ブログリレー11日目はNapoliNが担当します。8月も今日でおしまいです。明日から学校の皆さん、宿題は終わりましたか?
私の地元では夏休みが10日ほど早く終わっていたので、本州の方々は羨ましいといつも思ってました。その代わり冬休みがめちゃめちゃ短いんですってね。
さて、突然ですが、皆さんは言語処理系を書けますか?マシなプログラマなら、当然書けるらしいです(TwitterXからの引用)。
わたしよりましなプログラマであればフロントエンドからコンパイラ作りまで何でもできると思っていたのですが、そういうプログラマって世間にはあんまりいないんだな…と最近知りました。
— nisizaki (@nisizaki) August 7, 2023
※単に、最初の頃に見たプログラマが優秀だっただけだった。
私はフロントエンドすらまともに書けません
というわけで今回は言語処理系入門としてインタプリタを作ってみたいと思います。
まともな言語を書くには余白と著者の能力が足りないので、非常に簡単なサンプルのみに留めます。
作りにあたり色々なサイトを調べてみたのですが、小難しいことを書いてるとこばっかりだったので、極限まで端折って「インタプリタの初歩」を説明したいと思います。
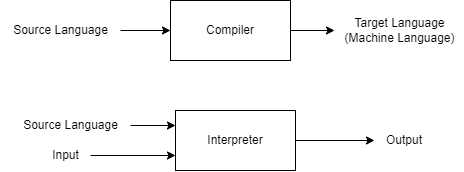
ちなみにコンパイラとインタープリタの違いは大体以下の通り。
コンパイラ=ソース言語をターゲット言語に変換するプログラム。狭義だとターゲット言語は機械語。
インタプリタ=ソース言語と入力を入力すると、対応する出力を行うプログラム
概念的には上述の通りですが、実際の言語での実装はもう少し複雑になります。例えばインタプリタ言語と言われるPythonは一度中間言語(ByteCode)にコンパイルされてそれをVM上で実行するという仕組み(のはず)です。

今回は構文木を作ってそれを評価するという素朴な実装を目指します。
構成
最も単純なインタプリタの手順を以下に示します。
- 字句解析・・・入力文字列をトークン列に分解する
- 構文解析・・・トークン列を構文木に変換する
- 構文木の評価・・・構文木の意味を評価して値に変換する
字句解析器、構文解析器はlex,yaccという便利ツールがあるのでそれを使います。自力で書こうとすると夏休みが終わりかねません。
今回作る言語は、if文とbool値しかもたない極限まで単純化した言語です。Bool言語と呼んでおきます。
言語仕様
Bool言語の文法(主要部分)は以下の通りです。BNF記法は直感的でわかりやすいです。
t := true
| false
| if t then t else t動作例はこんな感じで対話型っぽい環境を目指します。
if true then (if true then false else true) then false;
> false
true;
> true実装
実装全体はGitHubで公開しているので参照してください。
環境準備
実装はOCamlで行いました。
Syntax
構文は代数的データ型を用いて定義できます。前述のBNF記法の文法と大体同じですね。
type term =
TmTrue
| TmFalse
| TmIf of term * term * term
type command =
Eval of term字句解析・構文解析を行って、入力文字列をcommand型に分解します。
Lexer
例えば、"if true then false else true"という文字列を例にします。これがどのようなプログラムであるかを考えるとき、まず"if" "true" "then"... と、どこが「ひとかたまり」になるのかを認識する必要があります。この「ひとかたまり」のことをトークンと呼びます。単なる文字列をトークン列に変換する役割をもつのが字句解析器の役割です。
今回はocamllexという字句解析器生成器を使います。やや特殊な文法で記述することで、字句解析器を作ってくれるプログラムです。
詳しくは公式に譲りますが、ざっくりHeader、Entrypoint、Trailerの3部分に分かれます。Entrypointのみ必須。
{
exception LexError
(*reserved word*)
let reservedWords = [
("if", fun unit -> Parser.IF);
("then", fun unit -> Parser.THEN);
("else", fun unit -> Parser.ELSE);
("true", fun unit -> Parser.TRUE);
("false", fun unit -> Parser.FALSE);
("(", fun unit -> Parser.LPAREN);
(")", fun unit -> Parser.RPAREN);
(";", fun unit -> Parser.SEMI)
]
(*Support functions*)
type buildfun = unit -> Parser.token
let (symbolTable : (string, buildfun) Hashtbl.t) = Hashtbl.create 1024
let _ =
List.iter (fun (str,f) -> Hashtbl.add symbolTable str f) reservedWords
let createID str =
try (
Hashtbl.find symbolTable str
) ()
with Not_found -> raise LexError
let create stream =
Lexing.from_channel stream
let text = Lexing.lexeme
}
(* Rules *)
rule main = parse
[' ' '\t']+
{main lexbuf} (* skip space *)
| [ '\n'] | eof
{ Parser.EOF }
| ['a'-'z']+
{ createID (text lexbuf) } (* reserved keywords *)
| ['(' ')' ';']
{ createID (text lexbuf) } (* reserved keywords *)Trailerが無く、rule main以前がheader、以降がentrypointです。
entrypoint 文字列 でトークン化された列(Parser.token型)が取れます。
Header
ヘッダでは字句解析のとき使う関数や、外部から呼び出せる補助関数を定義できます。なお、生成される字句解析器においてHeader部分はそのままコピペされます(Trailerも)。
最初は予約語を定義します。
(*reserved word*)
let reservedWords = [
("if", fun unit -> Parser.IF);
("then", fun unit -> Parser.THEN);
("else", fun unit -> Parser.ELSE);
("true", fun unit -> Parser.TRUE);
("false", fun unit -> Parser.FALSE);
("(", fun unit -> Parser.LPAREN);
(")", fun unit -> Parser.RPAREN);
(";", fun unit -> Parser.SEMI)
]今後拡張しやすいようにトークン側は関数でラップしてます。
(*Support functions*)
type buildfun = unit -> Parser.token
let (symbolTable : (string, buildfun) Hashtbl.t) = Hashtbl.create 1024
let _ =
List.iter (fun (str,f) -> Hashtbl.add symbolTable str f) reservedWords
let createID str =
try (
Hashtbl.find symbolTable str
) ()
with Not_found -> raise LexErrorreservedWordsをハッシュテーブルにし、 createIDで検索できるようにします。予約語に一致しなかった場合 LexError例外を投げます。本来ここでは変数のid生成をやるべきですが、言語仕様に変数を導入していないので例外を投げることにしました。
Rules
字句解析の主要な部分で、正規表現を利用してトークン分解の手続きを定めます。
スペース・タブのスキップ
[' ' '\t']+
{main lexbuf}
1行目がマッチングルール、2行目がマッチしたときのアクションです。スペースやタブはトークン化せず単に無視してほしいです。このように書くことでルールを再帰的に呼びだすことができます。
入力終端
| [ '\n'] | eof
{ Parser.EOF }
改行までを1つの入力とみなします。
予約語
| ['a'-'z']+
{ createID (text lexbuf) } (* reserved keywords *)
| ['(' ')' ';']
{ createID (text lexbuf) } (* reserved keywords*)text lexbufでマッチした文字列を取ります。それに対してcreateIDを適用することで、対応するトークンを生成します。括弧、セミコロンを除くと予約語はすべて英小文字なので、英小文字だけをマッチング対称にしてます。
Parser
Lexerによってプログラムを表す文字列はトークンの列に変換することができました。これにより、先ほどの例"if true then false else true"は[IF, TRUE, THEN, FALSE, ELSE, TRUE]のようなトークン列に分解することができます。
例えば、IF、THEN、ELSEはセットとなるトークンですが、「このIFと組になるTHEN、ELSEはどれだろうか?」といった問題が生じます。この問題を解決してくれるのがパーサです。
パーサはトークン列を木構造に変換します。例えば上の例は次のような木構造に変換されます。
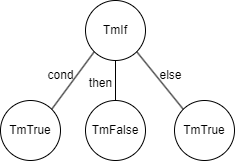
このように変形することで、ネストを含む複雑な式も表現できます。
例えば、 if true then ( if false then true else false ) else trueは次のような構文木に変換できます。
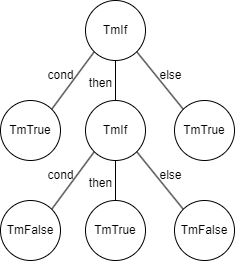
パーサを作るために、今回は構文解析器生成器ocamlyaccを使います。ocamllexと同じく、特殊な文法で構文解析器を作ってくれる優れものです。
%{
open Syntax
%}
/* keyword */
%token IF
%token THEN
%token ELSE
%token TRUE
%token FALSE
%token LPAREN
%token RPAREN
%token SEMI
%token EOF
%start toplevel
%type < Syntax.command list> toplevel
%%
toplevel :
EOF {[]}
| Command SEMI toplevel
{ $1 :: $3}
Command :
Term { (Eval($1)) }
Term :
TRUE { TmTrue }
| FALSE { TmFalse }
| IF Term THEN Term ELSE Term {TmIf($2,$4,$6)}
| LPAREN Term RPAREN { $2 }ocamlyaccも構造はocamllexと同じですが、HeaderとRulesの間にDeclarationセクションがあります(token…の部分)。
Declaration
/* keyword */
%token IF
%token THEN
%token ELSE
%token TRUE
%token FALSE
%token LPAREN
%token RPAREN
%token SEMI
%token EOF終端シンボル=トークン(要は定数)を宣言します。Lexerで使っていたトークンはここで定義されていたのでした。
%start toplevel
%type < Syntax.command list> topleveltoplevel(後述)が構文解析のエントリポイントであることを宣言します。このとき、toplevelがどのような型になるかを指定する必要があります。ここではcommand型のリストになります。
Rules
toplevel :
EOF {[]}
| Command SEMI toplevel
{ $1 :: $3}toplevelはパーサのエントリポイントとして定義していました。セミコロンまでを1つのcommandとみなし、残り部分を再帰的にパースします。
curly braces内はマッチしたときに行うアクションです。$NでN番目のシンボルに対応する要素を取得できます。1番目のシンボルと3番目のシンボルをくっつけたものを返してください、の意味です。
要するにcommand1; command2; command3;......;の形を受け入れ、結果はCommandのリストになります。
Command :
Term { (Eval($1)) }現状CommandはTermしかないので、EvalでTermをラップするだけです。
Term :
TRUE { TmTrue }
| FALSE { TmFalse }
| IF Term THEN Term ELSE Term {TmIf($2,$4,$6)}
| LPAREN Term RPAREN { $2 }ここが構文木の生成に直結する部分です。
最後は括弧の除去部分です。可読性のために括弧書きを許容していました。
Termは非終端シンボルなので、再帰的に分解されます。
評価器
構文木を評価するプログラムです。インタープリタのコア部分になります。
let rec eval1 t = match t with
TmIf(TmTrue, t2, t3) -> t2
|TmIf(TmFalse, t2, t3) -> t3
|TmIf(t1, t2, t3) -> let t1' = eval1 t1 in TmIf(t1', t2, t3)
|_ -> raise NoRuleApplies
let rec eval t =
try let t' = eval1 t
in eval t'
with NoRuleApplies -> teval1は評価を1stepだけ進めるモジュールで、以下の評価規則をプログラムに落とし込んだ形です。

eval
お気持ち的には条件部分をtrue/falseになるまで評価して、その真偽に応じてthen/elseの評価に移る、という処理を書いてます。
main.ml
必要なモジュールはすべて完成したので、組み合わせてインタプリタを動かします。
open Support.Error
open Syntax
open Format
open Core
let parse_line lexbuf =
let result = try Parser.toplevel Lexer.main lexbuf
with Parsing.Parse_error -> err "Parse Error"
in Parsing.clear_parser(); result
let process_command cmd = match cmd with
| Eval(t) ->
let t' = eval t in Syntax.printtm t'
let process_interpret () =
let lexbuf = Lexer.create stdin in
let rec process_line () =
let cmds = parse_line lexbuf in
let g cmd =
print_string "> ";
process_command cmd;
print_newline()
in List.iter g cmds; process_line();
in process_line ()
let () =
process_interpret()parse_lineは lexbuf(stream)から1行入力を受け取りパースした結果を返すモジュール
process_commandはcommandを評価器で解釈し、結果を出力するモジュール
process_interpretは標準入力をストリームにつなぎ、入力を処理するモジュール
です。
ファイルをそれぞれコンパイル(MakeFile参照)すればBool言語のインタープリタの完成です。
与太話
関数型言語の特徴としてifも評価値をもちます。そのためif式の条件部分にif式を書くみたいな芸当も許されます(読みにくい)。
if (if true then true else true) then true else true;
> true拡張
今回の実装はTaPLのコードを参考(必要な部分を抜粋)しながら書いています。
いかがでしたか?実は初めて技術的な記事を書きました。
明日のブログリレーは@kokuwa_ppさんの「四則演算で10を作る(テンパズル)」です。楽しみ~