traP部内で機械学習講習会があり、それの締めのイベントとしてコンペが開かれるということで参戦してきました。2位でとてもうれしいので参加記を書きます。
チーム
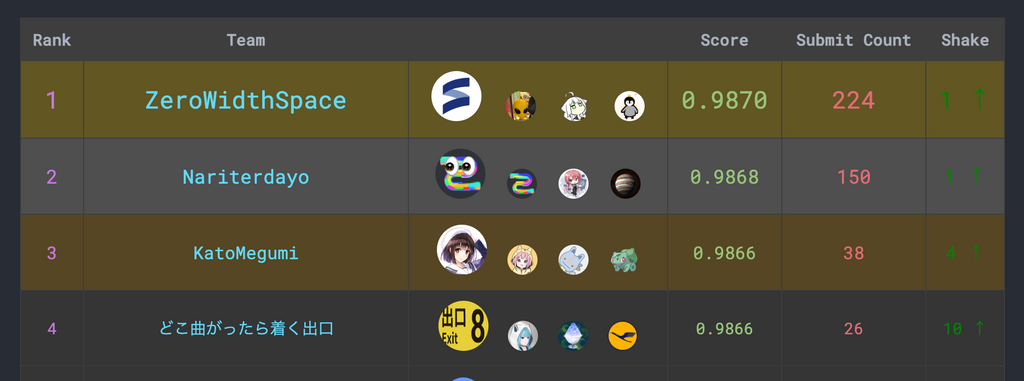
僕(@zoi_dayo)、@Naru820、@jupiter_68の3人チームで、「Nariterdayo」として参戦しました。
3人とも24Bで、競プロをやったりしています。全員機械学習はほぼやったことがなく、誰もPythonを書けませんでした...
参加前の知識
機械学習に関しては、「ゼロから作るDeep Learning」という本を少しだけ読んだことがあったので、
- パラメータを行列で変換して、たまに非線形関数を使えば多層の利点があるんだな~
- 微分して得られる方向に変化させればよさそう
- 非線形関数にはシグモイドとかReLUとかあるらしい、ReLUシンプルな見た目だけどいいのかな
- 過学習こわいな~
くらいの知識がありました。しかし、実際にコードを書いたことはなかったので、Pythonでの実装などは何もわかっていません。
コンペ
チーム内での情報やコードの共有にはDiscordを使いました。
また、環境はチームで統一はしていなかったのですが、僕はJupyter Notebookを使わずpyファイルを直接実行していました。WSL上で実行していて、なぜかWSLgがうまく動かなかったので、画像などを確認するのは少し面倒でした...
講習会の一部として、欠損値なしのデータに対して予測できるサンプルコードが提示されていたので、まずはこれをベースに改良を進めていくことにします。まずはレイヤーごとの頂点数をいじってみたりしますが、あまり変わらないです。
少し調べてみたところ、機械学習はデータ量が大切らしいので、欠損値ありの大きなデータを使うことにします。この場合、「文字列データをどう数値にするか」「欠損値をどう埋めるか」が問題となります。
はじめに、文字列データは適当に3種類くらいを0,1,2と割り当てるように変換し、欠損値については平均値で埋めたあとに、欠損していたかどうかを別の列に記録しておきました。この時点で、Public LBのスコアが0.97317くらいあります。(以下、スコアといえば基本的にPublic LBに表示されているスコアを意味します)
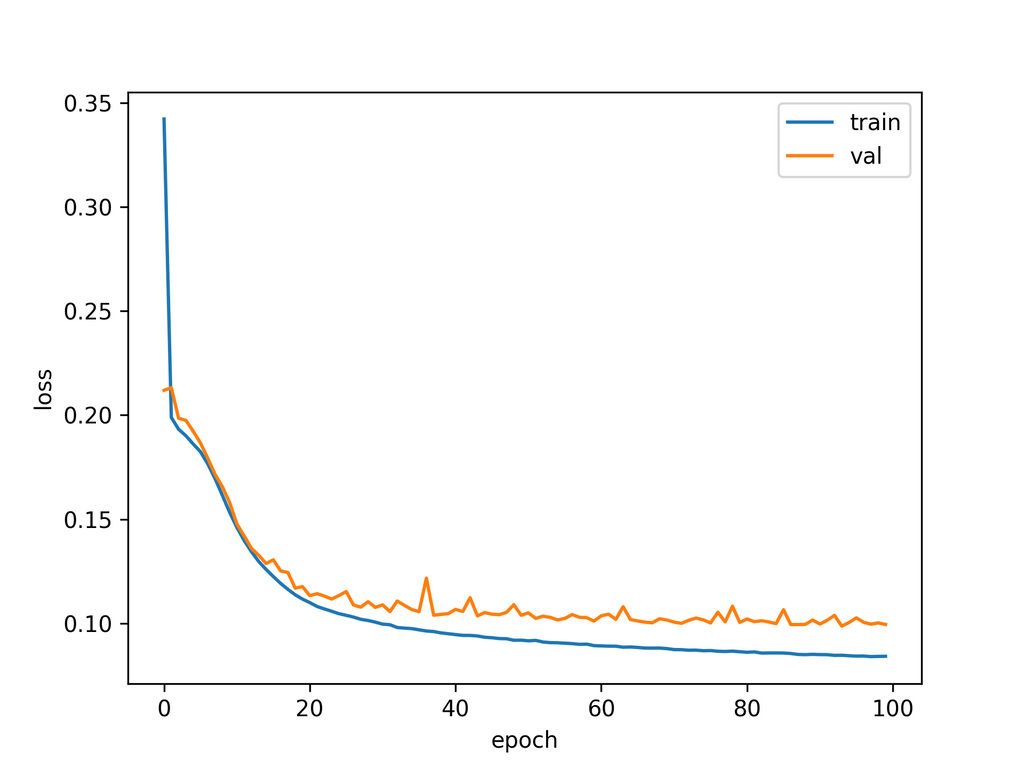
その後データを見てみると、文字列のマッピングが下手で、よくでてくるデータを変換できていない(おそらく0になっている)ことに気が付きます。そこを修正すると少しだけ上がって0.97496です。学習度合いを図示するとこんな感じ↓で、これ以上学習量を伸ばしてもあまりスコアは上がらなさそうです。
「Kaggleで勝つデータ分析の技術」という本があったので、買ってすこしだけ読んでみました。
KaggleにはTitanicという、おそらく初心者向けのコンペがあり、これが今やっている問題と同じ2値分類タスクだったので、その紹介のところを読んでみたところ、なにやら自分でネットワークを定義しているのではなく、XGBClassfierというものを使っています。
本のコードをほとんどそのまま書き写して提出してみると0.98556とめちゃくちゃいいスコアが出ます。Google検索でもXGBを使ったコードが多かったので、これを軸に進めていきます。
XGBにはパラメータがいくつかあり、これをいじると結果が変わるということで、Optunaを使ってみることにします。使い方は全然知らなかったのですが、TitanicをOptunaとXGBで解いているコードを参考にしつつ書きました。少しスコアが伸びて0.98567になります。
次に、データのパラメータを増やしてみることにします。適当にパラメータとその答えをプロットしてみて、「このパラメータがこの範囲にあればスコアが上がりそうだな」という場所があれば、それを新しい列に割り当てるようにしました。これに加え、はじめはoptunaでloglossという指標を最小化するようにしていたのですが、accuracyの最大化を試してみるとなぜかスコアが0.98598まで上がります。
検索をしているとXGBoost以外にもLightGBMというものがあるらしく、これを使ってみるとかなり精度が高いです。そのため、XGBとLGMBの結果の平均を全体の答えとすることにしました。これによって0.98651まで上がります。一部の文字列パラメータに対してOneHotEncodingをしたりしていると0.986613になります。最終的に、パラメータをいじって最高0.986718まで行きました。
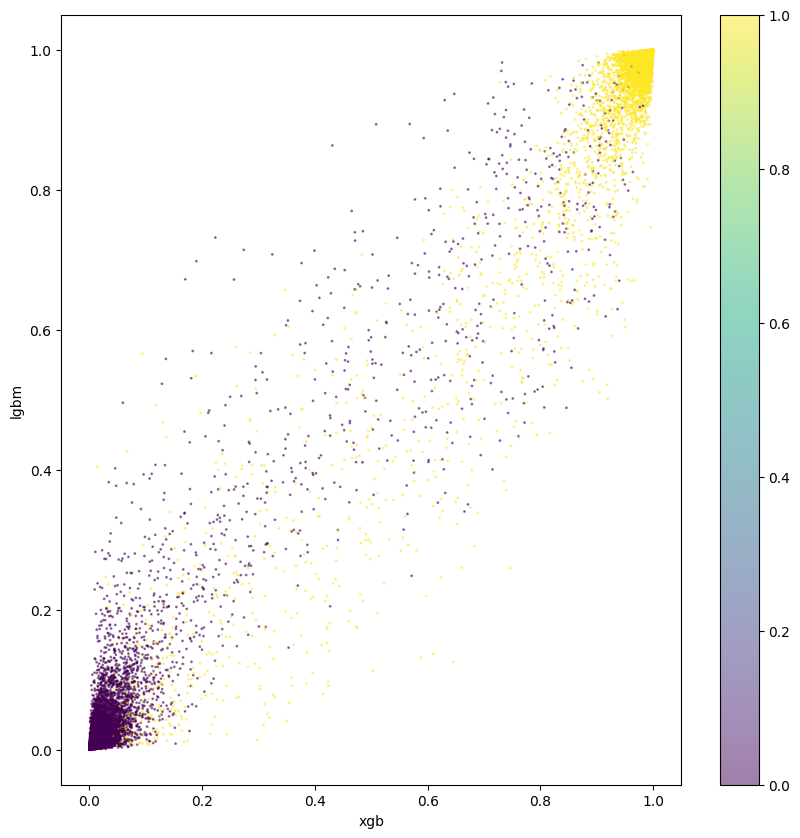
この頃には、Optunaでの学習に時間がかかる(学習→予測、を数十回行っているため)のが嫌で、パラメータは適当に手で調整しています。それぞれの予測アルゴリズムの結果をプロットした図を参考にしたりしなかったりしました。
なんかそれっぽい図です↓ (どう参考にすればいいのかはよくわかりませんでした)
最後に、「他のパラメータから欠損値を予測する」「複数の予測値からただ平均を取るのではなくちゃんと予測をする(ブレンディングというらしい?)」というのをやってみたかったので、雑にやってみました。モデルの学習部分を関数みたいにして分離していたので、それを使い回すことができて実装は結構楽でした。スコアは0.98667と少し下がりましたが、そこそこ高いスコアであり、また順位表最適化はあまりよくなさそうなので結構良さそうな感じです。
終盤は、Public LBで3~6位くらいのスコアが完全一致していたりして、実際の結果で大規模なshakeが発生するのがなんとなく予想できていたので怖かったです...スコアリプレイを見た感じ、最後に試していたもの(欠損値予測とかアンサンブルとか)のスコアが高かったようなので、最後まで試してみてよかったな〜と思いました。
スコア推移のリプレイはここから見れるらしいです↓
https://abap34.github.io/ml-lecture/supplement/scorerace.html
終盤になるにつれて、夜も絶え間なく提出が行われるようになっていておもしろいですね〜
コード
長いし不要な部分もあったりして汚いのですが、いちおうここから見れます
https://gist.github.com/ZOI-dayo/d68b32568afad2a073bd97e8cbf201bd
感想
Privateのほうのデータとの相性でかなり順位が変わると思いますが、なんとか2位になれてよかったです!
まだ機械学習の細かいところがわかってなくて、色々数字を変えて試してみて改善されてるっぽいものを選ぶ、ということしかできなかったので、これからちゃんと勉強してKaggleのコンペにも出てみたいな、と思っています。