この記事は新歓ブログリレー2020 37日目の記事です。
こんにちは。algorithm班のidatenです。普段は、競技プログラミングをしています。今回は、競技プログラミングで使う際に、Rolling Hashというアルゴリズムの衝突の話と、基数にランダムな原始根を使ってみるという話をしようと思います。
Rolling Hashとは
文字列(もしくは数列)をHash値に変換することで、文字列同士の比較をですることができるようになります。これによって、文字列の検索や比較が高速に行うことができます。
詳しくは、蟻本p.332かラビンカープ法のおはなし+二次元のロリハいいぞの1,2,3章を参照してください。
Hashの衝突
以下ではRolling Hashで使う素数を、基数をとします。
Hash値を用いて文字列を比較する場合、「Hash値が等しいならば、下の文字列も等しい」という前提を置いていますが、実際は成り立ちません。異なる文字列であるが、同じHash値となってしまうことをHashの衝突といいます。
しかし、実際には高い確率で判定できることと高速に動作することから、プログラミングコンテストにおいてよく使われています。
素数を用いた際のHashの衝突確率についてもう少し詳しく見てみます。
まず、二つ文字列を比較する場合と文字列の種類数を求める場合に大別できて、
- 二つの文字列の比較の場合
比較を1回行う際に衝突する確率は大体なので、回比較するとすると、となり、程度のとき
となり、これは実用上ほぼ問題ない値です。
ただし、これはケースが作為的に選ばれた場合は成り立ちません。後述のようにやを固定すると、わざと衝突させることができるようです。
- 文字列の種類数を求める場合
これはいわゆる誕生日のパラドックスというもので、1つでも衝突したら種類数が正しく求まらなくなるので感覚よりもずっと高い確率で衝突します。個の異なる文字列のHash値を求めるとして、それぞれの1つ同士の衝突確立が大体です。このとき、個のHash値全てが異なる確率は、(0-indexで)個目から考えると個目が個目と異なるHash値である確率はであるから
となります。程度のとき、であり[1]、衝突確率とほぼほぼ衝突するということがわかります。
詳しく知りたい方は、
を参照してください。
こうしてみると、二つの文字列の比較の場合は安全そうですが、種類数の場合は結構危うそうです。
そのため、やの取り方を工夫して、衝突確率を下げる工夫がなされていることもあります。
例えば、
- もしくはを複数用意してhash値が全ての場合で、一致しているかみる
- を大きくしてを小さくする
などがあります。
また、今回の主題に関わってくることですが、比較を1回行う際に衝突する確率は大体としましたが、これは後述の通り、の値によって変わり、その際にがの原始根であった場合、衝突確率はとなりますが、そうでない場合、衝突確率は上がります。
原始根とは
原始根を次のように定義します。
(以上の)素数と以上未満の整数が以下の性質を満たす時を法に対する原始根と呼ぶ。
「のいずれもがで割ってあまりでない」
(また、はに対する原始根である, とする)
例えば、法がの場合の値の表は以下の通りです。この表より、が原始根であることがわかります。
| r\i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 2 | 2 | 4 | 8 | 3 | 6 | 12 | 11 | 9 | 5 | 10 | 7 | 1 |
| 3 | 3 | 9 | 1 | 3 | 9 | 1 | 3 | 9 | 1 | 3 | 9 | 1 |
| 4 | 4 | 3 | 12 | 9 | 10 | 1 | 4 | 3 | 12 | 9 | 10 | 1 |
| 5 | 5 | 12 | 8 | 1 | 5 | 12 | 8 | 1 | 5 | 12 | 8 | 1 |
| 6 | 6 | 10 | 8 | 9 | 2 | 12 | 7 | 3 | 5 | 4 | 11 | 1 |
| 7 | 7 | 10 | 5 | 9 | 11 | 12 | 6 | 3 | 8 | 4 | 2 | 1 |
| 8 | 8 | 12 | 5 | 1 | 8 | 12 | 5 | 1 | 8 | 12 | 5 | 1 |
| 9 | 9 | 3 | 1 | 9 | 3 | 1 | 9 | 3 | 1 | 9 | 3 | 1 |
| 10 | 10 | 9 | 12 | 3 | 4 | 1 | 10 | 9 | 12 | 3 | 4 | 1 |
| 11 | 11 | 4 | 5 | 3 | 7 | 12 | 2 | 9 | 8 | 10 | 6 | 1 |
| 12 | 12 | 1 | 12 | 1 | 12 | 1 | 12 | 1 | 12 | 1 | 12 | 1 |
また、周期がそれぞれの約数であるのいずれかであることが見て取れます。
このように、がの原始根でない場合、が同じ値であるが存在し、原始根の場合は、はにおいて一意的(重複が存在しない)です。そこで、をの原始根にすることで、衝突の確率を下げよういうのが狙いです。
素数の決め方
今回の主題ではないですが、の決め方と両立できるので軽く書きました。
なるべく大きくしたいという点と計算のしやすさからは付近の素数、もしくは安全で爆速なRollingHashの話 - Qiitaのようにを使うことが多いです。
このを使う話は、かなり強力なので是非読んでみてください。
基数の決め方
今回はの決め方について、書いてみようと思います。多くの場合、は乱数で生成します。固定値だとコンテスタントがhackできるタイプのコンテストで衝突するケースを生成することができるそうです。
参考:Rolling Hashを殺す話 | SlideShare
しかし、単純な乱数生成では、運が悪いとすぐ衝突するような良くない乱数が生成されてしまうかもしれません。
そこで、の値として原始根をランダムに生成することで、安全かつhackされにくくします。
奇素数の原始根
ここからが主題です。長くなってすみません。
整数をで割った余りの集合を剰余類と呼びと表します。剰余類の内、と互いに素なものの集合をと表します。
原始根の性質
ここで、素数の原始根が一つ分かっているとします。
このとき、次が成り立ちます。
- がの原始根 とが互いに素
1の証明は原始根の定義と具体例(高校生向け) - 高校数学の美しい物語
の原始根の重要な定理を参照してください。
2の証明は流れを書くと、1のをに置き換えるとそれぞれになることと、Fermatの小定理からであるので、指数の肩は上の演算と考えることができることから導けます。
上の議論より、素数の原始根が1つわかっていれば、と互いに素な自然数をランダムに生成してRolling Hashの基数をとすればいいことがわかります。それでは、自然数を見つけるのにどれくらい時間がかかるのでしょうか。
ここでは、自然数を以下とします。以上以下でと互いに素な自然数の個数は、オイラーの関数を用いて、個であるので、がと互いに素な確率は、です。
代表的な素数の値を載せておきます。
- ,
- ,
実際に自分が使う素数の値を求めてみるといいと思いますが、上記の素数を使う場合と互いに素な自然数を乱数で見つける期待値は、実用的に定数回と言っていいレベルです。
以上より原始根があらかじめ一つ分かっていれば(とします)、ランダムに原始根を実行時に生成することができます。
次の手順です。
- 自然数の乱数を発生させる。
- とが互いに素であるか確認する。互いに素でないなら1.に戻る。
- であることを確認する。そうでないなら1.に戻る。
- に設定する。
追記:ただし、数列の最大値をとして、の時、次の2つの数列が衝突してしまいます。
そのため、である必要があります。そこで上記手順に3を足しました。
ただ、一般にであるため、「がと互いに素」かつ「」である確率はほぼ上記と同じでしょう。
原始根を一つ求める
原始根を一つ求めてみます。基数を実行時に決定するため、素数を実行時に決定するのはあまりうまみがないので、素数を定数とします。
すると、コンテストの前にプログラムを動かして自分のRolling Hashでつかう素数に対して一つ求まっていればいいです。
例として、の原始根を求めてみます。
原始根の求め方ですが、一つの方法としてから順に、乗から乗してになるかどうかを確かめるという方法がありますが、判定でかかるので現実的ではありません。
そこで、次の事実を利用します。においてとなるようなが存在するとき、はの約数に限る。
これは、Fermatの小定理から導けます。
これを利用して、
を素因数分解すると
となるので、の約数の個数をとして、個調べればいいことがわかります。
また、原始根の性質2. より、原始根の数はと等しいので、原始根が見つかるまでの期待計算量は、判定にかかるのでとなります。
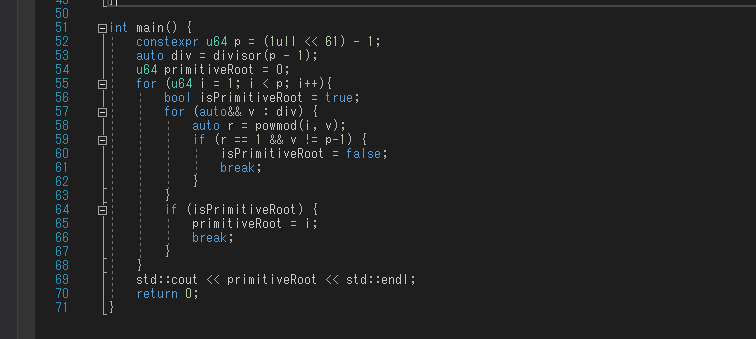
原始根を求めるコードをC++で実装しました。以下がそのソースコードです。原始根はたいていすぐ見つかるので素因数分解がボトルネックでだと思います。(なのでオーバーフローを回避するためにmul関数が特殊です。ならコメントアウトしたほうのmulが使えます)
※(2021/9/1 コメントで指摘があった通り,コードが間違っていたため修正しました.)
#include <iostream>
#include <vector>
using u64 = uint64_t;
template<typename T>
std::vector<T> divisor(T n) {
std::vector<T> res1;
std::vector<T> res2;
for (T i = 1; i * i <= n; i++) {
if (n % i == 0) {
res1.push_back(i);
if (i != n / i) {
res2.push_back(n / i);
}
}
}
for (u64 i = res2.size(); i >0; --i){
res1.push_back(res2[i - 1]);
}
return res1;
}
//*
u64 mul(u64 a, u64 b) { // a*b mod 2^61-1
constexpr u64 p = (1ull << 61) - 1;
const u64 m30 = (1ull << 30) - 1;
const u64 m31 = (1ull << 31) - 1;
u64 au = a >> 31;
u64 ad = a & m31;
u64 bu = b >> 31;
u64 bd = b & m31;
u64 mid = ad * bu + au * bd;
u64 midu = mid >> 30;
u64 midd = mid & m30;
u64 res = ((au * bu * 2) % p + midu + (midd << 31) % p + (ad * bd) % p) % p;
return res;
}
/*/
//*
constexpr u64 p = 998244353;
u64 mul(u64 a, u64 b) {
return ((a % p) * (b % p)) % p;
}
//*/
u64 powmod(u64 base, u64 exp) { // base^exp mod MOD
if (exp == 0) {
return 1;
} else if (exp % 2 == 0) {
u64 t = powmod(base, exp / 2);
return mul(t, t);
} else {
return mul(base, powmod(base, exp - 1));
}
}
int main() {
constexpr u64 p = (1ull << 61) - 1;
auto div = divisor(p - 1);
u64 primitiveRoot = 0;
for (u64 i = 1; i < p; i++){
bool isPrimitiveRoot = true;
for (auto&& v : div) {
auto r = powmod(i, v);
if (r == 1 && v != p-1) {
isPrimitiveRoot = false;
break;
}
}
if (isPrimitiveRoot) {
primitiveRoot = i;
break;
}
}
std::cout << primitiveRoot << std::endl;
return 0;
}
実行結果より、の原始根の一つはであることがわかります。
まとめ
記事の内容をまとめると次の通りです。
- 素数は計算の都合が許す限り大きい方がいい
- 基数は固定しない方がよく、原始根の方が安心
- 原始根でも数列の要素の最大値より小さいと自明な衝突があるので駄目
- 原始根のランダムな取り方は次の手順
- 素数を決める
- 素数に対し、原始根を一つ求める(ここまでは事前準備)
- 実行時に、と互いに素かつな整数を一つ求める。(文字列(数列)をとします。)
- 基数をとして定める
参考文献
- maspyさん [AtCoder 参加感想] 2019/09/14:ABC 141
- tsujimotterさん 原始根の数のかぞえかた
すでにこのページでリンクを貼っているサイトは省略させていただきました。
おわりに
今回はRolling Hashのアルゴリズムで基数をランダムな原始根にする方法を解説しました。間違いなどありましたら、気軽にご指摘ください。
明日の担当者は@kano @Kejunです。おたのしみに。
[1]
を求める問題は、つい最近のABC156 D - Bouquetでほぼ同じ問題がでましたね。