こんいす~。 @ikura-hamuです。チーム「リアクティブ二子玉川~♪」でISUCON13に出ました。チームブログはこちら(https://trap.jp/post/2075/)
最近の若者はsshしないらしいですよ。 僕は最近のノリに乗っている若者なので、ISUCONでsshせずに作業するツール群「isu-isu-h」(いすいすえいち)を整えました。最近の若者はsshじゃなくて いすいすえいち するらしいですよ。
リポジトリ
https://github.com/reactive-futakotamagawa/isu-isu-h-13
 reactive-futakotamagawa
reactive-futakotamagawa(本当のリポジトリはIPアドレスとかいろいろ上がってるのでコピーです)
名前は競技が終わってから考えました。ISUCONで自分たちの代わりにsshしてくれるのでこの名前です。
構成
大きく分けて、手元の1コマンドで全サーバーでデプロイを行うansibleと、ブラウザで必要な情報を見るobserver(勝手に名前を付けた)に分かれています。
ansible
ansibleは、初動で必要なツールを入れるための0_init.ymlと、毎回のデプロイを行う1_deploy.ymlを作りました。典型的なnginx+MySQL+systemdのアプリであればこれらで対応できるようにし、典型でない問題が来た時には、Makefileを書いて 2_make_deploy.yml で対応できるようにしました。
initの方では、下のobserverで必要なexporterなどを入れたり、GitHubの鍵を登録したりしています。これのおかげで初動は15分ぐらいで済み、すぐに改善に入れました。
deployでは、ブランチを指定できるのが推しポイントです。nginxやMySQL、アプリの再起動やログローテーションなどを行い、ブランチやコミット名をDiscordに通知します。
ansibleを初めて書いていて、ベストプラクティスに全然従っていないので、来年までに書き直したいです。
observer
docker comoposeでいろんなコンテナをくっつけて動かしました。当日はISUCON夏祭りで頂いたさくらVPSのチケットを使っていました。
version: '3'
services:
prometheus:
image: prom/prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
restart: always
grafana:
image: grafana/grafana
ports:
- "3000:3000"
volumes:
- grafana:/var/lib/grafana
- ./grafana/datasource.yml:/etc/grafana/provisioning/datasources/datasource.yml
- ./grafana/dashboard.yml:/etc/grafana/provisioning/dashboards/dashborad.yml
- ./grafana/isucon.json:/var/lib/grafana/dashboards/isucon.json
- ./grafana/log.json:/var/lib/grafana/dashboards/log.json
environment:
- GF_INSTALL_PLUGINS=grafana-clock-panel
pprotein:
build: ./pprotein
ports:
- "9000:9000"
volumes:
- pprotein:/go/src/pprotein/data
env_file:
- ./pprotein/env.sh
adminer:
image: adminer:latest
ports:
- "8080:8080"
nginx:
image: nginx:latest
ports:
- "80:80"
volumes:
- ./nginx/virtual-host.conf:/etc/nginx/conf.d/virtual-host.conf
- ./nginx/index.html:/usr/share/nginx/html/index.html
- ./nginx/.htpasswd:/etc/nginx/.htpasswd
restart: always
loki:
image: grafana/loki:latest
ports:
- "3100:3100"
command: -config.file=/etc/loki/local-config.yaml
restart: always
#ポートフォワーディング用のコンテナ
s1:
build: ./tunnel
volumes:
- ./tunnel/config:/etc/ssh/ssh_config:ro
command: -N s1
restart: always
s2:
build: ./tunnel
volumes:
- ./tunnel/config:/etc/ssh/ssh_config:ro
command: -N s2
restart: always
s3:
build: ./tunnel
volumes:
- ./tunnel/config:/etc/ssh/ssh_config:ro
command: -N s3
restart: always
volumes:
grafana:
pprotein:
簡単に説明します。
Prometheus、Grafana、Loki
メトリクスとsystemdのログ収集に用いました。
初動のansibleでnode_exporterとsystemd_exporter、promtailをインストールします。
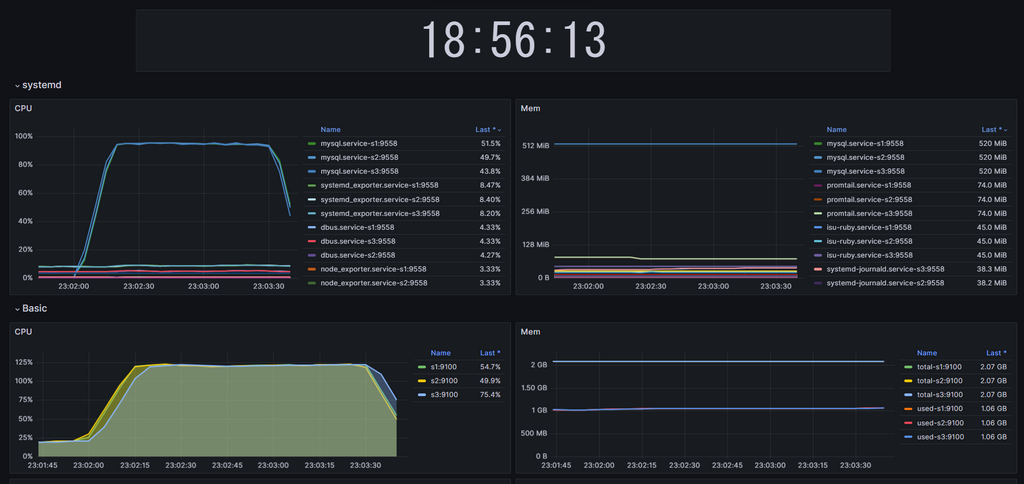
node_exporterとsystemd_exporterでCPUやメモリの使用量を取得して、Grafanaでグラフで表示しました。DBのCPU使用率が下がったなどが分かりやすくて良かったです。
promtailからLokiにsystemdのログを送信し、こちらもGrafanaで見れるようにしました。いちいちサーバーにログインせずログを見れたのはとてもよかったです。
adminer
DBをブラウザから操作できるやつです。これもサーバーにログインせずにデータベースの中身を見たりインデックスを貼ってみたりできてよかったです。
pprotein
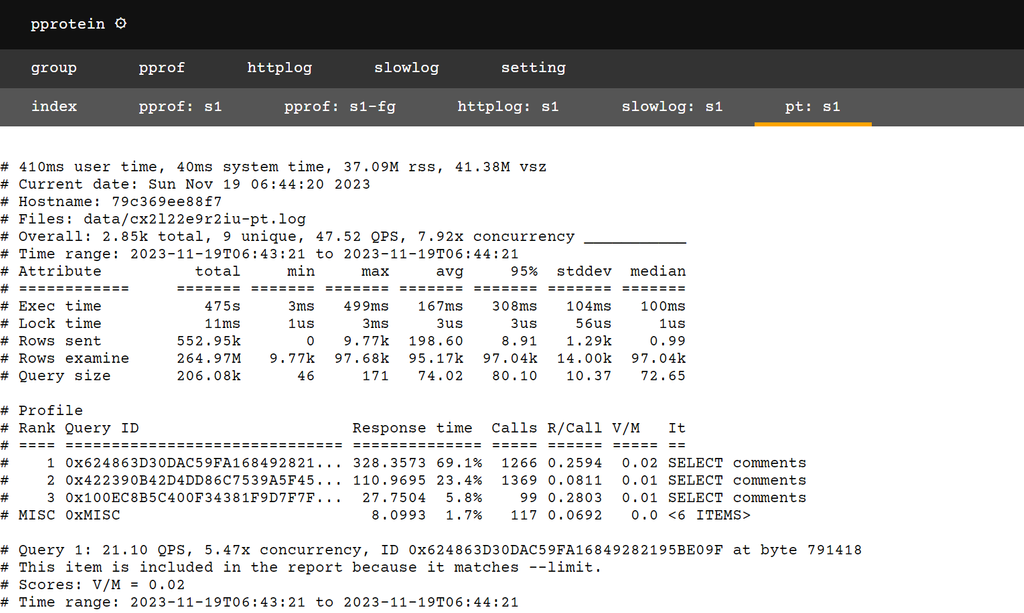
traPのOBであり、去年・今年連覇したチーム「NaruseJun」のみなさんが作ったツールです。スロークエリログ(slp)、アクセスログ(alp)、Goのプロファイラのpprofを見れて、initializeで自動で計測を始めたりしてくれるすごいツールです。チームメイトがスロークエリを見るのにpt-query-digestが欲しいと言っていたので、これをforkしてpt-query-digestの結果も見れるようにした改造版を使いました。
https://github.com/ikura-hamu/pprotein
これらのコンテナに対してnginxでプロキシを行い、サブドメインに対して振り分けることで、外部からアクセスできるようにしました。また、exporterなどのために問題サーバーのポートを開けると、整合性チェックで落とされるかもしれないと思ったので、ポートフォワーディングするためだけのコンテナを3つ(各問題サーバーに1つ)立てました。
これらのおかげで計測結果を見るのが楽になり、改善サイクルを回すスピードの上昇につながったと思います。
感想
自画自賛ですが、めっちゃよかったです。初動以外では問題にsshして中を見るということはほとんどなく、とても楽でした。チームメイトにも使ってもらえてよかったです。
ただ、長い時間使っているとよくobserverが落ちて、本番中も何度か再起動しました。ログを見ても何も出ていなくて原因はわからないままです。また、問題サーバーに入れていたツールを全部落としたら1万点ぐらい上がったので、重いのも改善したいです。
Prometheus、Grafana、Lokiは全部同じ会社が作っていて、くっつけるのも簡単でした。 (追記: prometheusは同じ会社じゃありませんでした。すみません) ただ、軽さで言うと node_exporter + systemd_exporter < netdata だったし、 promtail < fluent-bit だと思います。netdataはサーバーの環境の違いなのかわかりませんが、過去問によっては取れないメトリクスがあってやめました。fluent-bitはうまくLokiにログを送れなくて諦めました。
残り時間を表示してたところに、時間が0になったら「優勝おめでとう!!」の文字を出すように仕込んでいました。今年は優勝できなかったですが、来年以降これが現実になるよう頑張りたいです。