence = "妻君が袋戸の奥からタカジヤスターゼを出して卓の上に置くと、主人は「それは利かないから飲まん」という。" };
SosekiSentence ss11 = new() { Sentence = "A君は是非固形体を食うなという。" };
SosekiSentence ss12 = new() { Sentence = "下女は国事の秘密でも語る時のように大得意である。" };
SosekiSentence ss13 = new() { Sentence = "神楽坂の方から汽車がヒューと鳴って土手下を通り過ぎる。" };
SosekiSentence ss20 = new() { Sentence = "三四郎は富士山の事をまるで忘れていた。" };
SosekiSentence ss21 = new() { Sentence = "ところが広田さんはそれでやめてしまった。" };
SosekiSentence ss22 = new() { Sentence = "麹町からあれを千駄木まで引いてくるのに、手間が五円ほどかかったなどと言う。" };
SosekiSentence ss23 = new() { Sentence = "図書館へもはいったがやっぱり見当らなかった。" };
SosekiSentence ss30 = new() { Sentence = "私は今日初めてこの学習院というものの中に這入りました。" };
SosekiSentence ss31 = new() { Sentence = "私は高等学校へ周旋してくれた先輩に半分承諾を与えながら、高等師範の方へも好い加減な挨拶をしてしまったので、事が変な具合にもつれてしまいました。" };
SosekiSentence ss32 = new() { Sentence = "その苦痛は無論鈍痛ではありましたが、年々歳々感ずる痛には相違なかったのであります。" };
SosekiSentence ss33 = new() { Sentence = "世界の大勢に幾分か関係していないとも限らない。" };
SosekiSentence ss40 = new() { Sentence = "越す事のならぬ世が住みにくければ、住みにくい所をどれほどか、寛容て、束の間の命を、束の間でも住みよくせねばならぬ。" };
SosekiSentence ss41 = new() { Sentence = "雲雀の声を聞いたときに魂のありかが判然する。" };
SosekiSentence ss42 = new() { Sentence = "はっと思う間に、小女郎が、またはたと襖を立て切った。" };
SosekiSentence ss43 = new() { Sentence = "「和尚さん、あなたには、御目に懸けた事があったかな」" };
SosekiSentence ss50 = new() { Sentence = "すると清は澄したものでお兄様はお父様が買ってお上げなさるから構いませんと云う。" };
SosekiSentence ss51 = new() { Sentence = "卒業してから八日目に校長が呼びに来たから、何か用だろうと思って、出掛けて行ったら、四国辺のある中学校で数学の教師が入る。" };
SosekiSentence ss52 = new() { Sentence = "これも親譲りの無鉄砲が祟ったのである。" };
SosekiSentence ss53 = new() { Sentence = "おれは江戸っ子で華奢に小作りに出来ているから、どうも高い所へ上がっても押しが利かない。" };
PredictionEngine<SosekiSentence, SosekiPrediction> predictionEngine = mlContext.Model.CreatePredictionEngine<SosekiSentence, SosekiPrediction>(trainedModel);
SosekiPrediction sp00 = predictionEngine.Predict(ss00);
SosekiPrediction sp01 = predictionEngine.Predict(ss01);
SosekiPrediction sp02 = predictionEngine.Predict(ss02);
SosekiPrediction sp03 = predictionEngine.Predict(ss03);
SosekiPrediction sp10 = predictionEngine.Predict(ss10);
SosekiPrediction sp11 = predictionEngine.Predict(ss11);
SosekiPrediction sp12 = predictionEngine.Predict(ss12);
SosekiPrediction sp13 = predictionEngine.Predict(ss13);
SosekiPrediction sp20 = predictionEngine.Predict(ss20);
SosekiPrediction sp21 = predictionEngine.Predict(ss21);
SosekiPrediction sp22 = predictionEngine.Predict(ss22);
SosekiPrediction sp23 = predictionEngine.Predict(ss23);
SosekiPrediction sp30 = predictionEngine.Predict(ss30);
SosekiPrediction sp31 = predictionEngine.Predict(ss31);
SosekiPrediction sp32 = predictionEngine.Predict(ss32);
SosekiPrediction sp33 = predictionEngine.Predict(ss33);
SosekiPrediction sp40 = predictionEngine.Predict(ss40);
SosekiPrediction sp41 = predictionEngine.Predict(ss41);
SosekiPrediction sp42 = predictionEngine.Predict(ss42);
SosekiPrediction sp43 = predictionEngine.Predict(ss43);
SosekiPrediction sp50 = predictionEngine.Predict(ss50);
SosekiPrediction sp51 = predictionEngine.Predict(ss51);
SosekiPrediction sp52 = predictionEngine.Predict(ss52);
SosekiPrediction sp53 = predictionEngine.Predict(ss53);
Console.WriteLine($"=============== Single Prediction - Sentence: {ss00.Sentence},\n Answer: {GetSentenceName(0)}, Result: {GetSentenceName(sp00.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss01.Sentence},\n Answer: {GetSentenceName(0)}, Result: {GetSentenceName(sp01.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss02.Sentence},\n Answer: {GetSentenceName(0)}, Result: {GetSentenceName(sp02.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss03.Sentence},\n Answer: {GetSentenceName(0)}, Result: {GetSentenceName(sp03.StoryID)} ===============");
Console.WriteLine();
Console.WriteLine($"=============== Single Prediction - Sentence: {ss10.Sentence},\n Answer: {GetSentenceName(1)}, Result: {GetSentenceName(sp10.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss11.Sentence},\n Answer: {GetSentenceName(1)}, Result: {GetSentenceName(sp11.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss12.Sentence},\n Answer: {GetSentenceName(1)}, Result: {GetSentenceName(sp12.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss13.Sentence},\n Answer: {GetSentenceName(1)}, Result: {GetSentenceName(sp13.StoryID)} ===============");
Console.WriteLine();
Console.WriteLine($"=============== Single Prediction - Sentence: {ss20.Sentence},\n Answer: {GetSentenceName(2)}, Result: {GetSentenceName(sp20.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss21.Sentence},\n Answer: {GetSentenceName(2)}, Result: {GetSentenceName(sp21.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss22.Sentence},\n Answer: {GetSentenceName(2)}, Result: {GetSentenceName(sp22.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss23.Sentence},\n Answer: {GetSentenceName(2)}, Result: {GetSentenceName(sp23.StoryID)} ===============");
Console.WriteLine();
Console.WriteLine($"=============== Single Prediction - Sentence: {ss30.Sentence},\n Answer: {GetSentenceName(3)}, Result: {GetSentenceName(sp30.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss31.Sentence},\n Answer: {GetSentenceName(3)}, Result: {GetSentenceName(sp31.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss32.Sentence},\n Answer: {GetSentenceName(3)}, Result: {GetSentenceName(sp32.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss33.Sentence},\n Answer: {GetSentenceName(3)}, Result: {GetSentenceName(sp33.StoryID)} ===============");
Console.WriteLine();
Console.WriteLine($"=============== Single Prediction - Sentence: {ss40.Sentence},\n Answer: {GetSentenceName(4)}, Result: {GetSentenceName(sp40.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss41.Sentence},\n Answer: {GetSentenceName(4)}, Result: {GetSentenceName(sp41.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss42.Sentence},\n Answer: {GetSentenceName(4)}, Result: {GetSentenceName(sp42.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss43.Sentence},\n Answer: {GetSentenceName(4)}, Result: {GetSentenceName(sp43.StoryID)} ===============");
Console.WriteLine();
Console.WriteLine($"=============== Single Prediction - Sentence: {ss50.Sentence},\n Answer: {GetSentenceName(5)}, Result: {GetSentenceName(sp50.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss51.Sentence},\n Answer: {GetSentenceName(5)}, Result: {GetSentenceName(sp51.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss52.Sentence},\n Answer: {GetSentenceName(5)}, Result: {GetSentenceName(sp52.StoryID)} ===============");
Console.WriteLine($"=============== Single Prediction - Sentence: {ss53.Sentence},\n Answer: {GetSentenceName(5)}, Result: {GetSentenceName(sp53.StoryID)} ===============");
}
static string GetSentenceName(float index)
{
return index switch
{
0 => "こころ",
1 => "吾輩は猫である",
2 => "三四郎",
3 => "私の個人主義",
4 => "草枕",
5 => "坊っちゃん",
_ => "",
};
}
リストにしておけばよかったと後悔したのは後の祭りです。
あと皆さまにつきましても、データを自分でコードを実行して作成した場合は、訓練用データにこれらの文章が含まれている可能性があるので、あまり当てにはならないかもしれません。
必要に応じて、GitHubから僕が作成したデータをご利用ください。
そしてこう書いたら、
Program.csstatic void Main(string[] args)
{
MLContext mlContext = new(seed: 0);
IDataView dataView = mlContext.Data.LoadFromTextFile<SosekiSentence>(_trainDataPath, hasHeader: false, separatorChar: ',');
var pipeline = ProcessData(mlContext);
ITransformer trainedModel = BuildAndTrainModel(mlContext, dataView, pipeline);
Evaluate(mlContext, dataView.Schema, trainedModel);
PredictWork(mlContext, trainedModel);
}
のように、最後にコードを追加してください。
これで実行してみましょう。
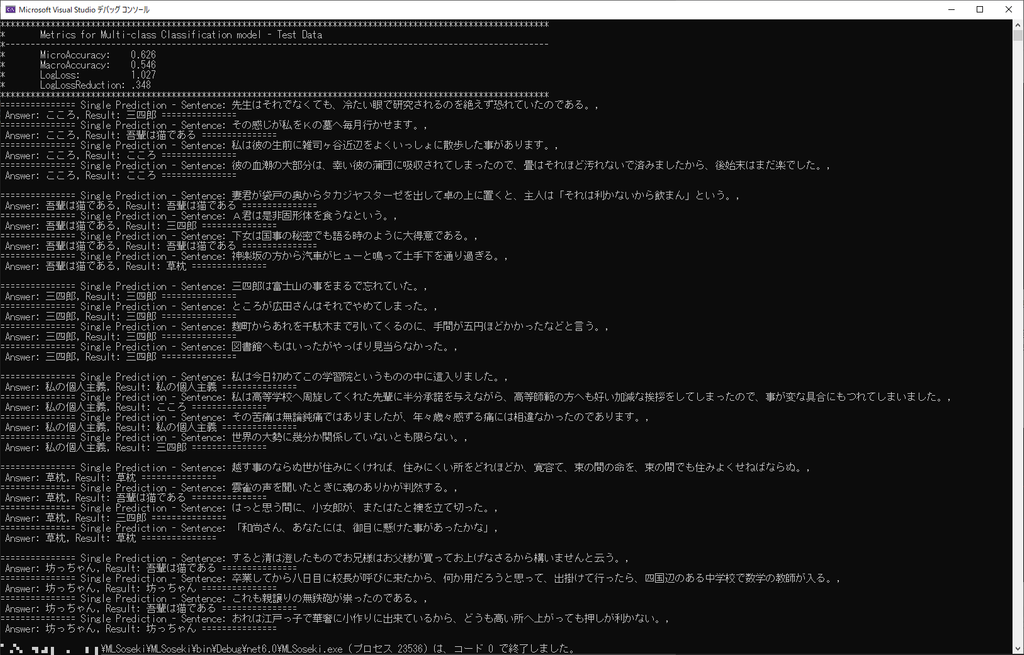
これが結果です。
三四郎については全問正解ですね。
ただ余計に三四郎と答えている部分はあるようですが……。
また、「図書館へも……」を当てるとは思いませんでした……。
「これも親譲りの……」に関しては、一行目「親譲りの無鉄砲で……」を
学習させていたので行けるかな?と思いましたが無理でした。
「その感じが私をKの墓へ……」については、「A君」に引っ張られたのでしょうか。
意外だったのは「彼の血潮の大部分は……」を当てたところですね。
うまく推測できたのでしょうか。
おわりに
これは他の作家ならどうなんだろう?とか思いました。
実際に時間があればそちらでもやってみようと思います。
また、今度は複数の作家についてこのように学習させ、
「誰が書いた一文か」というのもしてみたいとも思っています。
最後までお読みいただき、ありがとうございました。